[Most Recent Entries] [Calendar View]
Tuesday, August 23rd, 2016
| Time | Event | ||||||
| 12:40a | Hot Chips 2016: NVIDIA Pascal GP100 Die Shot Released
The first day of conference sessions wrapped up earlier this evening at the annual Hot Chips symposium. One of the computing industry’s lower-key events, the IEEE conference for high performance chips is not a venue for product announcements, but instead a more focused conference for tech companies and their engineers to let their hair down a bit and present some deeper technical workings of their products. Even these aren’t full product briefings – since they’re often for future products – but it’s a good venue to dive a little deeper and learn a little bit more about the technologies and decisions that have gone into putting these chips together. Over the next two days we’ll be covering the highlights of several presentations, but I wanted to start this year’s coverage off with some nerdy pictures. I am of course referring to die shots, as NVIDIA has released the first die shot of their behemoth 610mm2 GP100 die as part of a presentation on Pascal and NVLink 1.0. Die shots have been relatively rare in the GPU industry in recent years, particularly those for the highest-end GPUs with the most features.
GP100 is particularly interesting because it’s the first NVIDIA part featuring HBM and NVLink, two interfaces which (at least for NVIDIA) premiered on GP100. The die shot itself is not significantly enhanced (and I’m not going to spoil a good die shot here), but even with just basic coloring you can make out features such as the thread scheduler and other uncore features in the center, along of course with the SMs. GP100, as a reminder, has 60 in all, organized into 30 TPCs, the latter of which is what you’re probably counting right now. Top and bottom of this picture appear to be the HBM2 interfaces. Despite the width of GP100’s 4096-bit HBM2 bus, the space consumed by HBM2 appears to be relatively small on the admittedly large GPU, which is one of the benefits of HBM as it allows for very tight routing and simpler GPU-side logic. Going HBM didn’t just get NVIDIA more memory bandwidth, but I fully expect it also got them a meaningful increase in die area that they could dedicate to GPU logic.
Meanwhile the presentation also gives us our best shot to date of a full (and presumably production) GP100 package. Note the tight spacing between the HBM2 stacks and the GPU die; NVIDIA did not waste any space here, as the memory stacks have been placed as close as they can be. Both the memory and GPU sit on top of the silicon interposer, itself not much larger than the hardware it sits on. Due to the large size of GP100, every millimeter ends up mattering here, as the resulting interposer has to be quite large even with this dense packing. This also does a great job illustrating just how much larger HBM2 stacks are than HBM1 stacks, as they now are a considerable fraction of the die size of GP100 itself, as opposed to the smaller HBM1 stacks used on AMD's Fury X last year. The big question, of course, is when this technology will trickle down into cheaper, consumer-level boards. Right now HBM2 is still quite expensive, while GDDR5X has allowed NVIDIA to cover much of their bandwidth needs on consumer parts with the cheaper memory technology. However as we’ll see in the Hot Chips memory presentation, Samsung and Xilinx have some ideas on how to handle that… | ||||||
| 3:00a | Hot Chips 2016: Memory Vendors Discuss Ideas for Future Memory Tech - DDR5, Cheap HBM, & More
Continuing our Hot Chips 2016 coverage for the evening, along with the requisite presentations on processors, several of the major players in the memory industry are also at the event making their own presentations. A fast chip is only as swift as the memory that is responsible for feeding it, so the development of faster processors is inexorably tied to the development of faster memory technologies and the introduction of additional layers to the computer memory hierarchy. Like the chip presentations themselves, I should be clear that these aren’t product announcements. But they’re a short, useful look into the challenges the memory manufacturers face and what ideas they’re floating for future generations of memory technology. MicronThe first memory manufacturer to present was Micron. The firm has an interesting stake in the memory industry; while producing a number of common adopted memory technologies like DDR3 and DDR4, they have also gone their own way in pioneering HBM competitor Hybrid Memory Cube (HMC) and the faster GDDR5X memory technology. The former has not seen much success so far, while the latter has been adopted by NVIDIA for their highest bandwidth configurations on consumer (non-GP100) parts.
One interesting slide from Micron’s presentation was showing how the memory industry has been impacted by the greater difficultly in manufacturing at smaller geometries. The number of mask levels has increased over the years – especially the number of non-lithographic steps within those mask levels – and meanwhile the total amount of cleanroom space required to hold all of the necessary equipment has similarly increased as well. For an equivalent number of wafers, Micron’s 20nm tech takes more than 80% additional space compared to 30nm, which is not very far off from the 100% increase in memory density that you get from going from 30nm to 20nm in the first place. The lesson here being that memory manufacturers are facing many of the same constraints as logic manufacturers. Every generation the capital costs increase – and significantly at that – which squeezes margins and investors alike. The memory industry has seen a fairly regular pattern of boom and bust cycles up until now, with each bust cycle claiming a manufacturer or two. However as the number of manufacturers dwindle, I’m not sure consolidation alone is going to be able to continue to offset the higher costs.
Meanwhile turning towards the future, the company very briefly mentioned their current plan for the memory technology that will follow DDR4, which is aptly being named DDR5. Keeping in mind that the standard has yet to be created and ratified by the JEDEC – and likely won’t be for a couple more years – Micron would essentially like to once again double the DRAM prefetch yet again, to 16n (the same as GDDR5X). Doubling the prefetch doesn’t increase the memory’s internal clock rate, but allows for a larger number of bits to be gathered per clock, and sent out over the higher frequency bus. All the while Micron would also like to get the memory voltage down to 1.1v from today’s 1.2v for standard DDR4. Presumably this would be using a form of QDR (like GDDR5X), with the current aim to get it into production in 2019.
Finally, Micron also published a useful slide that helps to illustrate where they see 3D XPoint memory fitting into the computer memory hierarchy. This is essentially split between SSD-style implementations that access the memory over the PCIe bus, and RAM-style implementations that access the memory over standard memory buses in the form of DIMMs. Neither is as fast as DRAM (and 3D XPoint lacks the near-infinite endurance of DRAM), but it allows for interesting concepts such as databases stored almost entirely in 3D XPoint memory in DIMM form, allowing for relatively fast access combined with the inherent non-volatility of the memory. SamsungThe second of the memory manufacturers to present was Samsung. Compared to Micron, Samsung has walked the more traditional path, embracing HBM and opting not to build GDDR5X. As a result, in their presentation looking at future memory technologies, we’re seeing where they want to go from today’s HBM2 and GDDR5 technologies.
Throughout their presentation, Samsung laid out ideas for new generation memory standards for DDR, LPDDR, and GDDR5. The bulk of Samsung’s material was on the latter two, focusing their efforts on the realms of high-bandwidth memory technologies and low-power memory technologies.
On the low-power side, Samsung is proposing a technology they are calling LP(DDR)4X. An extension of current LPDDR4, Samsung wants to enact changes that allow reducing the memory bus voltage (VDDQ) from 1.1v to 0.6v, nearly halving the voltage required. The end goal would be to further reduce the power consumption of I/O – so not the memory itself, but rather moving data around – which combined with a process node shrink Samsung estimates could reduce total DRAM power consumption by 18%. As for why Samsung would do this, one needs to look no further than mobile. Power is the ultimate limiting factor of computing performance these days, and that is especially the case on mobile where there is a fixed heat budget and a fixed total power budget in joules. So any reduction in power consumption can either extend battery life, or allow Samsung to further ramp up memory performance at the same power level.
The company also floated some high-level ideas for where they’d like to go with Post LP4 (LPDDR5). Through some optimizations such as even deeper sleep states and adjustments to factors like the precharge standby current, Samsung would like to reduce power consumption per Gbps a further 20% over LP4X.
One other idea the company is floating particularly for SoC-type designs is PIM – Processing In Memory. This would move some logic into the DRAM, allowing processing to take place closer to the memory source. The impetus behind this is that I/O power remains one of the biggest components of memory power consumption, and in theory it’s unnecessary since it’s simply moving data rather than processing it or load/storing it. The concept here then would be that by moving some processing closer to DRAM – say parts of a GPU – then less power is spent sending data to the GPU over the expensive memory bus. Instead what’s sent is the already processed data, which is a smaller amount of data, and consequently takes less power to send. The risk, of course, is that you’re now mixing logic with memory, which can be harder to implement and validate.
Curiously, Samsung is going almost the opposite direction at the high-end of the memory market. In a proposal for low-cost HBM, Samsung laid out a plan for how to bring down the complexity of HBM, and as a result the total cost of the fast-but-expensive memory technology. The low cost proposal essentially trades off some width for frequency; moving a stack from 1024-bits to 512-bits, but increasing the per-pin frequency by 50%. The net result is still less bandwidth than HBM2, but not immensely so. The big savings here come from the narrower width allowing for simpler memory stacks with fewer TSVs. TSVs are the breakthrough technology that make HBM possible, but they also remain one of the most stubborn components to get correct, as thousands of vias must be wired up inside a single stack. So a die stack with fewer TSVs will be easier to manufacturer. The other interesting aspect of this proposal is that Samsung wants to remove the base logic/buffer die. To be honest I’m not 100% sure how this would work, as one of the fundamental tenants of HBM is that it’s a logic-to-logic (processor to logic die) connection, with the HBM stack’s logic die then coordinating the relatively dumb DRAM layers. Removing the logic die would certainly bring down costs, as it means no longer meshing logic with DRAM on a single package, but it’s not clear where the HBM PHY lies on the cost-reduced memory stack. Finally, partially as a consequence of the narrower I/O, Samsung wants to try to get away from silicon interposers and use organic interposers instead. Silicon interposers are simple – there’s no logic, just routing – but they’re a big chunk of silicon, and that comes at a cost. If they were able to move to an organic interposer, then the interposer cost would be significantly reduced. Bear in mind that all of this is just a proposal – Samsung’s slide even notes that they still need client feedback to figure all of this out – but it will be interesting to see how much of this gains traction. At the same time I’m left to wonder what the resulting power cost may be; part of what makes HBM so efficient is that it’s wide and slow. The low-cost proposal here makes HBM a little more GDDR-like, and that could sacrifice some of the efficiency improvements.
Speaking of GDDR, Samsung also pitched their idea for what Post GDDR5 (GDDR6) would look like. Fundamentally I’m not sure this is all that different from GDDR5X; the memory clock stays the same, while the data clock is doubled versus GDDR5, implying a 16n prefetch. Samsung’s target bandwidth range is from 14 to 16Gbps, which is at the very high end of Micron’s own goals for GDDR5X. I assume there’s more to this than simply a larger prefetch and a faster bus, but we’ll have to see what happens as the manufacturers eventually bring a GDDR6 standard to the market. SK HynixAs the memory manufacturer the most responsible for the development of HBM in the first place, SK Hynix’s Hot Chips presentation was all about HBM, its uses, and how technology developed from it can be used in other applications. There’s admittedly very little forward-looking about their presentation – the bulk of it was about why HBM is such a good fit for various applications and how they ensure reliability of the complex technology – but there was a brief discussion of where they want to go for HBM3.
The goal for HBM3 is to broaden its reach from high-end applications of today to a wider range of applications for tomorrow. No specific technologies or changes are proposed in SK Hynix’s slides, but at a high level it’s not too different from Samsung’s low-cost HBM proposal. Specifically, SK Hynix wants to make ECC an optional feature, and they want to make further changes to work on the cost and density of the technology. And of course, they also want to further improve on bandwidth, making HBM even faster at the high-end for the current types of devices that are already using HBM. XilinxThe last memory presentation I’ll be coving is from Xilinx. The firm is better known for their FPGAs and other forms of programmable logic, but they are also a major consumer of memory technologies and have their own ideas and concerns for how the memory ecosystem should advance.
One interesting point made by Xilinx in their presentation was that, as you’d expect for stacking components, heat is an issue. The farther down the stack you go, the warmer it gets. Besides the absolute heat concerns – exceeding a safe temperate for the HBM stack – the fact that the different layers of the memory are running at different temperatures is also less than ideal (think temperature compensation and material expansion). Xilinx is especially concerned here for what this means for 8-Hi stacks, which double the capacity of an HBM stack by doubling the number of DRAM layers. In practice this would make the lower DRAM and logic layers even more insulated, making them even hotter. And the sheer density of HBM (even an 8-Hi stack isn’t all that tall) makes those lower layers difficult to cool with air. As a result Xilinx is pushing for HBM to be developed so that it can withstand high Tjunction (Tj) temperatures, in order to ensure that air cooling of 8-Hi stacks is viable. To that end, Xilinx would like HBM’s TjMax to be over 95C, which is not an uncommon max temperature (GPUs and CPUs often have similar rules), but none the less illustrates how hot HBM can get.
Meanwhile their presentation also contains a handy chart of design rule comparisons for multi-die packaging. This is specifically useful for HBM, as the principles here will be useful for bringing HBM costs down. The silicon interposer is currently the only working option, but like the other presenters, Xilinx would like to have cheaper options in order to broaden the adoption of HBM. If all goes well, technologies like organic substrates and Wafer Level Fan Out may be two such solutions to the problem. | ||||||
| 7:15a | MSI Unveils the X99A Workstation Motherboard
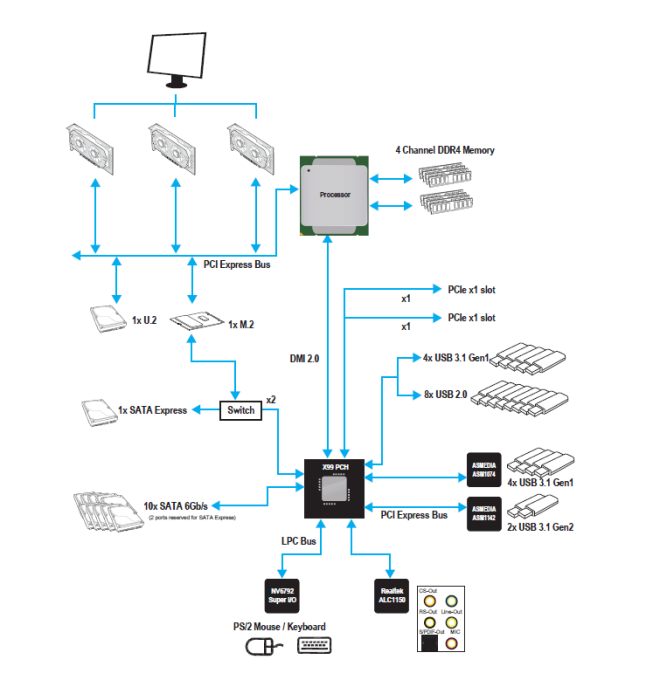
Last week MSI introduced its new X99A Workstation motherboard, part of the X99 refresh we've seen over the past couple of months following the launch of the Broadwell-E processor line. Despite the name 'workstation', this board is based on the consumer-grade Intel X99 PCH rather than the server oriented parts, and as a result it supports overclocking. Part of the 'Workstation' feature set means that it has qualified support for NVIDIA Quadro PCIe cards, compatibility with ECC memory, and a U.2 connector for storage. The manufacturer claims that the mainboard uses special components that can improve the endurance of the board, although the warranty is still listed as three years. Typically, workstation-class motherboards for Intel Xeon E5 v3/v4 processors in LGA2011-3 packaging are based on the Intel C612 PCH, which has the same I/O features as the desktop-class Intel X99, but also supports a number of additional capabilities, which are important for business environments, such as vPro, RSTe, SVT and so on (you can read more about Intel’s 612 chipset here). When it comes to professional workstation vendors that supply machines to large corporations, those technologies make a lot of sense and are generally welcome. However, for prosumers and for many professionals working in small/medium businesses, these options might not be required, which is why a lot of motherboard manufacturers offer Intel X99-based workstation-class mainboards that fully support overclocking but continue to have numerous workstation features (such as support for ECC, when Xeon CPUs are installed). This is the focus of the X99A Workstation. The MSI X99A Workstation (7A54) motherboard features one LGA2011-3 slot for Intel Core i7 as well as Intel Xeon E5 processors, though it is interesting to note that the maker does not list Intel Xeon SKUs in its qualified vendor list. Along with the eight-phase power delivery (which uses solid-state chokes), the mainboard carries eight DDR4 memory slots that not only support non-ECC/unbuffered memory modules with XMP 2.0 (and up to DDR4-3333 supported in OC modes), but also RDIMMs with ECC with applicable CPUs. For add-in cards, the motherboard has three PCIe 3.0 x16 slots (which can work in x16, x16/x16, x8/x16/x8 modes with CPUs featuring 40 PCIe lanes) as well as two PCIe 2.0 x1 slots from the chipset.
When it comes to storage-related capabilities, the MSI X99A Workstation comes with one M.2-22110 slot, one U.2 port running in PCIe 3.0 x4 mode, and a SATAe port (unavailable when M.2 and U.2 are used). For traditional HDDs/SSDs/ODDs, the motherboard offers 10 SATA 6 Gb/s ports (including two ports from SATAe). So, in total the motherboard can support up to 12 storage devices.
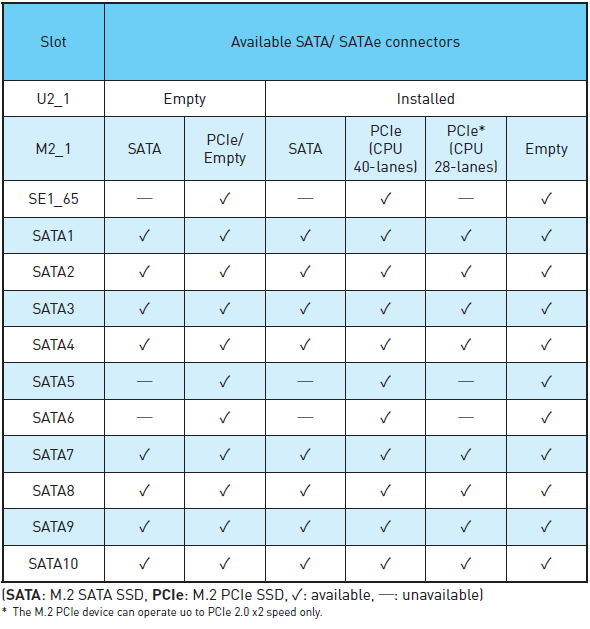
The chipset diagram shows what is in play, and the M.2 configuration is a little odd given that 2 lanes come from the PCH and another two from the CPU despite standard CPU bifurcation stops at x4. In this instance I would have suggested that MSI merely considers the M.2 a CPU device with x4, given that the system would support it, but because Intel has 28-lane CPUs for the platform this can cause differences in bandwidth available. MSI shared the storage support matrix to help users looking into the X99A Workstation:
For audio and networking, the MSI X99A Workstation uses the Realtek ALC1150 solution (with PCB separation and filter caps) with 7.1-channel analog as well as S/PDIF outputs. For networking, the motherboard has an Intel I218LM and an Intel I210AT Gigabit LAN controllers, with teaming support listed. The mainboard also features ASMedia’s ASM1142 controller to enable one USB 3.1 Type-C (10 Gbps) and one USB 3.1 Type-A (10 Gbps) connectors on the rear panel. In addition, the motherboard supports eight USB 3.1 Type-A (5 Gbps) and eight USB 2.0 ports. The MSI X99A Workstation should be available shortly, but pricing has not yet been decided.
| ||||||
| 8:15a | Supermicro Releases Intel Xeon Phi x200 (KNL) Systems: Servers and a Developer Mid-Tower
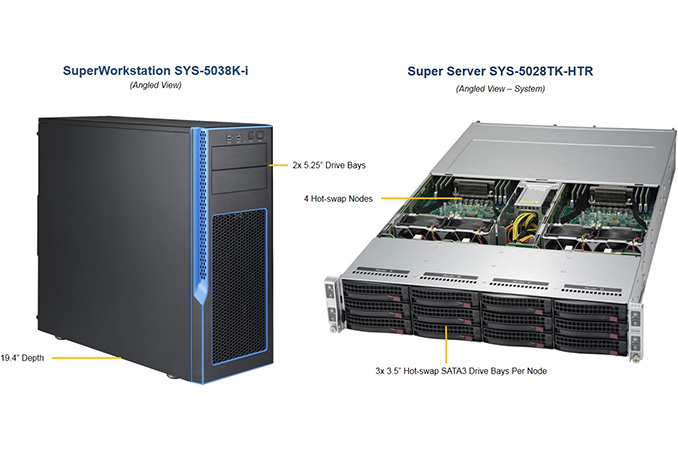
Supermicro has released two systems featuring Intel’s many-core Xeon Phi x200 processors: a workstation and an ultra-dense server. The platforms support up to 384 GB of DDR4 memory and are based on the good-old Intel C612 PCH. Due to high TDP of Intel’s Knights Landing CPUs, Supermicro had to use a custom closed-loop liquid cooling for its SuperWorkstation SYS-5038K-i. Intel officially launched its Xeon Phi x200 many-core Knights Landing platform in June, but the company disclosed most of the details regarding its new processors last year at Supercomputing15. As discussed, every Xeon Phi x200 in LGA packaging has up to 72 cores (based on highly-modified Atom Silvermont microarchitecture) running at up to 1.5 GHz, with up to 36 MB of L2 cache, 16 GB of on-package high-performance memory (MCDRAM), six-channel DDR4 DRAM controller as well as 36 PCIe 3.0 lanes. The Xeon Phi x200 chips in LGA3647 form-factor can run as a host, directly with an operating system on board (including Windows Server 2016) which is an upgrade over the older Xeon Phi parts which only ran as co-processors on the PCIe bus. Moreover, the internal PCIe 3.0 root complex gives the Xeon Phi some PCIe lanes to allow other coprocessors to be plugged in - either additional Xeon Phi accelerators in the card form-factor, or AMD/NVIDIA cards, to maximize the compute horsepower. SuperServer 5028TK-HTR
Since Intel Xeon Phi x200 processors are designed mainly for high performance computing, so as a result the OEM developers that build servers for customers tend to focus their efforts primarily on ultra-dense platforms. One of the first Xeon Phi x200 solutions from Supermicro will be the SuperServer 5028TK-HTR, which packs four hot-swappable half-width nodes based on the company’s K1SPi motherboards into a 2U form-factor. Each 5028TK-HTR sports 12 3.5” hot-swappable SATA/SAS storage devices (three per node) as well as a 2000 W redundant PSU. Meanwhile, the K1SPi carries one P1 socket, six DDR4 DIMM slots (for up to 384 GB of DDR4), two PCIe 3.0 x16 low-profile slots, a PCIe 3.0 x4 slot, an Intel i350 dual port GbE controller, the Aspeed AST2400 BMC platform management. Supermicro’s SuperServer 5028TK-HTR (as well as the K1SPi motherboard) support Intel Xeon Phi x200 processors with up to 250-260 W TDP. Machines supporting Knights Landing models featuring Omni-Path fabric will be announced at a later date. SuperWorkstation 5038K-i
While HPC is a very important market for products like Xeon Phi, there is a segment of Xeon Phi clients who use them in desktop environments for financial analysis, oil and gas exploration, simulations as well as other applications. Also, HPC developers typically want a system-under-the-desk to actually develop their software with immediate results. Specifically for them, at the request of Intel, Supermicro introduced its SuperWorkstation 5038K-i desktop machine featuring the company’s K1SPE motherboard. The workstation is a self-contained unit sold complete, with CPU, DRAM, storage, PSU and cooling. The chassis can fit in two 5.25” ODDs (or other peripherals), six 3.5" and four 2.5” storage devices. The tower is equipped with multiple fans and come with one 750W power supply made by Seasonic as well as a custom-made closed-loop liquid cooling system with two 120 mm fans. The K1SPE mainboard features one P1 socket (with eight-phase power delivery), six DDR4 DIMM slots (for up to 384 GB of DDR4), two PCIe 3.0 x16 slots, a PCIe 3.0 x4 slot, 10 SATA connectors, two GbE ports (via Intel i350), an IPMI LAN port, Aspeed AST2400 for graphics and management, USB 3.0 ports and so on. Despite the fact that the K1SPE uses regular ATX form-factor (with ATX12V and EPS12V power connectors), it will not be sold separately. Both SuperServer 5028TK-HTR and SuperWorkstation 5038K-i machines should be available from Supermicro shortly, but only as complete systems. Therefore, their exact pricing could not be determined because it depends completely on exact configurations and quantity. We have been told that the workstation, the 5038K-i, is actually on back order with a number of customers already, however Supermicro is ramping up production as a result. Additional from Ian: We've put in a request for a 5038K-i sample, which will run Windows Server 2016. As it's a full x86 core (with additional VPUs), I want to see how well our regular x86 enterprise workloads translate into the Xeon Phi sphere. With a low single thread frequency but up to 72 cores, this test should be an interesting one. | ||||||
| 9:15a | G.Skill Shows Off Trident Z 8x8 GB and 8x16 DDR4-3333 Memory Kits
When Intel launched its new Core i7 Broadwell-E processors for high-end desktops earlier this year, all leading makers of motherboards released their new breed of Intel X99-based products that were supposedly 'optimized' for the new CPUs. Makers of memory modules are also beginning to roll-out their new DDR4 quad-channel kits that can operate at high frequencies with tight timings qualified for the new processors. At IDF this week, G.Skill demonstrated two new 64 GB and 128 GB kits designed for high-end workstations that require significant memory bandwidth. G.Skill’s upcoming quad-channel Trident Z 64 GB (8×8 GB) memory kit is rated to run at 3333 MT/s with CL13 13-13-33 latency settings at 1.35 V. Right now, the company only offers quad-channel 64 GB DDR4-3333 kits with CL16 18-18-38 timings (albeit, these are either 4×16 GB or 8×8 GB kits). Another upcoming Trident Z quad-channel kit has 128 GB (8×16 GB) capacity and can operate at 3333 MT/s with CL14 14-14-34 timings, which is considerably better when compared to CL16 18-18-38 latencies of currently available 128 GB DDR4-3333 kits from the company.
G.Skill claims that the Trident Z kits it demonstrated at IDF are based on Samsung’s 8 Gb DDR4 chips, but does not reveal whether these are ICs made using 20 nm or sub-20 nm process technology. More advanced DDR4 ICs coupled with the new memory controller inside Intel’s Broadwell-E CPUs could allow G.Skill to build new 64 GB and 128 GB DDR4-3333 HEDT kits with tight timings. It is to be expected that the company has managed to cherry-pick the right previous-gen ICs for its new memory modules and depending on the binning of such ICs, prices will be high. The demonstrations at IDF were conducted using two systems equipped with Intel Core i7-6800K processors and ASUS ROG Rampage V Edition 10 or ASUS X99-Deluxe II motherboards. The PCs were running basic applications and did not require extensive cooling.
Traditionally, all Trident Z kits come equipped with aluminum heatsinks and feature Intel XMP 2.0 SPD profiles to make it easier for end-users to run them at their data-rates with the right timings and voltage. Expect the same features from the kits that G.Skill demonstrated at IDF. The manufacturer did not announce when it plans to release its new Trident Z 64 GB DDR4-3333 CL13 and Trident Z 128 GB DDR4-3333 CL14 kits as well as their prices. Right now, G.Skill’s fastest 128 GB DDR4-3200 CL16 is available for $730 – $1042, depending on the retailer. Memory prices tend to be exponential at the high end, so these will cost a lot more. | ||||||
| 10:30a | Unpacking AMD's Zen Benchmark: Is Zen actually 2% Faster than Broadwell?
At a satellite event to Intel's Developer Conference last week, AMD held an evening soiree with invited analysts and press to talk about their new upcoming Zen microarchitecture. This was intended to be a preview of tomorrow's Hot Chips presentation, and we've already covered the juicier parts of the presentation in terms of microarchitecture announcements as well as diving deep into the Server-based Naples implementation and what the motherboards told us from memory and IO support. You can read both here: AMD Zen Microarchitecture: Dual Schedulers, Micro-op Cache and Memory Hierarchy Revealed There was one other element to the presentation that requires further discussion and analysis, if only to clean up some of the misinformation already present online and to label what was shown with a long list of potential caveats which most people seem to have passed by almost entirely. As part of the show, AMD compared the performance of their Zen engineering sample to an Intel Broadwell-E processor.
In this test, they told the audience that each system was running eight cores, sixteen threads, and will all cores set to 3 GHz (implying no turbo). Memory arrangements were not disclosed, nor storage: we were told to assume comparable setups. We were too busy trying to decipher what was on screen (and take note of the results) to actually photograph the benchmark as it happened (there are videos online), but the benchmark they showed was Blender, an open source rendering engine, with a custom multithreaded workload. The test was to render a mockup of a Zen based desktop CPU, with an effective workload of 50 seconds for these chips. I've seen numerous reports about this result saying the difference was 1 or 2 seconds, but with rarely a mention of the benchmark length, which is as important. The overall results were
All things being equal (we'll get to that in a second), this would suggest that an 8-core AMD has a ~2% advantage over Broadwell-E at the same clock speeds. Despite this result, there are a lot of unverifiable parts to the claim which makes analysis of such a result difficult. I want to go through each of them one by one to ensure everyone understands what was presented. I'll preface this analysis with two things though: one is that AMD was very careful in what they said at the event, and only said as much as they needed to. Thus is why the string of caveats for this benchmark test is fairly long. But also, AMD has to set expectations here: if they choose an environment and test that represents the peak, or relies on something special, users will feel burned again after Bulldozer. AMD has to temper those expectations but still represent a methodology that is effective to them. By leaving so many cards on the table, this can both be a help or a hindrance. But given the measured and calm, professional nature of the event, as opposed to the wild and wacky AMD events of the past, it was clear (either by design or chance) that the words used said only as much as they needed to. Along with the microarchitecture discussions, it was designed to provide a good stepping stone on to the Hot Chips presentation a few days later. So, caveats. Or disclaimers not readily provided. Let's start at the top. 1) The Results Are Not Externally Verifiable At This Time, As ExpectedWe were told the setups of the systems being used, but were unable to confirm the results manually. This is typically the case with a high level, early look at performance and other companies do this all the time. This being said, it would look bad on reports if it to turns out or someone finds a chasm between pre-launch and launch data, so the aspect of reporting this data without understanding this caveat is fundamental. The basis of publishing scientific papers is repeatability and verification - while this wasn't a scientific presentation, it is important to keep it in the back of your mind when you hear any benchmark numbers (AnandTech included - our numbers are designed to be verifiable and we want to have a history of honesty with our readers, especially when it comes to custom software/workloads we cannot disclose). 2) No Memory or TDP Numbers Were ProvidedWe were able to determine that the AMD-based systems were running 2x8 GB of DDR4-2400, although we did not get a look at Intel's memory arrangement. Similarly, due to the ES nature of the CPU, TDP numbers were also not shared however we did see all the AMD systems use either the AMD Wraith cooler (which is rated at 125W) or the new near silent cooler (95W). That tends to peg the system at a peak power consumption and some of AMD's current competitive parts actually use a cooler designed for the bracket above in TDP (e.g. A10-7860K at 65W uses the 95W cooler, A10-7890K at 95W uses the 125W cooler). 3) Blender Is an Open Source PlatformOne of the issues of using open source is that the code is editable by everyone and anyone. Any user can adjust the code to optimize for their system and run a test to get a result. That being the case, it can be difficult to accurately determine the code base for this test, and is relatively impossible to determine the code base of Blender that was compiled for this test. Even in the base code, there could be CPU vendor specific optimizations in either the code or compiler that influences how the code manipulates the cache hierarchy with the workload and adjusts appropriately. It also doesn't help that Blender has elements in the code called 'AMD', which relates to a series of internal rendering features not related to the company. Going down the optimization for specific CPU microarchitectures leads on to another more philosophical issue... 4) Did It Actually Measure IPC? (The Philosophical Debate)In the purest sense, measuring the number of instructions per clock that a set of instructions can perform can determine the efficiency of a design. However, the majority of highly optimized code bases do not have general-purpose code - if it detects a particular microarchitecture it can manipulate threads and loops to take advantage of the code design. How should IPC be measured is the main question: using identical code bases makes it easier to understand but are often non-real-world compiler targets, or highly optimized code to show the best of what the processor can do (which means that IPC performance is limited to that benchmark)? With the results we saw, if the difference of about a second in just under fifty seconds translates into a 2% difference, is it accurate to say that this is a 2% IPC increase, or does it rely on optimized/non-optimized code? Optimizing code, or profiling compilers for specific code targets, is nothing new. In the holistic view, most analysts use SPEC benchmarks for this, as they are well-known code structures, even though most benchmarks are compiler targets - while SPEC is not particularly relevant for the real world workloads, it does give an indication about performance for unknown architectures/microarchitectures. 5) The Workload Is CustomOne of the benefits of software like SPEC, or canned benchmarks like Cinebench, is that anyone (with a license) can pick up the workload and run with it. Those workloads are typically well known, and we can get performance numbers out that have known qualities in their interpretation. With a custom workload, that is not always the case. It comes down to experience - an unknown workload can have a lop-sided implementation of certain branches of code which is unknown when it comes to running the results. This is why rendering one scene in a film can take a vastly different time to another, yet the results for the 'benchmark' are significantly different depending on the architecture (one prefers lighting, another prefers tessellation etc.) Using known or standard workloads over long periods of time can offer insights into the results, whereas new workloads cannot, especially with so few results on offer. 6) It Is Only One BenchmarkThere is a reason for AMD only showing this benchmark - it's either a best case scenario, or they are pitching their expectations exactly where they want people to think. By using a custom workload on open source software, the result is very specific and cannot be extrapolated in any meaningful way. This is why a typical benchmark suite offers 10-20 tests with different workloads, and even enterprise standard workloads like SPEC come with over a dozen tests in play, to cater for single thread or multi-thread or large cache or memory or pixel pushing bottleneck that may occur. Single benchmarks on their own are very limited in scope as a result. 7) There's Plenty about the Microarchitecture and Chip We Don't Know Yet, e.g. UncoreOne of the more difficult elements on a processor is managing cross-core communication, as well as cross-core-cache snooping. This problem is overtly exponential, with the plausibility of more direct connections per core as the numbers go up. Intel has historically used a torus (ring) interconnect between cores to do this, with their large multi-core chips using a dual ring bus with communication points between the two. We suspect AMD is also using a ring bus in a similar methodology, but this has not been discussed at this time. There's also the interconnect fabric between the cores and other parts of the chip, such as the Northbridge/Southbridge or the memory controllers. Depending on the test, the core-to-core communication and the interconnect can have different performance effects on the CPU. 8) Clock Speeds Are Not Final, Efficiency Not KnownPerformance of a CPU is typically limited by the power draw - there is no point getting a small amount of performance for a large increase in power such that efficiency has decreased. AMD has stated that power consumption and efficiency was a premier goal as this microarchitecture was developed. At the demonstration, we were told that the frequency of the engineering samples was set at 3 GHz for all-core operation. We were told explicitly that these are not the final clock speeds, but it at the very least it puts the lower bound on the highest end processor. In reality, 3 GHz could be a walk in the park for the final retail units, depending on how much difference there is between the chips on display and what people will be able to buy. We are under the impression that the CPUs will have turbo modes involved, and those could be staggered based on the cores being used. But this is why I said that 3 GHz is the lower bound of the high-end processor. We know from these results (assuming point 1 in this list) that the best processor from AMD will do at least 3 GHz. There's no indication of power, and thus there's no indication of efficiency either, which is also another important metric left in the ether. 9) We Will Have to Wait to TestEveryone wants the next technology yesterday, so the 'gimme gimme gimme' feeling of new stuff is always there. AMD has already stated that general availability for Zen and Summit Ridge will be Q1, which puts the launch at four months away at a minimum. At this stage of the game, while AMD is trying to be competitive with Intel, they don't want to generate too much hype and give the game away in case it goes incredibly pear-shaped. There's the added element of the hardware and software being finalized or updated. Since I've been reviewing, no CPU manufacturer has handed out review units four months before launch (in all honesty, we're lucky to get a launch date sample a week in advance these days). In fact we'd have to go back to Nehalem and Conroe to find something that was sampled early; however Conroe just passed its 10th birthday and in that case, Intel knew they were on to a clear winner ahead rather than just 'meeting expectations'. Also, early samples of a great product will mean users will wait for it to come out, which results in revenue loss (the Osborne effect) unless you have zero stock and/or an uncompetitive product that no-one is buying. In this decade, no x86 CPU manufacturer has offered samples this far out. I'd be more than happy for that to change and I would encourage companies to do so, but I understand the reasons why. Some Final WordsMuch in the same way that taking an IQ test tells you how good you are at an IQ test, it is typically an indication that you are good/bad at other things as well (most well-engineered IQ tests go through a lot of spatial reasoning, for example). In this circumstance, a CPU performing a Blender test is only as good as a Blender test, but given what we know about the Zen microarchitecture, it is probably also good at other things. Just how good, in what metric and to what extent, is almost impossible to say. AMD has given a glimpse of performance, and they’ve only said as much as they needed to in order to get the message across. However it has been up to the media to understand the reasons why and explain what those caveats are. | ||||||
| 8:45p | AMD Zen Microarchiture Part 2: Extracting Instruction-Level Parallelism Hot Chips is an annual conference that allows semiconductor companies to present their latest and greatest ideas or forthcoming products in an academic-style environment, and is predominantly aimed as the professional semiconductor engineer. This year has a number of talks about power management, upcoming IBM CPUs, upcoming Intel CPUs, upcoming NVIDIA SoCs and the final talk of the final day is from AMD, discussing Zen in even more depth than the previous week. While we were unable to attend the event in person, we managed to get some hands-on time with information and put questions to Mike Clark, AMD Senior Fellow and Chief Design Engineer on Zen. |













































| << Previous Day |
2016/08/23 [Calendar] |
Next Day >> |