Add this feed to your friends list for news aggregation, or view this feed's syndication information.
LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose.
| Monday, June 8th, 2026 | |||||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |||||||||||
| 10:45 pm | Flat Datacenter Networks at Scale  The research roots of finding “optimal routing” networks trace back to the late 1970s. Mathematicians defined special kinds of networks called “expanders“. These are graphs with strong connectivity properties guaranteeing no subset of vertices can be isolated from the rest. In 1976, Leslie Valiant gave one of the earliest discussions of such graphs. Following work on Alon-Boppana on trying to understand the best “possible” expanders, mathematicians (notably, Lubotzky, Phillips, and Sarnak) gave constructions of such optimal expanders. These were intricate designs, used advanced number theory, and only work for specific network sizes and degrees. RNG (Resilient Network Graphs) history In 2023, Giacomo Bernardi (AWS principal scientist) started to investigate whether datacenter routers could be arranged in a flat network following Penrose tiling, a geometrical construction where shapes tessellate without ever quite repeating. Ratul Mahajan, an Amazon Scholar and Professor at the University of Washington, was intrigued. The two spent months exploring the idea, building simulations, and pushing the concept as far as it would go. Relative advantages of RNG over Fat Trees
Relative limitations of RNG (and mitigations)
References
| ||||||||||
| Monday, February 23rd, 2026 | |||||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |||||||||||
| 7:04 pm | National Academy of Engineering  I love all forms of engineering so it’s a pleasure to have just been elected to the National Academy of Engineering. Founded in 1964, the National Academy of Engineering (NAE) is a private, independent, nonprofit institution that provides engineering leadership in service to the nation. | ||||||||||
| Tuesday, December 9th, 2025 | |||||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |||||||||||
| 11:13 pm | Blue Current  I am excited to join the Blue Current Board of Directors as Amazon anchors their Series D round. Blue Current has taken a practical approach to safe solid-state batteries and their technology addresses critical needs in both stationary storage and electric vehicles. What sets them apart is their ability to manufacture domestically with a clear path to scalable, cost-effective production. Susan Stone, Kevin Wujcik, and the team have spent over a decade building a platform with safety as the foundation. I’m looking forward to supporting their commercialization journey. | ||||||||||
| Thursday, July 31st, 2025 | |||||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |||||||||||
| 9:55 pm | Darlington Nuclear Generating Station
The Darlington Nuclear Generating Station just outside Toronto has four CANDU nuclear reactors with a total output of 3,512 MW. It generates about 20 percent of Ontario’s electricity needs, enough for roughly two million homes. I recently toured the facility on a quick business trip to the area.
| ||||||||||
| Friday, February 2nd, 2024 | |||||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |||||||||||
| 6:44 pm | Pat Selinger  The best way to hire great women is to have great women at the top of the company. IBM is a lot stronger for employing Pat Selinger for 29 years . She invented the relational database cost-based optimizer, a technology that sees continued use in relational database management systems today. But more than being a great technologist, Pat is a great leader, and many of the people who worked for and with Pat were no less amazing. The Almaden database research team was amongst the most talented database technology groups the world has seen. I was lucky enough to work with Pat and the Almaden team for the years I spent as lead architect on DB2. They taught me much of what I know today about databases, helped feed my curiosity in just about all areas of computer science, and taught me a lot about getting things done when working with people I don’t directly lead. Pat contributed greatly to how I think about problems, taught me a huge amount over the years, remains a great sparring partner when working through new ideas, and introduced me to many people with her same curiosity and high technical standards. IBM just posted an article on Pat and her contribution to database research, IBM technology, and the careers of literally hundreds of IBM engineers: | ||||||||||
| Thursday, February 1st, 2024 | |||||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |||||||||||
| 8:27 pm | Seagate HAMR Yesterday, I visited the Seagate Normandale Minnesota hard disk drive wafer fabrication facility. I’m super excited about HAMR (Heat Assisted Magnetic Recording) and the areal density it supports. Seagate’s Dave Anderson first introduced this to me technology nearly 20 years ago and it’s wonderful to see it delivered to market and the volumes ramping. HAMR is a fundamental step forward in hard disk drive technology, but what I like most about the technology is the density headroom looking forward. It opens up a long-term roadmap with accelerated areal density growth: 3 terabytes per platter today scaling soon to 4 terabytes with visibility to 5 TB. That will deliver 50 TB disks. It’s hard to believe that my first Seagate hard disk drive was a 2 gigabyte (0.002 terabytes) Wren 9 back in the 1980s. Spending a day with Seagate engineering really drove home the challenge of bringing HAMR to production volume. The heat assist laser has to be placed with nanometer precision, and the head has to be able to deliver full lifetime with the additional thermal stress. | ||||||||||
| Tuesday, January 16th, 2024 | |||||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |||||||||||
| 6:10 pm | CIDR 2024  I helped kick off CIDR2024 yesterday with the keynote, Constraint Driven Innovation. My core thesis is that constraints force innovation. For example, it was slow hard disks that drove the invention of Write Ahead Logging. But constraints also block innovation. In memory databases first described in the 80s remained largely irrelevant for decades waiting for cost effective very large memory servers to make them practical. In this talk I focus mostly on the latter. Constraints that have come down or are coming down opening up new opportunities for new database technology improvements. Believing that H/W acceleration is becoming increasingly practical, we look at what’s happening in the machine learning world and argue that the database market is large enough to justify custom hardware investments. For those of you that haven’t attended the Conference on Innovative Data Research, have a look at the CIDR2024 program and consider attending the next CIDR. 20 years after attending the first, it remains one of my favorites. Talk Slides: Constraint Driven Innovation | ||||||||||
| Tuesday, August 22nd, 2023 | |||||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |||||||||||
| 3:36 pm | Amazon Elastic Block Store at 15 Years 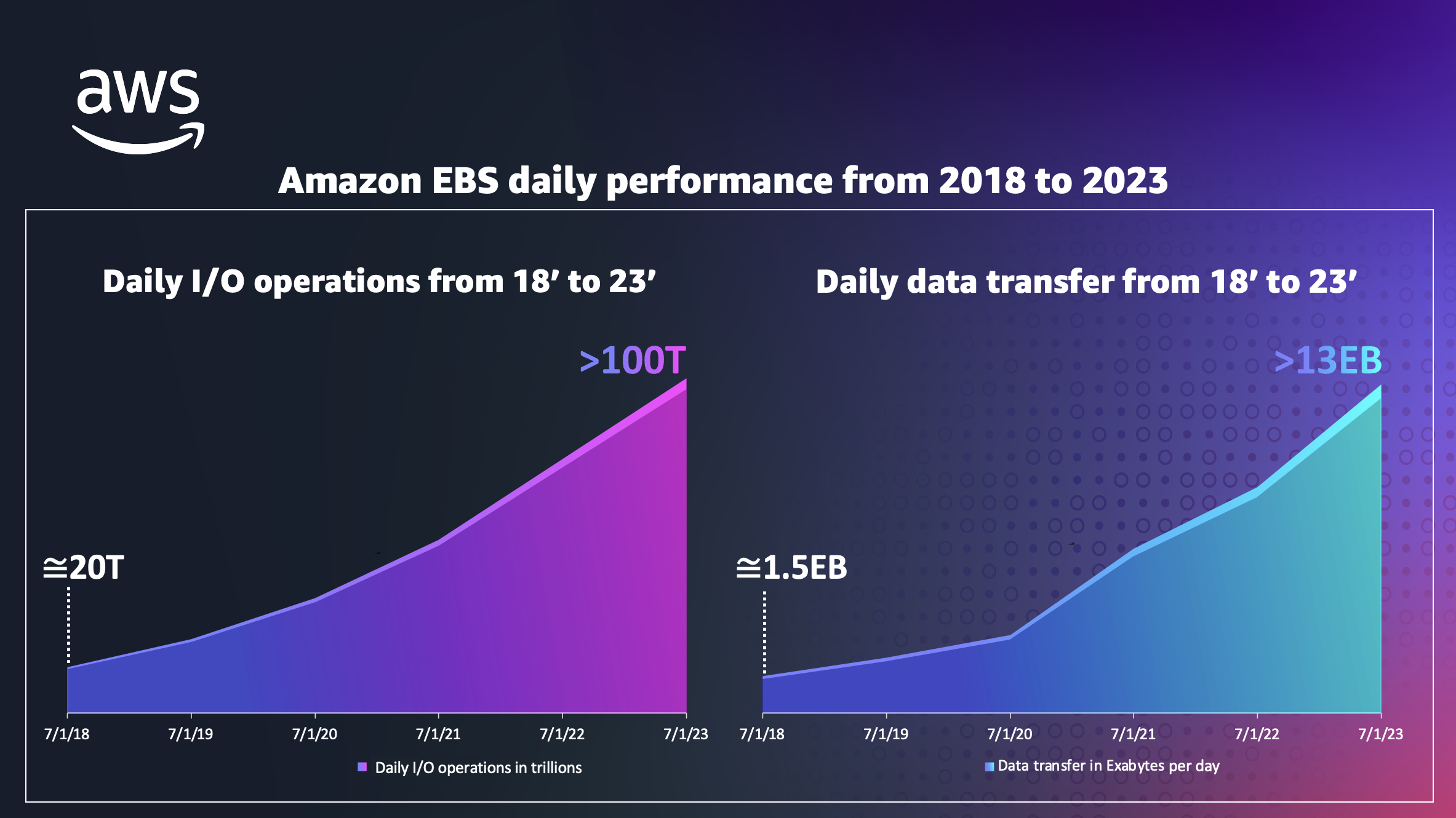 Just after joining Amazon Web Services in 2009, I met with Andrew Certain, at that time a senior engineer on the Amazon Elastic Block Store (Amazon EBS) team, to get into the details on how EBS was implemented and what plans were looking forward. Andrew took me through the details of this remote block storage solution and two things were immediately clear to me: 1) there was work yet to be done to address the most demanding workloads, and 2) the overall opportunity for EBS was massive. Having been around the database world for decades, I know just how important high-performance block storage is to customers. There was and still is a real customer need for EBS. As confident as I was that EBS was going to be a very important service for AWS customers, I wildly underestimated what the team would deliver over subsequent years and how many customers would come to trust EBS with their most mission critical features. As I write this today, it’s been exactly 15 years since Amazon Elastic Block Store was announced August 20th 2008. In thinking about what’s been accomplished over the last 15 years, I asked the team for some data points on EBS scale, usage, and adoption and I was blown away by the magnitude of some of these metrics. EBS has really grown up. I’ve been involved with EBS for the entire period so these data points should not be much of a surprise to me but most of our internal engineering discussions focus on new features, how existing features are performing, or changes and updates we want to make. We just don’t spend much time looking at service-wide aggregate I/O rates or the number of EBS volumes customers are creating. I asked the EBS team to quantify customer usage in 2023, the 15th year of EBS. Focusing first on daily usage, EBS delivers more than 100 trillion input/output operations per day. When I started working on database engines back 30 years ago, hosting 100 trillion I/O operations per day would have required more than 11 million disk drives. These I/O rates are truly staggering. Perhaps even more staggering is the fact that EBS transfers more than 13 exabytes of data for customers every day. We toss around exabytes everyday and it starts to sound normal but each exabyte is a million terabytes. Years back I saw an interesting data point in the NYTimes that adds another nice scaling point. That article estimated that 5 exabytes is the equivalent of all words ever spoken by humans since the dawn of time. That is a remarkably large amount of data. Continuing to focus on daily usage, millions of customers use EBS daily, and these millions of customers create more than 390 million EBS storage volumes each day. In celebrating these 15 years of EBS, I wanted to thank you for putting some of your most business critical and performance sensitive workloads on EBS. Your trust in EBS has helped make EBS a very large service and we all know that we need to continue to earn that trust every day. The focus on engineering care runs strong on the EBS team. We’ve done a lot over the last 15 years but there is lots more coming. It’s always exciting to see what customers are doing with EBS and many of the features and updates we have made over the years came directly from customers. We continue to have big plans for EBS and you can look forward to continuing performance improvements, advanced features, and the same engineering care that keeps EBS off your worry list. | ||||||||||
| Sunday, November 13th, 2022 | |||||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |||||||||||
| 11:00 pm | Great Product Managers  One of the Amazon Operations teams was hosting a conference for Product Managers in their organization and they asked a few of us to record a 1-minute video of what we each view as important attributes of a Product Panager. My take is below with a link to the video. The best Product Managers push teams to greatness. They share credit broadly, knowing that service success is the final measure and, really, the only one that matters. They maintain what might seem to be unreasonably high standards for themselves, and for those around them. They are never caught by surprise. They look around corners, constantly in search of problems on the horizon, whether internal or external to the team. They rush eagerly towards problems, knowing the earlier they are found, the easier to solve. They listen. They listen to customers. They listen to team mates. But they don’t blindly listen. They listen and interpret looking for the deep lessons perhaps only hinted at by what they’ve heard. They’re fast. Speed is our most important asset at Amazon. The best Product Managers find ways to help the entire team to move faster. They move quickly to make changes when things aren’t working. And, they are equally quick to double down on success. The best Product Managers make good teams into great teams. Video (1:05): Great Product Managers | ||||||||||
| Sunday, November 6th, 2022 | |||||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |||||||||||
| 4:12 pm | HPTS 2022  High Performance Transactions System (HPTS) is a invitational conference held once every two years at the Asilomar Conference Center near Monterey California. My first HPTS was back in 1995 thanks to Pat Selinger. I loved it and attended each one up until 2012 when I started a 10 year around-the-world cruise in a small boat. It was great to be back at HPTS after a 10 year hiatus. Partly it’s a chance to catch up with old friends and valued colleagues and partly it’s a chance to see interesting work from both industry and academia. HPTS is a special group and most of the value of the conference is the people that attend. Attendees cover the spectrum from students, early career engineers, to Turing award winners. I was asked to do the keynote this year and I elected to cover HPTS Comes Full Circle. I’ve linked to the slides below and the talk summary follows. HPTS Comes Full CircleOver the years I’ve been attending HPTS, the meaning of “scale” has changed fundamentally. In the early days, “high-scale” were the transaction processing systems used by the largest enterprises, and at HPTS we talked about how these systems were built and how to keep them scaling. Later, data warehouses and large-scale analytics became the HPTS definition of “large”, and their 2x growth per year became our definition of rapid scaling. In 2001 Charlie Bell and Rick Dalzell spoke at HPTS about Obidos, the core of the Amazon.com ecommerce system. Again, our definition of scale had advanced – these mega-ecommerce systems made the large-scale enterprise systems look tiny. Eight years later our definition of large had further advanced, and very large search and advertising systems had become our latest definition of “big.” Urs Holzle and Luiz Borroso’s “The Datacenter as a computer: An Introduction to the Design of Warehouse Scale Machines” focused on treating the entire datacenter as a computer. At this scale, custom hardware was possible and most of the hyperscalers were using custom server designs, with a few doing all-custom networking hardware. This revised definition of “high-scale” was a fundamental breakthrough in that we were no longer restricted to software innovation and the new canvas for high scale systems included the entire hardware and software stack. High-scale cloud computing operates at a scale an order of magnitude beyond internet search and advertising systems and opens up yet another dimension for innovation. Building-scale warehouse computing has given way to regional computing complexes of 10s of datacenter each hosting 80 to 100 thousand servers. The world-wide footprint of the largest operators is many 10s of millions of cores and growing rapidly. The best operators develop their own software, their own servers, and their own networking equipment. None are stuck accepting the slow-paced world of standards, and the scale of a single operator has continued to increase to the point where even custom semiconductors are now possible. In the networking world, companies have emerged whose entire business model is producing custom networking ASICs (Application Specific Integrated Circuits) for hyperscaler cloud computing operators. The growth rate of the hyperscaler operators has continued to accelerate and the next layer of innovation has opened up: custom general-purpose compute processors. Processor design is incredibly expensive where a single part will require a several hundred-million-dollar R&D program and competitive processors require generations of investments. HPTS innovation now includes the entire software stack, the servers, the networking system, and also the processors that form the servers. In some ways, we have come full circle where, in the early days of HPTS, we were looking at the crazy low-volume IBM mainframes, assembled into complex systems whose sole purpose was to allow the few very largest enterprises to scale their online transaction systems. These wonderful systems that supported the world’s largest companies in the early days of HPTS were made irrelevant by high-volume silicon, high-volume commodity servers, and open source systems software. The super-optimized server hardware systems were replaced by high-scale clusters of commodity systems available to all customers. The scale of cloud computing where 10s of millions of cores are purchased each year by a single provider returns us to the days of hardware innovation. The volume is there to support the development of general-purpose server processors by a single customer for use by a single customer. The pallet of optimization open to HPTS attendees now starts at semiconductors optimized for the use of a single customer, includes custom servers, custom networking designs, the entire system software stack, custom database systems that aren’t even available on the open market, and all the control software that ties it all together. Just as early IBM mainframes had custom ASICs whose sole purpose was to control the cluster and specialized processors whose sole purpose was to offload I/O from the central processing complex, all these concepts have returned and exist in modern high-scale cloud computing system. This talk focuses on a high-scale cloud operator with 10s of millions of cores deployed annually and the layers of innovation from semi-conductor, through custom servers, custom control processors, and custom networking hardware. We’ll look at what’s made possible by having control of all components in the hardware and software stack and show how many of the innovations of early mainframe processor complexes have returned. IoT at SeaIn an unusual turn around, rather than have the students attending HTPS do poster sessions, Program Chair Peter Alvaro asked some of the long term attendee to do poster sessions. Peter’s thinking on why the inverted poster sessions would be fun:
For my poster session I chose to cover IoT at sea. This is the software system I wrote for our around-the-world boat tour that supported capturing 100s of data points every 5 seconds from sensors all around the boat weather station, fuel levels, main and auxiliary engine data, generator telemetry, navigation and communications systems data. The system supported generator auto-start, remote reporting and control, managing satellite, cellular, and WiFi communications links, and operator alerting. 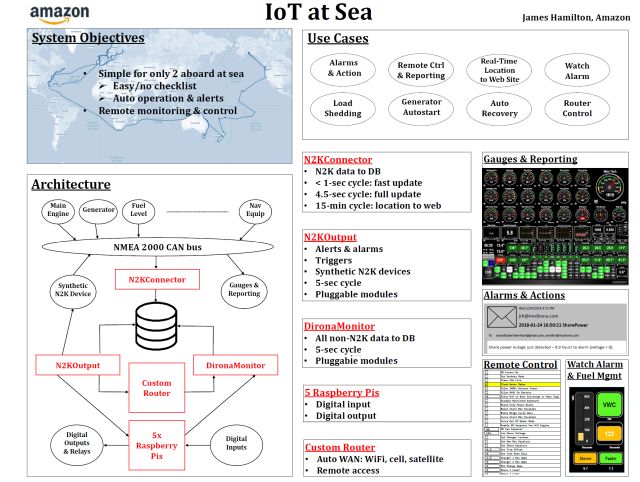
| ||||||||||
| Monday, October 24th, 2022 | |||||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |||||||||||
| 9:11 pm | 2022 NAE Frontiers of Engineering  I introduced the 2022 National Academy of Engineering Frontiers of Engineering conference on September 21st. The National Academy of Engineering was founded in 1964 is part of The National Academies of Sciences, Engineering, and Medicine. The NAE operates under the same congressional act of incorporation that established the National Academy of Sciences, signed in 1863 by President Lincoln. Under this charter the NAE is directed “whenever called upon by any department or agency of the government, to investigate, examine, experiment, and report upon any subject of science or art.” My short summary is the group is made up of some of the best engineers with the purpose of advising the US government on issues related to engineering. I kicked off the 2022 National Academy of Engineering Frontiers of Engineering conference with the transcript below. Welcome to Seattle and welcome to the Frontiers of Engineering Symposium. It’s an honor for Amazon to be jointly hosting this gathering with the NAE. It brings together a diverse mix of leading and emerging engineers representing a wide variety of backgrounds and disciplines from industry, academia, and national labs. Over the years, I’ve found one of the richest sources of innovation in one field is knowing a bit about other fields. In fact, most of what I’ve done over the last 35 years has been found in the cracks between engineering disciplines and between teams. Adjacent teams often find local minima. They need to be speaking with neighboring teams about what’s hard for them and drives cost and what’s easy and makes relatively little difference. For example, conventional datacenter humidity and temperature requirements are set by the server hardware designers. Their focus is on reducing server failure rates and conservative specs are the inevitable result. Data center engineers accept without question the requirements they receive. Both teams are optimizing for their slice of the problem space and each are likely doing good work in their respective areas. But we need investigate the cracks between these two teams by asking the server engineers, what does it cost to design servers to operate at higher inlet approach temperatures and what’s the server mortality rate when operating at higher temperatures? Basically, what’s the cost of you not getting what you want? We can then turn around and ask the data center designers what they can save by raising the building temperature set point. What we find in that crack between those two teams is 100s of millions of dollars and years of new engineering optimizations. It’s lower cost, it’s far better for the environment, and it’s really not even all that challenging from an engineering perspective. What find in the cracks is often very valuable. We just have to look. Every time I get a chance to meet a leader in any field, I jump on it. The best in any field always has something to teach and it’s remarkably how frequently there’s a great idea that is “normal” in one field but relatively untried in another. So, with that backdrop, you’ll not be surprised to learn that I’m excited to be joining you today at the Symposium. There’s gold in the cracks between different fields of engineering, different backgrounds, and different teams. The 4 themes for this conference also really resonate with me.
Thanks for joining us here today and I think we’re all in for an exciting conference. | ||||||||||
| Tuesday, May 24th, 2022 | |||||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |||||||||||
| 12:17 pm | Graviton3 & EC2 C7g General Availability  Today we’re making the AWS Graviton3 processor generally available in the AWS EC2 C7g Instances. Graviton3 and EC2 C7g Instance Type General Availability Video When I joined AWS a bit more than 13 years ago I wouldn’t have guessed we would be designing and delivering custom processors but scale supports innovation at every level. We are now a leading semiconductor design house, we do custom servers, custom storage racks, our own networking equipment, AWS optimized hypervisor and operating systems, and of course the AWS services above. I’m particularly proud of the innovations we’ve made in silicon over the years. We launched the first-generation Graviton CPU back in 2018 and it delivered significant cost savings for scale-out workloads. Only 1 year later we followed up with Graviton2 delivering up to 40% better price-performance than comparable X86 processors. And today with the announcement of the Graviton3-powered C7g instances, we deliver even higher performance for compute-intensive workloads. AWS EC2 C7g General AvailabilityToday we announce the general availability of C7g. These are the first EC2 instances powered by the latest generation Graviton3 processor. C7g provides up to 25% better performance than the predecessor C6g, which already offered up to 40% better price-performance over comparable x86 instances. It’s only been two years since we launched Graviton2, and I believe that the 25% generational performance gain we’re delivering in Graviton3 is a big step forward for customers. The AWS Annapurna team is behind all 4 of our semiconductor product lines and they continue to take on aggressive goals, work through the challenges that inevitably come up during large engineering projects, and yet still they reliably hit schedules and consistently over-deliver on performance. Graviton3 is a big step forward for us. Graviton3 DetailsComparing Graviton3 to our previous generation processor, we see up to 2x better floating-point performance, up to 2x faster crypto performance, and up to 3x better machine learning performance. It’s based on the Arm Neoverse-V1 core where each core has a private 64KB L1 as well as a private 1MB L2 cache. Graviton3 is the first server in the AWS fleet to support DDR5 memory and it delivers 50% more bandwidth than the previous generation DDR4. Throughout the Graviton program, we have always focused on the importance of memory bandwidth to real-world application performance and, with Graviton3, we continue that focus by offering 8 lanes of DDR5 per socket. Each Graviton3 package has 55 billion transistors and is made up of 7 chiplets, 1 main compute-die housing all the cores, 4 DRAM controller dies, and 2 PCIe dies. We elected to implement Graviton3 as a multi-chip module to reduce cost and to increase yields as the size and complexity of modern processors continues to grow. This improves manufacturing economics but it also allows future Gravitons to be fabricated using a leading process node while, at the same time, some of the less rapidly evolving I/O components, for example the PCIe dies, can remain unchanged. Unlike some contemporary server CPUs, the Graviton3 compute die is monolithic where all 64 cores are on a single die. This allows us to deliver all 64 cores with uniform memory access times rather than exposing application developers to the complexity of managing different local and remote memory access latencies. Graviton3 memory latency is uniform for all cores over all memory. AWS C7 Instance DetailsLooking “logically” above Graviton to the C7g board design, each Graviton3 motherboard supports 3 servers. And, you can see on the slide, all three servers are supported by a single Nitro processor further improving overall cost and efficiency. We exploit the power efficiency of Graviton3 to cost effectively deploy 3 servers per Rack Unit (1.75“) without requiring exotic or expensive cooling solutions. This reduces costs but the energy efficiency of Graviton3 also helps customers reduce their carbon footprints. Graviton3 instances use up to 60% less energy for the same performance than comparable EC2 instances. Graviton3 Customer FeedbackGraviton3 has the performance needed for modern compute intensive applications such as gaming, video encoding, machine learning, and high-performance computing while also delivering the power-performance and price-performance customers seek for less demanding, general-purpose workloads. We announced a preview of C7g at the AWS re:Invent conference last year, and hundreds of customers have since benchmarked their workloads. Let look at just a few of examples. Twitter ran a number of benchmarks representative of their workloads, and found that C7g delivered up to 80% better performance than the previous generation C6g. In addition, they reported a reduction in tail latency of as much as 35%. Formula 1 ran their Computational Fluid Dynamics workloads on C7g and found them to deliver 40% better performance than C6gn. Honeycomb.io, an early adopter of Graviton, saw a 35% performance improvement and a 30% reduction in latency compared with C6g for their telemetry ingestion workload. It’s exciting to see such great results from our customers and I’m looking forward to seeing more data points like these now that C7g is generally available. Launch Video: https://youtu.be/QKo7yDAn75k More detail on Graviton: aws.amazon.com/ec2/graviton | ||||||||||
| Saturday, August 27th, 2022 | |||||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |||||||||||
| 3:54 pm | A Short History of AWS Silicon Innovation  Why would a cloud services company design and deploy custom semiconductors? It definitely wasn’t where I expected we would end up when I joined AWS in 2009 but it’s a decision that has just kept delivering for our customers. It’s been 10 years since those early ideas and, in reflecting on what the team has delivered over this period, I thought it would be fun to walk through some of the history that has led to us deploying more than 20 million AWS designed ASICs. In the video below, I go back to 2012, introduce some of the key players, the early ideas that got us started, the motivation behind those early decisions, what was delivered, and how we continued to grow the semiconductor investments at AWS. History of Silicon Innovation at AWS: https://www.youtube.com/watch?v=zfjFHa5w | ||||||||||
| Tuesday, November 30th, 2021 | |||||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |||||||||||
| 10:02 pm | Xen-on-Nitro: AWS Nitro for Legacy Instances  On August 25, 2006, we started the public beta of our first ever EC2 instance. Back then, it didn’t even have a name yet, but we latter dubbed it “m1.small.”. Our first customers were able to use the equivalent of 1.7 GHz Xeon processor, 1.75 GB of RAM, 160 GB of local disk and 250 Mb/second of network bandwidth for just 10 cents an hour whenever they needed it and for as long as they needed it. Under the hood, we used the Xen hypervisor to provide these virtual machines or instances as we call them. Customer adoption exceeded our wildest expectations and over the next 10 years, EC2 launched 27 more instance types based on the Xen technology. Over the years, many successful businesses where built on top of EC2 and we got a lot of valuable feedback that helped us to evolve and improve our virtualization technology and our instance types. However, there were a few things that we just could not address with only incremental software improvements. These early instances were using virtualized or emulated devices that abstracted the instance from the underlying hardware. It worked very well, but the overhead kept growing as networking and storage speeds increased. We needed to reserve multiple CPU cores from the physical server to emulate these storage and networking devices. That was computing power that we weren’t able to offer to our customers which particularly impacted our largest instance types. If you are only using a couple of cores it’s not much of a problem, but if you are running an HPC or data intensive workload that required as many cores as we can offer, those cores lost to overhead network and storage emulation really make a difference. Our customers wanted a solution that would securely support them using every core fully and an important subset of customers needed bare metal support (no hypervisor) which we would only offer if fully secured. On November 6, 2017, we announced AWS Nitro System, the backbone for our new virtualization technology. Nitro is the EC2 hardware offload technology we developed to support high performance networking with hardware offload and optional O/S bypass, low latency storage with hardware offload, NVMe local storage, and more advanced security features. See AWS Nitro System for more detail on the Nitro system. C5 instances where the first EC2 instance types fully supporting Nitro and, since then, we have launched 45 more instances based on the Nitro technology. Besides the vastly improved storage and networking performance made possible through hardware offload, the Nitro technology also allowed us to even further increase the security of our virtualization technology.
All of these innovations enable us to continue to offer many of our older instance types well past the lifetime of the original hardware. Starting in 2022, customers launching M1, M2, M3, C1, C3, R3, I2 and T1 instances will land on Nitro supported instances hardware and existing running instances will also be migrated. Whether the instance runs on the original hardware or newer Nitro hardware will be fully transparent to customers. Workloads will continue to run just like they have run before. Later we will also support C4, M4, R4 and T2 instance types. We did this work because we wanted to provide customers the ability to continue to run their legacy workloads unchanged allowing them to focus their valuable engineering resources moving their respective businesses forward rather than migrating between instance types. It would certainly have been easier for us to just send out a retirement notice for these legacy instance types but, at AWS, we work hard to avoid unnecessarily taxing customers. Xen-on-Nitro is us walking the extra mile to ensure customers can completely focus on innovation and making their businesses successful rather than migrating to newer instance types. | ||||||||||
| Wednesday, September 1st, 2021 | |||||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |||||||||||
| 3:31 pm | Happy 15th Birthday EC2!  August 25th, 2021 marks the 15-year anniversary for EC2. Contemplating the anniversary has me thinking back to when I first got involved with cloud-hosted services. It was back in early 2005, about a year before S3 was announced, and I was at a different company working on a technical due diligence project for a corporate acquisition. I’ve always enjoyed assessing startups. It’s a challenge to dive in with limited time and both learn how smart engineers have innovated to solve interesting problems and also try to find any technical blind spots that may have slipped past. In this 2005 example, the company under review was a cloud-hosted service. We decided to go ahead with the acquisition, it became a wholly-owned subsidiary, and I took over as General Manger. Operating this early cloud service taught me two lessons fairly quickly:
The lesson here was that cloud services were instantly popular with customers even though these early efforts left much room for improvement. That’s exactly what I look for when considering technologies to personally focus upon, and I’ve worked exclusively on cloud services since 2005. A bit less than a year after that, S3 was announced and the pricing just seemed crazy. I’d worked in database and storage all my life, thought I knew what’s possible, and S3’s pricing simply wasn’t. 15 cents per GB per month was instantly game-changing and there are now over 100 trillion objects stored in S3. Around that same time, I wrote a good-sized S3 application and tested it extensively prior to demoing to the CEO and CTO of the company where I was working at the time. Over the course of a month of test and development, my AWS bill came in at a nearly invisible $3.08. Around the time I wrote that first S3 app, EC2 was released into beta. This was back in August 2006. I couldn’t get into the early beta program, but wanted to learn more, so I started attending AWS customer events in the Seattle area. I was amazed both by the number of people in the room at these early AWS events and also by the momentum already building behind EC2. Customers were running their entire businesses upon it. EBS didn’t yet exist and EC2 storage was neither redundant nor fault tolerant. And yet creative customers were innovating with a wide variety of recovery mechanisms to avoid or minimize potential data loss from a disk fault. Customers were finding the speed of innovation opened up by EC2 so empowering for their businesses that they could live with the early limitations and the lack of durable storage options. Between the low cost of EC2 and the ability to scale at will, huge customer momentum was already building just months after the start of the beta program. Even back then, it was already super clear that hosted services were the future and, if I wanted to be part of the next generation of server-side computing, I needed to be part of AWS.
When I joined AWS it was a startup but the paces remains as fast as ever and I’m still learning every day. | ||||||||||
| Sunday, August 22nd, 2021 | |||||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |||||||||||
| 5:24 pm | Tesla Project Dojo Overview  A couple of days back, Ganesh Venkataramanan, leader of the Tesla Dojo project, announced the Dojo machine learning training system. It’s an unusually network rich, power dense, and memory light design. I’ve summarized the architecture of the system below but I found three aspects of the system particularly interesting:
Looking closely at the pictured roughly 1 sq ft training tile above, the top is an aluminum plate presumably to mate up against a phase change liquid cooling system. It’s a minor point but it’s a nice touch to put the VRDs( Voltage Regulator Down) directly on tile allowing them to deliver an unusually high 52V to power the tile. Given the 15kW draw, that’s still a 288A draw at 52V. 354 Functional units are combined in a single 645 mm^2 D1 chip. 25 D1 chips form a multichip module called a training tile and 12 training tiles form a rack and 10 racks for an Exapod. Functional Unit:
D1 Chip: 645mm^2
Training Tile: ~1 sq ft
Cabinet (rack):
Exapod: 10 racks
It’s quite an innovative system. More details at: Tesla’s AI Chip Revealed | ||||||||||
| Wednesday, April 21st, 2021 | |||||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |||||||||||
| 7:58 am | Reinventing Operational Resiliency  The cloud helps organizations achieve unmatched resiliency at scale. This is a quick write-up I did on the AWS approach to resiliency: Reinventing Operational Resiliency. A talk I did at re:Invent focused on AWS infrastructure: Tuesday Night Live with James Hamilton. Graviton AWS Arm server announcement: M6g, C6g, and R6g EC2 instances powered by Graviton2. | ||||||||||
| Wednesday, March 11th, 2020 | |||||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |||||||||||
| 10:40 am | Anandtech on AWS Graviton2 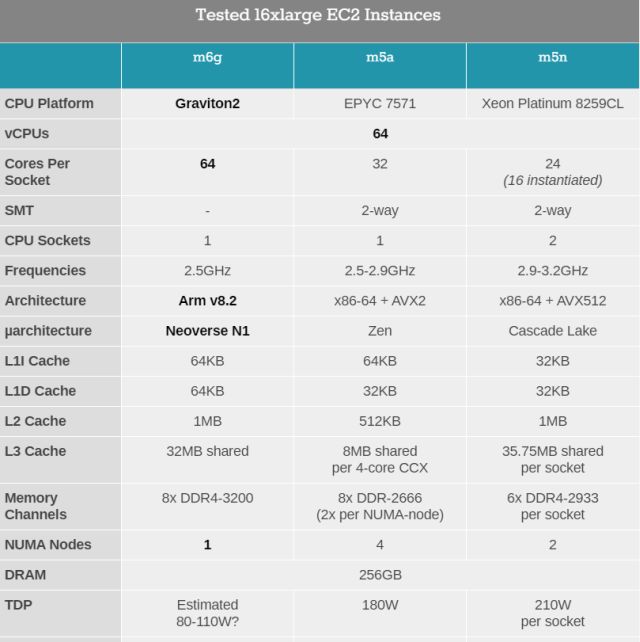 Yesterday, Anandtech published what is, by far, the most detailed write-up on the AWS Graviton2 processor. In this article the author, Andrei Frumusanu, compared the Graviton2 with the AMD EPYC 7571 and the Intel Platinum 8259CL. Worth reading. From Anandtech: Amazon’s Arm-based Graviton2 Against AMD and Intel: Comparing Cloud Compute | ||||||||||
| Friday, March 20th, 2020 | |||||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |||||||||||
| 10:16 am | How Complex Systems Fail  This is a simple little article that’s worth reading. I don’t agree with every point made but all 18 are interesting and every one of them leads to some introspection on how it compares with the situations I have come across over the years. It’s nice and concise with unusually good reading time to value ratio. Thanks for Rodolfo Velasco for pointing this article out. Somewhat related, some time back I wrote up some of what I’ve come across over the years on how to avoid systems failing: | ||||||||||
| Tuesday, March 24th, 2020 | |||||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |||||||||||
| 10:07 am | Human Race Priorities?  I was recently in a super interesting discussion mostly focused on energy efficiency and, as part of the discussion, the claim was raised that Nobel Laureate Richard Smalley was right when he said that Energy was the number one challenge facing our planet. I’m a pretty big believer in energy efficiency and the importance of renewable energy so, without having read exactly what Smalley said, I agreed it was a very important area. With low cost energy, we can make water from sea water. If the low cost energy source is a low cost and clean source, the global warming problem could be addressed. I definitely can see some of why he might rank it number 1 but I wasn’t sure I would. I wanted to dig deeper into what Smalley said but before thinking through his list of the top problems for humanity, I thought it would be worth building my own list. I find that the best way to know what your current priorities really are is not to think too hard about it and just quickly write them down. Your list might need some re-ordering and you might find you need to add one or two upon deeper reflection but the “write it down fast” approach isn’t a bad way to understand your current priorities best. If you feel like it, write down your list of 5 to 10 of the biggest problems you think face humanity. You may miss some in just diving in without doing any research but it does tell you your current and most immediate priorities. Here’s my list:
For me, energy isn’t number one even though it’s right near the top of what I work upon most. Population growth appears to be the most dominant problem and, in my view, a solution there would reduce the magnitude of many of the rest of my top 5 greatly and some would no longer be big issues. For example, a non-renewable energy economy isn’t ideal but, with a small population would work fine for a very long time. For comparative purposes, I looked up Richard Smalley’s list of top 10 problems facing humanity in 2004:
Smalley has a good list and it’s worth thinking through where it matches and where it differs from yours. For comparison, here is a closely related top 10 from the UN High-Level Panel on Threats, Challenges, and Change in 2004:
My number one, human population, didn’t even make the list for this group and wasn’t near the top of Smalley’s list. I personally have population at the top of my list because so many of our problems have the resource consumption of 7.7B (heading quickly towards 10B) at the core. Looking at many unrelated and difficult issues facing humanity, our population size in absolute numbers is an accelerant for many of them. By analogy, population is not always the cause of the fire but population does feed it. | ||||||||||





LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose.