[Most Recent Entries] [Calendar View]
Tuesday, May 24th, 2016
| Time | Event | ||||||||||||||||||||||||||||
| 1:30a | NVIDIA Releases 365.10 WHQL Game Ready Driver
As the news has been, new game releases means more driver updates. Alongside game ready support for more titles this week and a fix we also get a heads up on some key issues. In this driver release brings us to the release 367 of the graphics drivers. In this round NVIDIA fixed an issue under Windows 10 where Tom Clancy’s The Division exhibited stuttering after 20 to 30 minutes. NVIDIA states elsewhere in the report that in the R367 and future driver releases that Crescent Bay and OSVR development kits will not work in NVIDIA VRWorks Direct Mode in systems containing GPUs from multiple vendors (e.g. NVIDIA and Intel). NVIDIA recommends disabling any GPUs from other vendors from inside the BIOS in order to use Direct Mode. NVIDIA also mentioned in the release notes that issues were found with Total War: Warhammer during testing. NVIDIA say’s they are working closely with Creative Assembly to resolve the issues that were found. They recommend running the newest drivers and latest game updates to ensure the best possible experience. NVIDIA is of course providing updated support for multiple games this week. At the top of the list is this week’s release of Overwatch. With this new release NVIDIA also took the liberty to test out and provide hardware recommendations for those preparing themselves for release. With this data taken at face value it sounds like Overwatch will be easy enough to run with performance ranging from an average of 60fps at 1080p medium on the GTX 950 to an average of 60fps on High at 4K with a 980Ti. World of Tanks and War Thunder will also be receiving optimizations to coincide with their latest updates. Anyone interested can download the updated drivers through GeForce Experience or on the NVIDIA driver download page. More information on this update and further issues can be found in the 368.22 release notes. | ||||||||||||||||||||||||||||
| 2:30a | AMD Releases Radeon Software Crimson Edition 16.5.3
New technologies come along, new games release, things break, and developers fix them. As this cycle continues we are brought to this latest update from AMD which gives us fixes in the Crossfire and XConnect departments, along with optimizations for new and updated games. AMD Radeon Software Crimson Edition 16.5.3 brings the Driver Version to 16.20.1013. With this release some fixed issues include crossfire fixes such as stutter while playing in Fallout 4 and texture flickering found when playing The Division with Crossfire enabled. Moving on to Radeon Settings, the utility may be removed from the system if the Radeon Software installer is launched while Radeon Settings is open. Also among the fixes is AMD XConnect which, though still young, is being improved as well. With Intel’s new Skull Canyon NUC there were stability issues which are now fixed, and a BSOD caused while Safe unplugging with AMD XConnect has now been fixed. Among the latest to receive game specific optimizations from AMD are Total War: Warhammer and Overwatch which are both being released this week. Dota 2 is also recieving renewed optimisation for releasing a beta version of Vulkan support. As always, those interested in reading more or installing the updated hotfix drivers for AMD’s desktop, mobile, and integrated GPUs can find them either under the driver update section in Radeon Settings or on AMDs Radeon Software Crimson Edition download page. | ||||||||||||||||||||||||||||
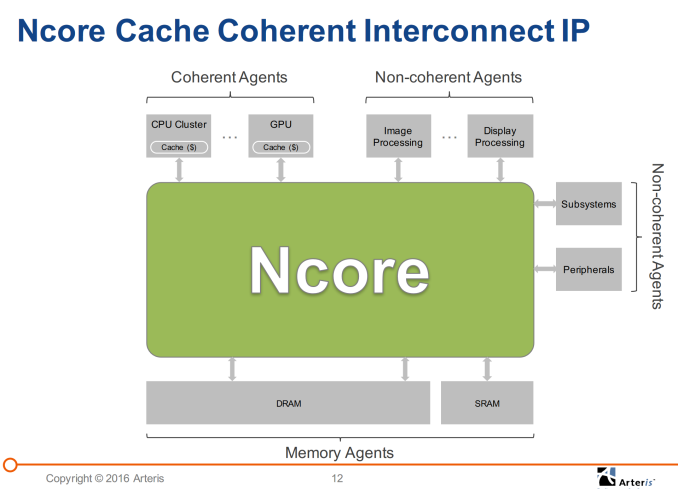
| 9:00a | Arteris Announces Ncore Cache-Coherent Interconnect
Arteris is a little mentioned company which we haven't had the opportunity to cover in the past, yet they provide IP for one of the most important parts of a modern SoCs: the various internal interconnects. Today's system-on-chips are compromised of dozens of different subsystems harbouring different kind of IP blocks which each have their specialised functions and purpose. Last year's deep dive review of the Exynos 7420 was an attempt at trying to show an example on how some of these subsystems work in union to enable various functions of today's smartphones. The section where I talk about the SoC's internal busses is one of the more interesting parts. Yet, at the same time, it's also one of the parts where we have the least amount of information on, as the interconnect is one of the IP blocks which remains largely transparent to the overlying SoC functionality and software. In fact, it's Arteris IP FlexNoC IP which powers most of these SoCs, at least for vendors like Samsung, HiSilicon, LG in the mobile space and many others such as MobilEye, Freescale or Renesas in sectors such as the automotive SoC space. In recent years in particular we've been talking a lot about cache-coherency and the interconnects which enable this functionality in mobile SoCs. ARM has been especially at the forefront of the topic as big.LITTLE heterogeneous CPU systems rely on cache-coherency to enable all processors in a system to work simultaneously, so of course we've had some extensive coverage talking about the by now familiar ARM CCI products.
As heterogeneous systems become the norm and customer increasingly demand the functionality, it's a natural progression to try to expand the IP offerings to also offer a cache-coherent interconnect able to provide the same functionality as ARM's CCI (Cache Coherent Interconnect) and CCN (Cache Coherent Network) products. Today's announcement revolves around Arteris' new Ncore Cache Coherent Interconnect. Arteris is in an interesting position here as they already have extensive experience with interconnects, so we're curious as to how their new IP is able to differentiate from ARM's offerings. Differentation is of course the key word here as this year in particular we've seen vendors start deploying their in-house designs, such as Samsung with their SCI (Samsung Coherent Interconnect) in the Exynos 8890 or MediaTek with the MCSI (MediaTek Coherent System Interconnect) in the Helio X20.
Ncore builds on the FlexNoC interconnect IP in that it relies on a lightweight switch-based fabric. In contrast, ARM's CCI is based on a crossbar architecture. One of the advantages of the former lies in the physical implementation of the interconnect as the packet-based network is able to use far less wires than an AXI-based crossbar. An 128-bit bidirectional AXI interface which is what we typically find requires 408 physical wires while the same data-width based on Arteris' internal protocol requires less at only 300 to 362 wires (depending on configuration). The advantage of Ncore being largely based on FlexNoC means that vendors have large flexibility in terms of implementation configuration. When a vendor licenses Ncore, they also use a FlexNoC license. One example which Arteris presented is that the vendor can then implement a coherent interconnect "overlaying" a non-coherent interconnect, with the other possibility being to implement the two as two separate entities. It wasn't exactly clear what the exact differences between the two options are, but we're likely talking about actual physical layout of the interconnects. Physical layout is definitely one of the aspects that Arteris seems to be confident on being able to differentiate from the competition as they promise better layout and routing flexibility when compared to other solutions. This allows vendors to achieve better overall SoC block layout and possibly enable gains in performance, power and most importantly, die area.
Ncore's components are composed of a few key blocks: On the interface side we have CAIs (Coherent Agent Interfaces) which connect to the desired IP block (agent) via "ports". Ports here refers to whatever interfaces the connecting agent offers, generally we'll be talking about AMBA ACE interfaces. For use-cases which were're familiar with and taking for an example ARM's CPU or GPU products this means 128-bit ACE interfaces. I asked how one would implement high-bandwidth agents such as ARM's Mimir GPU which can offer up to 4 ACE interfaces to the interconnect, and the solution is to simply use 4 ports to a single CAI. Multiported CAIs scale bandwidth into the CCTI with no associated bandwidth loss. CAIs are offered in different classes depending on the supported agent protocol which can be ACE, CHI or any third-party protocols. There is a translation layer/wrapper which does the conversion from the external to the internal coherency. This seems very interesting as it allows Ncore large flexibility in terms of interoperability with other vendor's coherent systems, while for example ARM's product offerings are specialized and segregated into different categories depending on if they serve AMBA 4 ACE (CCI) or AMBA 5 CHI (CCN). CAIs are able to operate on their own clock and voltage plane for power management, and usually vendors chose to tie them to the clock and voltage plane of the connected agent / IP block. The central CCTI (Cache Coherent Transport Interconnect)'s transport layer is based on a simplified FlexNoC which utilizes proprietary protocols and interfaces. Again, this is a switch based architecture with fully configurable topology based on the customer's needs. It's actually hard to talk about bandwidth achieved by the interconnect as Arteris claims that the internal data-widths are fully configurable by the customer in 64, 128, 256 and in the future 512b widths, but they assured that the IP has no issues to scale up to satisfly the bandwidth requirements of fully configured CAIs. The Coherent Memory Interfaces, or CMI's, are relatively self-explanatory. CMIs act as master interfaces on the interconnect. CMIs are also able to employ multiple ports in order to increase the memory bandwidth or to allow for flexibility between frequency and interface data widths.
NCB's are Non-Coherent Bridges which are used to interface between the coherent system and non-coherent systems or agents. NCBs are able to convert non-coherent transations into IO-coherent transations. Non-coherent traffic can be aggregated, triaged and vectored into one or multiple NCBs from non-coherent interconnect, essentially allowing for traffic shaping. A unique feature of Ncore's NCB's are the ability for them to employ so-called proxy-caches which are able to provide pre-fetch, write-merging and ordering functionality. The caches are configurable to up to 1MB per NCB in 16-way associative spans. Arteris claims that this can be useful to offer better interoperability between blocks which can have different sizes and also offer power benefits for transactions which then no longer have to find their way all the way to DRAM. The most interesting aspect of the latter point also includes communication between two non-coherent agents which allows for a total bypass of system memory. Write-gathering can improve power by reducing the amount of main memory accesses.
Finally we can talk about Ncore's approach to snoop filters. First of all, Ncore supports directory-based snoop filters. We've talked about and explained the importance of snoop filters in coherent interconnects when ARM introduced the CCI-500 and CCI-550. Arteris' implementation differentiates in that it makes use of multiple smaller snoop filters in place of a larger monolithic filter.
Advantages of the multiple snoop filter approach lies in the reduction of die size thanks to a reduced need for storage, or in other words, SRAM, on the part of the the physical implementation. In an example detailing a 2x A72 with 4MB and an 2x A53 with 256KB cache system the advantage is around 8% if you keep the same set-associativity as the single filter option. The directory is also able to have multiple ports allowing for higher bandwidth which could improve performance of the system. The same CPU configuration with one agent for an IO coherent GPU, one NCB with 16KB proxy cache on a TSMC 16FF+ process with SVT (standard transistor Vthreshold) libraries running at 1GHz target frequency is said to take up approximately 1.1mm². The metric doesn't include any non-coherent interconnect and is subject to a SoC's floorplan and physical design constraints.
Arteris sees Ncore continue to evolve in terms of its architectural capabilities with each new release. The latest version 1.5 of the IP which is being released this month is able to scale up to 8 fully coherent CAIs, 4 IO coherent CAIs, 4 NCBs and 6 CMIs with up to 6 snoop filters and 4 ports to the directory. Overall Arteris' Ncore Cache Coherent Interconnect continues FlexNoC's design philosophy by enabling vendors able to use a scalable and configurable solution which offers both high performance and low power at a high area efficiency. Ncore's main advantage seems to be on the physical implementation side as Arteris promises much better layout flexibility and area efficiency. Today's SoC interconnects can take up large amounts of a chip's overall die area and recent manufacturing nodes have shown that wire scaling hasn't kept up with transistor scaling, making this an increasingly important design property that vendors have to account for, and Ncore seems to address these needs. | ||||||||||||||||||||||||||||







| << Previous Day |
2016/05/24 [Calendar] |
Next Day >> |