[Most Recent Entries] [Calendar View]
Monday, December 21st, 2015
| Time | Event |
| 8:00a | Dell Issues Patch For Content Adaptive Brightness Control On The XPS 13
The XPS 13 was one of the best laptops of the year, but it did have some issues, as all devices do. One that was very frustrating to deal with during the review was the aggressive Content Adaptive Brightness Control (CABC) which was enabled by default, with no way to disable it. CABC is a common method of saving power, since the backlight can be lowered depending on what content is on the display. Unfortunately, it was so aggressive that trying to accurately establish battery life was difficult, since we set the displays to 200 nits. With the CABC, brightness would vary quite substantially just with webpages flashing onto the screen. It was also an issue when trying to calibrate the display. The calibration software first sets a baseline brightness on white (200 nits again is what we use) and then flashes various shades of gray and color to create a profile for the display. Once again, the CABC would get in the way, changing the brightness that the software was expecting. I think for most people, it would be something that they would notice, but not something that would bother them too much, unless you were doing certain tasks where it would kick in. I am all for power saving features, but anytime you add something like this, you need to have a way to disable it for customers who don’t want it. Luckily Dell is now offering a patch to disable this feature. At the moment, the only way to get the patch is to contact Dell support. It would be nice if they would just offer it as a link to download, but for the moment this is what we have. Being able to remove the aggressive CABC fixes one of my biggest issues with the XPS 13, and it was already one of the best laptops of the year. With this fix, it moves up a bit more. Source: Dell |
| 8:00a | The Angelbird Wings PX1 M.2 Adapter Review: Do M.2 SSDs Need Heatsinks? The M.2 form factor has quickly established itself as the most popular choice for PCIe SSDs in the consumer space. The small size easily fits in to most laptop designs, and the ability to provide up to four lanes of PCI Express accommodates even the fastest SSDs. By comparison, SATA Express never caught on and never will due to its two-lane limitation. And the more recent U.2 (formerly SFF-8639) does have traction, but has seen little adoption in the client market. Meanwhile, although M.2 has its perks it also has its disadvantages, often as a consequence of space. The limited PCB area of M.2 can constrain capacity: Samsung's single-sided 950 Pro is only available in 256GB or 512GB capacities while the 2.5" SATA 850 Pro is available in up to 2TB. And for Intel, the controller used in their SSD 750 is outright too large for M.2, as it's wider than the most common M.2 form factor (22mm by 80mm). Finally and most recently, as drive makers have done more to take advantage of the bandwidth offered by PCIe, a different sort of space limitation has come to the fore: heat. When testing the Samsung SM951 we found that our heavier sustained I/O tests could trigger thermal throttling that would periodically restrict the drive's performance. We also had a brief opportunity to run some of our tests on the SM951 using the heatsink from Plextor's M6e Black Edition. We found that extra cooling made noticeable differences in performance on some of our synthetic benchmarks, but our more realistic AnandTech Storage Bench tests showed little or no change. But other than the quick look at the SM951, we haven't had the chance to do a thorough comparison of how cooling affects high-performance M.2 drives, until now. |
| 2:00p | Host-Independent PCIe Compute: Where We're Going, We Don't Need Nodes
The typical view of a cluster or supercomputer that uses a GPU, an FPGA or a Xeon Phi type device is that each node in the system requires one host or CPU to communicate through the PCIe root complex to 1-4 coprocessors. In some circumstances, the CPU/host model adds complexity, when all you really need is more coprocessors. This is where host-independent compute comes in. The CPU handles the networking transfer and when combined with the south bridge, manages the IO and other features. Some orientations allow the coprocessors to talk directly with each other, and the CPU part allows large datasets to be held in local host DRAM. However for some compute workloads, all you need is more coprocessor cards. Storage and memory might be decentralized, and adding in hosts creates cost and complexity - a host that seamlessly has access to 20 coprocessors is easier to handle than 20 hosts with one each. This is the goal of EXTOLL as part of the DEEP (Dynamical Exascale Entry Platform) Project.
At SuperComputing 15, one of the academic posters on display from Sarah Neuwirth and her team from the University of Heidelberg was around developing the hardware and software stacks to allow for host-independent PCIe coprocessors through a custom fabric. This is theory would allow for compute nodes in a cluster to be split specifically into CPU and PCIe compute nodes, depending on the need of the simulation, but also allows for fail over or multiple user access. All of this is developed through their EXTOLL network interface chip, which has subsequently been spun out into a commercial entity. A side note - In academia, it is common enough that the best ideas, if they're not locked down by funding terms and conditions, are spun out into commercial enterprises. With enough university or venture capital in exchange for a percentage of ownership, an academic team can hire external experts to make their ideas a commercial product. These ideas either work and fail, or sometimes the intellectual property is sold up the chain to a tech industry giant. The concept of EXTOLL is to act as a mini-host to initialize the coprocessor but also handles the routing and memory address translation such that it is transparent to all parties involved. On a coprocessor with EXTOLL equipped, it can be connected into a fabric of other compute, storage and host nodes and yet be accessible to all. Multiple hosts can connect into the fabric, and coprocessors in the fabric can communicate directly to each other without the need to move out to a host. This is all controlled via MPI command extensions for which the interface is optimised.
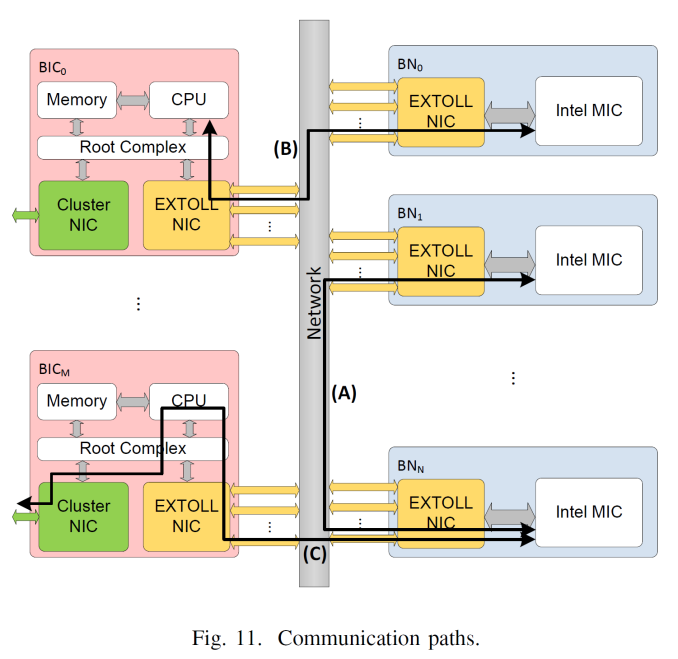
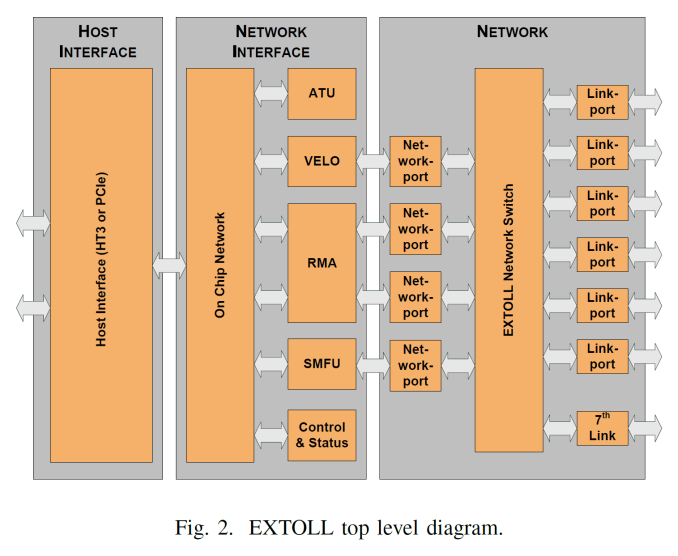
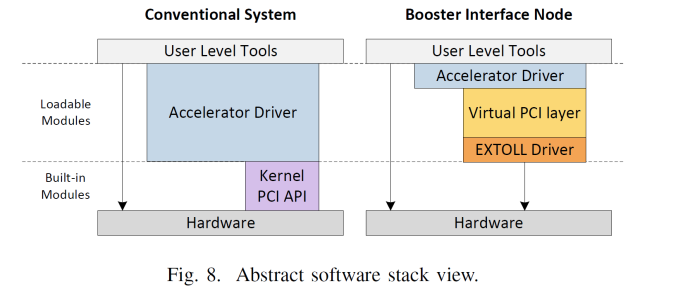
The top level representation of the EXTOLL gives seven external ports supporting cluster architectures up to a 3D Torus plus one extra. The internal switch manages which network port is in use, derived from the translation layer provided by the IP blocks: VELO is the Virtualized Engine for Low Overhead that deals with MPI and in particular small messages, RMA is the Remote Memory Access unit that implements put/get with one-or-zero-copy operations and zero CPU interaction, and the SMFU which is the Shared Memory Function Unit for exporting segments of local memory to remote nodes. This all communicates to the PCIe coprocessor via the host interface which supports both PCIe 3.0 or HyperTransport 3.0.
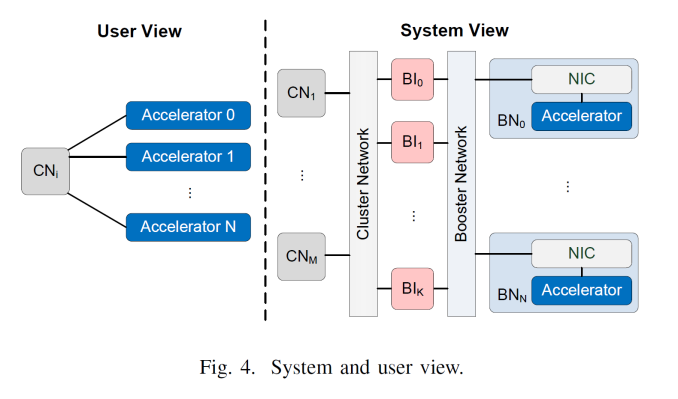
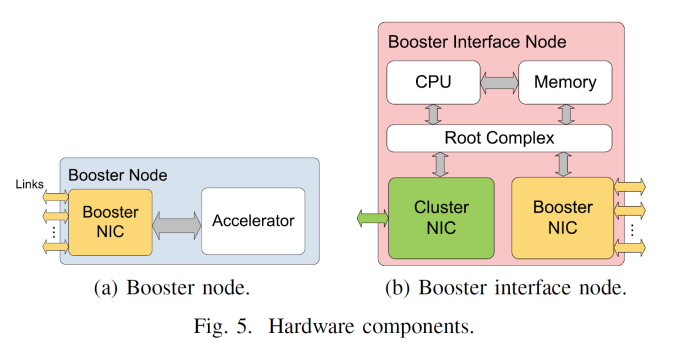
From topology point of view, EXTOLL is not to act as a replacement for a regular network fabric and adds in a separate fabric layer. In the diagram above, the exploded view gives compute and host nodes (CN) offering standard fabric options, booster interface nodes (BI) that have both the standard fabric and EXTOLL fabric, then booster nodes (BN) which are just the PCIe coprocessor and an EXTOLL NIC. With this there can be a 1 to many or a many to many representation depending on what is needed, or in most cases the BI and BN can be combined into a single unit. From the end users perspective, this should all be seamless.
I discussed this and was told that several users could allocate themselves a certain number of coprocessors or the admin can set the limits depending on login or other workloads queued. On the software side, EXTOLL sits between the coprocessor driver as a virtual PCI layer. This communicates to the hardware through the EXTOLL driver, telling the hardware to perform the required methods of address translation or MPI messages etc. The driver provides the tools to do the necessary translation of PCI commands across its own API.
The goal of something like EXTOLL is to be part of the PCIe coprocessor itself, similar to how Omni-Path will be on Knights Landing, either as a custom IC on the package or internal to the die. That way the EXTOLL connected devices can be developed into devices in a different physical format to the standard PCIe coprocessor cards, perhaps with integrated power and cooling to make design more efficient. The first generation of this was built on an FPGA and used as an add-in to a power and data only PCIe interface. The second generation is similar, but this time has moved out into a 65nm TSMC based ASIC, reducing power and increasing performance. The latest version is the Tourmalet card, using upgraded IP blocks and featuring 100 GB/s per direction and 1.75 TB/s switching capacity.
Current tests with the 2nd generation, the Galibier, and a dual node design gave LAMMPS (a biochemistry library) speed up of 57%. The concept of host-less PCIe coprocessors is one of the next steps towards exascale computing, and EXTOLL are now straddling the line between commercial products and presenting their research as part of academic endeavours, even though there is the goal of external investment, similar to a startup. I am told they already have interest and proof of concept deployment with two partners, but this sort of technology needs to be integrated into the coprocessor itself - having something the size of a motherboard with several coprocessors talking via EXTOLL without external cables should be part of the endgame here, as long as power and cooling can be controlled. The other factor is ease of integration with software. If it fits easily into current MPI based codes and libraries, on C++ and FORTRAN, and it can be supported as new hardware is developed with new use cases, then it is a positive step. Arguably EXTOLL thus needs to be brought into on of the large tech firms, most likely as an IP purchase, or others will develop something similar depending on patents. Arguably the best person into that position will be Intel with its Omni-Path, but consider that FPGA vendors have close ties to Infiniband, so there could be potential there. Relevant Paper: Scalable Communication Architecture for Network-Attached Accelerators |



| << Previous Day |
2015/12/21 [Calendar] |
Next Day >> |