Add this feed to your friends list for news aggregation, or view this feed's syndication information.
LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose.
| Tuesday, January 13th, 2026 | |||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |||||||||
| 4:13 pm | Social Foundations of Cryptography: Autumn School We‘re hosting an Autumn School in London, UK, from 15 to 17 September 2026, to bring together ethnographers and cryptographers to discuss ways in which the two fields can be meaningfully brought into conversation. This is also the premise of our Social Foundations of Cryptography project: to ground cryptography in ethnography. Here, we rely on ethnographic methods, rather than our intuition, to surface security notions that we then formalise and sometimes realise using cryptography. Our intention is to ‘flip’ the typical relationship between the computer and social sciences, where the latter has traditionally ended up in a service role to the former. Rather, we want to put cryptography at the mercy of ethnography. But how do we do this? How do we as cryptographers interact with and make sense of ethnographic field data? How can we refine, improve or extend this interaction? What obstacles do we face when we make cryptography rely on ethnographic data which is inherently ‘messy’? How do we handle that cryptographic notions tend to require some form of generalisation but ethnographic findings can only be particular? How do ethnographers retain the richness of ethnographic field data in conversations with cryptographic work? Indeed, our project has already highlighted some limitations of our approach. It has brought to the fore concrete challenges in ‘letting the ethnographic data speak’ while still making it speak to cryptography. The Autumn School is an opportunity to explore these questions jointly across ethnography and cryptography, through a series of talks, group discussions and activities. We say a bit more about the programme and registration for the Autumn School here. | ||||||||
| Monday, January 5th, 2026 | |||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |||||||||
| 11:49 am | Lecturer (≅ Assistant Professor/Juniorprofessor/Maître de conférences) in Cryptography at King’s College London 2026 We are looking to recruit a lecturer in cryptography at King’s College London to work with us within the cybersecurity group: I think it’s fair to say we got strong expertise in lattice-based and post-quantum cryptography here, as well as in protocols with an applied cryptography bent. Check out our publications to get a better picture. For this position, we do not aim to strengthen lattices further, but rather aim to strengthen other areas of cryptography, e.g. protocols, applied cryptography, cryptography in the wild or theory. The application deadline is somewhat far into the future (5 March 2026). So, if you like, there’s time to reach out to discuss or even to come visit us to check us out. We’d appreciate any help in spreading the word.
| ||||||||
| Wednesday, August 27th, 2025 | |||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |||||||||
| 10:55 am | Internship Position on the Lattice Estimator Eamonn and I are looking to hire an intern for four months to work on the Lattice Estimator. The internship will be based at King’s College London and is funded by a gift from Zama. We are ideally looking for someone in a PhD programme also working on lattice cryptanalysis who is happy to interrupt their studies for a few months to help us improve the estimator. We’re offering a salary of roughly £4,400 per month before tax.(*) This would involve reviewing and closing tickets, reviewing the literature for what is currently missing from the estimator to add it and reviewing the code already there for correctness. If you’re interested, please get in touch with Eamonn Postlethwaite <eamonn.postlethwaite@kcl.ac.uk> and me Martin R. Albrecht <martin.albrecht@kcl.ac.uk> to discuss this position. We are somewhat flexible on timing. (*) I am writing “roughly” here because internships are not a common thing at King’s College London. In particular, the position would formally be through the King’s Talent Bank and crunching the numbers, the monthly salary ends up being roughly the figure stated above. | ||||||||
| Sunday, August 24th, 2025 | |||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |||||||||
| 11:00 pm | Postdoc Position in Lattice-Based Cryptography We are recruiting a postdoc to work with us on “practical advanced post-quantum cryptography from lattices”, the title of my ERC selected, UKRI Frontier Research funded project:
So when I say “advanced”, I don’t mean Functional Encryption or Indistinguishability Obfuscation, but OPRFs, Blind Signatures, Updatable Public-Key Encryption, even NIKE (sadly!). I’m quite flexible on what background applicants bring to the table
All of that is in scope. If in doubt, drop me an e-mail and we can discuss.
Here is some key data of the position:
As mentioned in the job ad, the postdoc will sit in the Cryptography Lab at King’s (which itself is part of the Cybersecurity Group). Currently, the cryptography lab are:
I’d appreciate if you could help me to spread the word to people who might be a good fit for this position. Any questions, drop me an e-mail. Apply here. | ||||||||
| Saturday, June 14th, 2025 | |||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |||||||||
| 12:12 pm | On the Virtues of Information Security in the UK Climate Movement Our paper – titled “On the Virtues of Information Security in the UK Climate Movement” – was accepted at USENIX Security’25. Here’s the abstract:
Here, “we” is Mikaela Brough, Rikke Bjerg Jensen and me. Mik is doing a PhD (with Rikke and me) on how members of environmental social movements navigate their information security. She is an ethnographer and her previous degree was in social anthropology. Rikke is a professor in the Information Security Group at Royal Holloway, University of London. She also is an ethnographer and heads up the Ethnography Group there. If you are one of the handful of people who actually read this blog (hi!), you might wonder what the heck I did on that paper: I am a cryptographer but this paper is neither cryptography nor in a closely related field. Rather, it is a social science paper throwing up methodological questions about social science (granted, in the field of information security). Thus, it makes immediate sense that two trained and qualified social scientists – Mik and Rikke – would write such a paper; me, not so much.
Indeed, this work – for good reason – breaks from the cryptographic and mathematical convention of naming authors in alphabetical order. The AMS explains this mathematical convention as follows (I’ll return to this below):
Now, ethnography is a method that is mostly known for being slow, long, expensive, extensive and immersive. Ethnography insists on “fieldwork” which literally means to do a lot of work in the field. In particular, researchers spend extended periods of time (think months) with the groups they study. As such, this method is particularly well-suited for settings where you have to expect that the answers people give might differ from their lived experience. This might be because they hardly step back to reflect on this lived experience or this might be because those questions are loaded for some reason. Information security is certainly a loaded question, touching on people’s self-images about whether they’re “qualified” to have an opinion, for example. You will find this reported in many prior qualitative studies in information security where many participants actually were themselves security trainers or at least attended security trainings; but it is the people who think “information security is not for me” who we might want to reach and understand. This part of the research, the work in the field or the “data gathering”, was done by Mik, the fieldworker in this project. Hence, Mik is listed as the first author. If you opened our paper, you’ll also find a “positionality statement” (the first one I have ever written): who we are, how we are perceived and what are some general outlooks we have. Such statements are necessary in this line of work because the fieldworker’s data will be shaped by how the participants read them. This doesn’t mean the data is biased or wrong but it is particular: some people will open up to you if they read you a certain way, others only if they read you in a different way. Similarly, some stuff will catch your attention, some stuff will not. We cannot really speak of “bias” here because there is no neutral ground truth to fall back to, every study will be shaped by the fieldworker and the job of the analysis is also to account for this. 1 After the fieldwork come several analysis cycles. First, only by the fieldworker to produce some synthesis of the data to discuss with the rest of the research team; well, in our case, because most ethnographic studies, in contrast, have a research team of size one. For example, for methodological and ethical reasons, I never saw any raw data from Mik’s fieldwork. In some sense, I could only interact with Mik as an oracle who may or may not have an answer to my queries about the data. In any case, in a multi-stage process (Rikke and Mik did coding first, I got involved in a later stage of the analysis), we eventually transitioned to collective analysis, where the three of us would discuss Mik’s initial findings, interrogate them, iterate over them, have ideas how to code/group them and see how they might relate to information security. This process took several months and could take the form of someone suggesting “I think the data suggests that X” to then later hear “sorry, the data does not actually suggest this, rather Y”, etc. Thus, this part of the analysis was quite interactive with us discussing the data and tentative findings. An example of what this sort of process might throw up is our finding regarding autonomy and necessity in the paper. In our discussions we noticed this tension, Mik went back through the data to see if there was more on this “theme” and we then refined our understanding of this tension. Thus, this part of the research, the analysis, is closer to the culture the AMS described in the quote above. I could not attribute several findings to Mik, Rikke or me individually, because here too “which person contributed which ideas is often meaningless because the ideas gr[e]w from complex discussions among all partners.” This is what is meant by “reflexivity” in the paper. In a more positivist strand of qualitative social science research, the authors would instead aim for what is called “inter-coder reliability”. This is based on the idea that if several people draw the same conclusion from the same data, this conclusion is not shaped (so strongly) by their subjectivity. This, on the one hand, will only be of limited success because of the selection of who looks at this data and with what questions in mind. On the other hand, and this is the point I’m going for here, it limits what you can get from the data. Us discussing these findings over many weeks produced our findings, including the one that produced our title, i.e. that in this setting “security” served as the material to express your activist virtues which trumped operational security concerns. An illustration of this iterative process is how the focus shifted as we went on. The initial plan here was for my involvement to be similar as it was in “Collective Information Security in Large-Scale Urban Protests: the Case of Hong Kong”. There, Rikke had conducted interviews with participants of the Anti-ELAB protests of 2019 and our discussion contrasted our findings with established security notions also in cryptography, such as forward secrecy and post-compromise security. Thus, when Mik, Rikke and I set out to collaborate on the analysis here, we had something like this in mind. As indicated above, it did not play out this way and the data lead us to discuss rather different questions in the end. In some sense, this “reflexivity” resembles more the approach taken in mathematics and cryptography than “inter-coder reliability” would. After all, we routinely discuss and co-write the proofs for our theorems and do not maintain the standpoint: if two people arrive at the same proof, it will be correct. Rather, we criticise each other’s mistake and fix them to arrive at hopefully a correct proof within the research team. Overall, and that’s a point we also make in the paper, ethnography is not merely a different data gathering method but also requires a different analytical approach to account for the data gathered. The data will be richer than with other methods but it will also be more particular. Put in our jargon, ethnography is an approach to establish ∃ statements but it will not tell you ∀. I’d claim we often want the former in information security research: “What does security mean in this context and how does that relate to our established notions?” “What are the threats?” “What are the security goals?” We can argue about how these findings generalise after, but first we should establish what it is that may or may not generalise. Using a finding from our paper, we found that those we – information security researchers – would typically interview about the security practices of a particular group under study – i.e. those who would self-select to respond to us – were in a somewhat entrenched conflict with other members of their movement over being a good activist. Thus, if we interview this particular set of people from a particular population, we are prone to end up with ideas for design that might end up being rejected outright by others. We can say this with some confidence about some parts of the UK climate movement and I suspect a similar dynamic can be observed elsewhere, but our data does not speak to this. What we can say, though, is that it is worth finding out. Footnotes:1 </p>
This also partially explains why the positionality statement in our paper covers also Rikke and me, and not just Mik. For Rikke and me, it’s not so important how we’re read – we didn’t do the fieldwork – but it matters to inform the reader what catches our attention, how we looked at the data and what we would consider worthwhile pulling out. This is important because of the second piece of the puzzle: we cannot publish the actual underlying data: we would never get ethics approval for this, nor would we want to. As a consequence, the reader needs to rely more on us than in, say, cryptography, where we can usually publish our underlying data if there is some. | ||||||||
| Tuesday, April 15th, 2025 | |||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |||||||||
| 12:26 pm | 10 June: Jean-François Blanchette Talk in London Together with Rikke Jensen, we’re organising a talk and discussion with Jean-François Blanchette in London on his book Burdens of Proof, which has been tremendously influential on our thinking around the social foundations of cryptography. TitleYeah yeah yeah he has a thing about steganography: Mathematical formalism, disciplinary boundaries, and cryptography’s design culture Blurb
https://x.com/martinralbrecht/status/179 What does it take for cryptographic protocols to become credible outside the narrow world of mathematical proofs? In Burdens of Proof (MIT Press, 2012), I examined this question in the early 2000s, as cryptography began to move into legal, bureaucratic, and professional domains. Drawing on fieldwork during the reform of the French Civil Code and its aftermath, the book traced how digital signatures were translated into legal and institutional practice—not through seamless adoption, but through negotiation, reinterpretation, and friction. It argued that mathematical guarantees alone were never enough: to function in the world, cryptographic systems had to be made intelligible, authoritative, and usable within existing structures of trust and responsibility. This talk revisits the book through the lens of what the field itself historically sidelined as it sought great institutional credibility and social relevance. Steganography, the art of hiding in plain sight, plays a central role here—not only as a technique excluded from the modern cryptographic canon, but as a pointer to everything cryptography has tended to avoid: context, embodiment, ambiguity, and the materiality of technical systems. Paying close attention to has been excluded and avoided, we can better understand the contradictions, assumptions, and imaginaries built into cryptography’s design culture. Speaker BioJean-François Blanchette serves as director of the Responsible Data Governance program at the École nationale des sciences de l’information et des bibliothèques in Lyon, France, and is Research Professor Emeritus in the Department of Information Studies at UCLA. He is currently writing about the future of personal digital collections in the age of streaming media. Venue Royal Holloway (Central London Campus) Date/TimeTuesday, 10 June, 2pm to 4pm RegistrationRegistration is not necessary but we’d appreciate if you could let us know if you’re planning to attend, so we can get a sense of numbers to expect. | ||||||||
| Sunday, March 16th, 2025 | |||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |||||||||
| 11:11 am | Analysis of the Telegram Key Exchange Together with Lenka Mareková, Kenny Paterson, Eyal Ronen and Igors Stepanovs, we have finally completed our (first, formal, in-depth, computational) analysis of the Telegram key exchange. This work is going to be presented at Eurocrypt 2025 in Madrid.
Let me expand a bit on what “the Telegram key exchange” means, here. Telegram uses its bespoke MTProto protocol to secure its client-server communications. The cryptographic core of MTProto consists of a key exchange protocol and an encryption protocol. A few years back we had already analysed the encryption protocol. Although that prior work focused on the encryption protocol, we also uncovered a vulnerability in Telegram’s key exchange protocol which Telegram fixed in response. We now completed a formal analysis of Telegram’s key exchange protocol and, in a sense, established that this fix works – but with many caveats. Broadly, we establish that Telegram’s key exchange protocol provides some standard security guarantees. These guarantees, however, rely on several “non-standard” assumptions that appear to be necessary because of the brittle and ad-hoc nature of how Telegram’s protocol was designed. Below, I reproduce a section from our paper which discusses this. I have edited it to make it somewhat work without the context of the entire paper. The reason why I pulled out this section for this blog post is because we are also trying to convince practitioners to design their protocols to be – at least – “analysis friendly” (ideally, they’d come with such an analysis directly). Friends don’t let friends deploy a cryptographic protocol without a formal cryptographic analysis.
In theory, the design of a cryptographic protocol has the sole purpose of achieving the protocol’s security goals efficiently. In actuality, however, to achieve this goal it must also achieve the goal of allowing at least a sufficiently motivated expert to convince themselves that the protocol achieves these goals. In other words, the central insight of what is commonly referred to as “modern cryptography” is that a cryptographic design is also tasked with being easy to reason about. A fundamental paradigm of achieving this goal is modularity, where different components of the design can be reasoned about in isolation and then (generically) composed to establish overall security guarantees. This modularity is typically achieved by relying on building blocks that provide strong security guarantees on their own (as opposed to only and potentially in specific compositions) and by breaking the dependency between different components of a protocol by avoiding re-use of secret material. Telegram’s failure to achieve this design goal is the root cause for the limitations and complexity of our proofs and our seeming need to reach for unstudied assumptions on cryptographic building blocks than would otherwise be necessary. Below, we discuss these issues and highlight several of the main Telegram design choices and their effect on our proofs of security. We begin with mere complications, then move on to limitations and seemingly necessary ad-hoc assumptions. We finish by briefly recapping our hypothetical attack. We also discuss design choices that led to these issues and note that the same design choice often lead to several different difficulties for arguing for the security of Telegram, leading to necessary repetitions in what follows. Proof complicationsSeveral design choices made by Telegram introduced many otherwise avoidable complications in our proofs. Lack of a suitable key schedule. Some value Similarly, two values called ax and aid are both the result of a single SHA-1 call, which prevents the proof from manipulating them independently. Use of a (truncated) weak hash function. Although more efficient and secure alternatives such as SHA-256 and SHA3 exist, Telegram also uses the now mostly deprecated SHA-1 algorithm. SHA-1 has been shown not to be collision resistant via practical attacks. The use of SHA-1 to compute the key confirmation hash h complicates our proof. If a collision-resistant hash function had been used, we could have relied on this property in the first step of the proof to establish public session matching. Further, the output of the SHA-1 hash is truncated to only 64 bits. This prevents us from using a simple PRF notion due to easy attacks even in the one-time PRF setting. Short session identifiers. The 64-bit value output of the above-mentioned truncated hash function is aid. This value is used by the Telegram servers to identify sessions. On the one hand, this imposes a hard bound of Lack of ciphertext integrity. Telegram’s MTProto relies on a custom mode of operation composing IGE-mode and SHA-1. The composition achieves neither INT-CTXT nor IND-CCA. Had an established authenticated encryption scheme or an unforgable MAC been used, this would have simplified the proof in allowing us to declare the Diffie-Hellman shares authenticated and using the ciphertext/mac tag as part of our session identifiers. This in turn would have enabled public session matching based on transcripts. Reliance on plaintext checking. Our proof relies on the correctness of a complex parsing behaviour and the checking of various plaintext headers and nonce values. That is, we also could not achieve modularity separating cryptographic operations and higher-level protocol operations. In particular, to prove soundness we require that all message headers are different, so there cannot be confusion about which state the protocol is in and role confusion is also ruled out. Limitations of our proofThe main limitation of our proof is that we do not model the actual connection between the initial run of the key exchange and subsequent runs of it (see paper for details). Moreover, our model does not allow for generic composition of our theorems about the key exchange and existing results about the encryption protocol. This is due to several design choices made by Telegram that prevent simple composition of the security proofs. Key dependence. While being composed of multiple stages, the key exchange protocol does not derive the keys in the different stages independently. This prevents us from using general composition results on key exchanges and encryption protocols to argue about the security of the key exchange when used in conjunction with the encryption protocol. Another example is the fact that the Diffie-Hellman value in a sub-protocol is used to internally derive ax and aid, and is used afterwards as an encryption key ak. Instead, if the DH value had been used as an input to a KDF to derive ax, aid and authkey as (computationally) independent keys, a composition result would be more feasible to achieve. Public key reuse. We do not model the fact that the public key pk of the server is used in several sub-protocols. To model this, a proof would have to consistently update it across two different games simultaneously. Using different independent keys would have allowed us to treat the two protocols separately without essentially assuming the co-dependence away. Lack of key confirmation. We were unable to prove key confirmation for one sub-protocol and only proved key confirmation for the server for the full protocol. Key confirmation would have been possible if h was produced using a secure MAC. Direct use of non-uniform key material. MTProto uses bits of the agreed DH values directly as key material instead of using them as an input to a key derivation function. However, the existing proof for MTProto assumes a uniform key distribution. This prevents us from composing our results with those prior results. Moreover, this forces us to use a session key distribution for some stage which is not the uniform distribution on strings of a given size. Retry handling. In general, it is difficult to reason about the security of a protocol without knowing the total number of exchanged messages. For example, the security bound for INT-PTXT depends on the number of encryption and decryption queries, which in turn depends on the number of retries. Two aspects of the protocol design prevent us from making an argument that the number of retries would be bounded in practice. First, there is a question of preventing adversarially-triggered retries: this would necessitate showing that some custom hash function outputs are unforgeable, which is not possible due to its short input length. Second, even if the adversary was not able to directly manipulate the flow of the protocol, it remains in control of creating new sessions, which in turn influences the size of each server’s set of known sessions that determines the likelihood of an honest retry. Thus, we were forced to assume a maximum retry number. Reliance on unstudied assumptionsIn our paper, we describe several unstudied ad-hoc and new assumptions that we used in our proofs. These assumptions could have been avoided if collision-resistant hash functions (e.g. SHA-256 or SHA3) had been used instead of SHA-1 and if proper key derivation functions had been used. We can view these assumptions as part of two groups, based on their plausibility and impliciations if they were invalidated. The first two (4PRF, 3TPRF) are lower-level, expressing a pseudorandomness property of SHACAL-1 (the block cipher inside SHA-1): they appear plausible due to the large key length of SHACAL-1, but symmetric cryptanalysis would be needed to determine the concrete reduction in advantage compared to the known results on SHACAL-1 without leakage. The remaining three (SPR, UPCR, IND-KEY) are higher-level, expressing properties of SHA-1 that are variants of standard assumptions or more novel. However, it appears that breaking either of these would not be sufficient to break the key exchange protocol; there exist versions of these assumptions which if broken would be sufficient to break the protocol, but they place even stricter constraints on the adversary. A hypothetical attackWeak channel binding. We also describe an attack on client authentication that is based on the way that a new temporary key is bound to the long-term authentication key ak. The attack exploits the fact that the Telegram server used to not verify the expiration time sent in the binding message. Although Telegram has addressed this specific issue by enforcing the check, the design choice to rely on such checks for session binding is brittle, and its security depends on nuanced details related to the way session key management and expiration are implemented. Instead, more robust cryptographic approaches can be used to bind between the sessions that generate the new temporary key and ak. For example, one approach is to calculate a MAC over the transcript of the current session’s handshake using a key derived from ak as the MAC key. | ||||||||
| Saturday, March 1st, 2025 | |||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |||||||||
| 11:01 am | Rerandomising LWE Our work, titled Hollow LWE: A New Spin — Unbounded Updatable Encryption from LWE and PCE, is now available on ePrint and will be presented at Eurocrypt 2025 in Madrid in May. It is joint work with Benjamin Benčina and Russell W. F. Lai. The main technical contribution is a new approach – a new spin, haha, we’re funny – to rerandomising LWE public keys. Roughly, the security goal here is that even given the rerandomised secret key, an adversary should not be able to distinguish the original LWE public key from uniform (in the appropriate space).
Consider the inhomogeneous dual-Regev public-key encryption scheme, where the secret key is a short vector The current paradigm of rerandomising such public keys has been to add some small random noise Our main idea is to instead take a random signed permutation matrix Thus, we combine LWE with ideas around the Lattice Isomorphism Problem (LIP). Note that LIP over However, SPCE is easy for random codes due to so-called “hull attacks”, and we thus have to limit ourselves to public keys A code has hull dimension In the paper we show that LWE with respect to such matrices It is worth noting that while we use signed permutations in our construction, the security of our construction relies on Permutation Code Equivalence (PCE), where The reason for relying on PCE is that we need to plant a code equivalence instance when arguing that our public key remains pseudorandom even given the rerandomised (public-,secret-)key pair. In order to plant a challenge code equivalence instance – which consists of two matrices which are either equivalent or not – we need to take such an instance and turn it into a dual-Regev public key consistently. Relying on PCE allows us to start from We use these techniques to build an updatable public-key encryption scheme. The performance of this scheme is not great yet, but its parameters do not grow with the number of updates supported, i.e. it supports an unbounded polynomial number of updates. We are working on ideas to improve performance, see the Open Problems section of our paper for more details. | ||||||||
| Tuesday, January 7th, 2025 | |||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |||||||||
| 3:33 pm | PhD Position in Cryptography We are inviting applications for a PhD studentship in the cryptography lab at King’s College London. Specifically, we are looking for an applicant to work with me and Benjamin Dowling. The PhD could, for example, cover cryptanalysing existing cryptographic technologies/protocols, such as Telegram or WhatsApp, or modelling and designing new cryptographic protocols or primitives. This PhD will work in a team consisting of social scientists, specifically ethnographers, and us cryptographers. Together, we study what the security needs and wants of participants in large-scale protests are and how these relate to the security guarantees provided by cryptographic solutions. See, for example, the lecture “Limits of Proofs (Social Foundations)” or this blog post (for another position on this project) for more details of what we’re trying to do here. We encourage applicants to reach out to us to discuss the position informally before applying, by e-mailing Ben and me: martin.albrecht_AT_kcl.ac.uk and benjamin.dowling_AT_kcl.ac.uk. Fine print. This is a fully-funded positions covering both fees and maintenance. The latter is at the UKRI rate. We seek applicants with a strong background in mathematics and/or computer science, preferably with some background in cryptography. We will consider applications on a rolling basis. | ||||||||
| Friday, November 29th, 2024 | |||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |||||||||
| 8:29 pm | PhD Position in Lattice-Based Cryptography We are inviting applications for a PhD studentship in the cryptography lab at King’s College London. Specifically, we are looking for an applicant to work with us in the area of lattice-based cryptography. We are particularly interested in the study of and constructions from new lattice-based assumptions and privacy-preserving technologies based on lattices. The PhD could cover studying the underlying hard mathematical problems, cryptanalysis, constructions or applications of lattice-techniques. This can cover post-quantum aspects of lattice-based cryptography and/or advanced functionalities. The applicant would work with me, Ngoc Khanh Nguyen and/or Eamonn Postlethwaite. We encourage applicants to reach out to me to discuss the position informally before applying. Fine print. This is a fully-funded positions covering both fees and maintenance. The latter is at the UKRI rate. Funded by UKRI Frontier Research. We seek applicants with a strong background in mathematics and/or computer science. We will consider applications on a rolling basis. | ||||||||
| Saturday, September 21st, 2024 | |||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |||||||||
| 4:21 pm | Verifiable Oblivious Pseudorandom Functions from Lattices: Practical-ish and Thresholdisable Our paper (with Kamil Doruk Gur) “Verifiable Oblivious Pseudorandom Functions from Lattices: Practical-ish and Thresholdisable” is now available on ePrint and will appear at Asiacrypt 2024. Doruk and I started working on this together when he did his residency at SandboxAQ. Here’s the abstract:
The TL;DR is that we get a (plausibly) post-quantum (V)OPRF following the blueprint of [PKC:ADDS21] with about 100KB bandwidth cost for offline communication (once) and 200KB bandwidth cost for online communication (per query), if you’re happy with
To explain what we did, let us begin with a high-level overview of the construction from [PKC:ADDS21] and highlight its main bottlenecks. The VOPRF construction is based on the ring instantiation of the PRF by Banerjee and Peikert [C:BanPei14] where
Since Correctness is satisfied with high probability regardless of the choice of The above construction is intuitive in following well-established pre-quantum Diffie-Hellmann blueprints. Moreover, its simple algebraic nature (and instantiation in the standard model, except potentially for zero-knowledge proofs) allows for extensions such as threshold variants. However, the concrete instantiation is highly inefficient due to three reasons. First, the correctness of the PRF adds a superpolynomial factor to the modulus Second, to hide the additive terms Third, the NIZKAoKs required for verifiability and to protect against malicious clients add further overheads as these relations require non-trivial statements. In particular, the proof that So, on to what we actually did. First, we avoid relying on the 1D-SIS assumption, by borrowing a trick from the non-interactive key exchange in [USENIX:GKQMS24]. Instead of defining the PRF output as Second, we change the way how we analyse Third, we replace the NIZKAoK [C:YAZXYW19] with that from [C:LyuNguPla22] compressed with LaBRADOR [C:BeuSei23] and also work in larger rings Compared with [PKC:ADDS21], our work allows for practical-ish parameters. Compared with [EC:ADDG24], our bandwidth requirements are smaller if few evaluations are required. In terms of computational burden, note that [EC:ADDG24] has an expensive computation on the server side (TFHE bootstrapping) whereas we have an expensive computation on the client side (proving well-formedness with a complex statement). I’d say neither of these two constructions deserves to be called practical, for their computational burden alone. Finally, we extend the functionality of the VOPRF and build multiparty protocols. We use | ||||||||
| Tuesday, June 11th, 2024 | |||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |||||||||
| 12:37 pm | Cryptography Postdoc Position in Social Foundations of Cryptography We are looking for a postdoc to work with us on the social foundations of cryptography. This is a two-year full-time position based in London at a salary of £47,978 per annum. We. This postdoc position is part of the EPSRC-funded project “Social Foundations of Cryptography”. The project team consists of:
The postdoc would work with all of us, but would be formally supervised by me at King’s College London.
Social Foundations of Cryptography. To motivate what we are trying to do here, consider the following excerpt from How to Leak a Secret, the seminal paper by Rivest, Shamir and Tauman introducing ring signatures.
Here, the authors consider a whistleblower setting which then motivates the definition of ring signatures. Thus, a ring signature claims to be at least also a formalisation of the social setting in which a member of a group wishes to alert outsides to something without revealing themselves while still convincing the outsider that they have access to the information being leaked. Put differently, cryptography presumes and models social relations. As such, cryptography is also a social science. However, cryptography is unaware of itself as a social science and we cryptographers more or less speculatively make up the social settings we model in our paper’s introductions. I highly recommend Jean-François Blanchette’s “Burdens of Proof: Cryptographic Culture and Evidence Law in the Age of Electronic Documents” for a deeper dive into this observation. This begs the question if cryptography gets that part of its models right? In general, we work hard to have precise definitions and definitional work is a central activity of cryptography. Yet, the correctness of this part of the definitional work is usually simply presumed: “On these questions, the literature remains silent” as Blanchette put it. Ethnography. There is an established and growing body of work on the security concerns of various groups in various contexts that we could try to rely on. However, this body of work does not provide the level of detail and gradation required for establishing, questioning, critiquing or validating cryptographic security notions. Typically, information security scholarship, concerned with establishing what security notions are in some setting, conducts interview-based studies with members of a group under study to establish their security needs. This, however, is fraught with limitations and caveats (as readily acknowledged in these works) as these interview engagements are time-limited (interviews last, say, an hour) and participants self-select to take part. In a nutshell, this means we’re often talking to people who “look like us”: security trainers or technology-savvy people. Finally, as people working on social aspects of information security will not tire of telling you, in information security there is often a gulf between what people say and what people do. To get around these limitations, our project relies on ethnography, an approach that relies heavily on extended fieldwork in the setting(s) under study. Here “extended” typically means several months. This allows the researchers to observe how security is practiced and reasoned about and what the group (under study) takes for granted and thus what would not necessarily be verbalised in an interview. In the context of our project this means that we will put what we cryptographers do “at the mercy” of the data gathered by the ethnographers in the team. The setting. Just like cryptography aims to be precise about the boundaries and conditions of its definitions and theorems, ethnography avoids (over)generalising and insists on giving answers for specific settings and contexts rather than abstract notions like “security”. It deals in “The participants in a front-line confrontation of protest X in country Y at time Z were chiefly concerned with forward-secrecy in case of an arrest” rather than “forward-secrecy is important to activists”. Thus, selecting relevant settings is paramount. When it comes to studying cryptographic security notions, we need to select a setting where such notions make sense. This means, (a) there is conflict and thus “adversaries” and (b) these adversaries are somewhat restricted to computational attacks, i.e. they do not simply beat passwords out of people. The settings we settled on for this project are large-scale protests in various regions of the world as these tick those two boxes. The project. Roughly, the research design of our project is:
Thus, the cryptographic work in this project can range from definitional work to constructive work and to cryptanalytic work. A (rather limited) example of this approach is our work on protests in Hong Kong which motivated us to look at Telegram. Feel free to reach out if you’d like to discuss if this position could be for you. For more details on the formalities and to apply, go here. | ||||||||
| Thursday, May 30th, 2024 | |||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |||||||||
| 8:22 am | Postdoc Position in Lattice-Based Cryptography We are recruiting a postdoc to work with us on “practical advanced post-quantum cryptography from lattices”, the title of my ERC selected, UKRI Frontier Research funded project:
So when I say “advanced”, I don’t mean Functional Encryption or Indistinguishability Obfuscation, but OPRFs, Blind Signatures, Updatable Public-Key Encryption, even NIKE (sadly!). I’m quite flexible on what background applicants bring to the table?
All of that is in scope. If in doubt, drop me an e-mail and we can discuss.
Here is some key data of the position:
I want to draw out the “salary” point above. The position is either for a Research Associate (Grade 6) or a Research Fellow (Grade 7). The distinction between those two grades is not “years since PhD” but being able satisfy the essential criteria for a Research Fellow. I appreciate this can be confusing, especially for people not familiar with UK Higher Education (this is what we call universities here), so I’d encourage candidates to get in touch to discuss what grade would be appropriate. As mentioned in the job ad, the postdoc will sit in the newly established Cryptography Lab at King’s (which itself is part of the Cybersecurity Group). Currently, the Cryptography Lab are: Moreover, the PhD students I work with (who are enrolled at Royal Holloway, University of London, where I was until last year) are what you might call associated members: Benjamin Benčina, Dan Jones, Sasha Lapiha and Shubham Pawar. We’ll recruit more PhD students, postdocs and permanent staff in the next few years. I’d appreciate if you could help me to spread the word to people who might be a good fit for this position. Any questions, drop me an e-mail. Apply here. | ||||||||
| Friday, February 2nd, 2024 | |||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |||||||||
| 11:03 am | Senior Research Scientist in Post-Quantum Cryptography at SandboxAQ The post-quantum research team at SandboxAQ, i.e. the team I’m in, is looking to hire a full-time researcher to join our team. Currently, the PQC team consists of: and you can get a sense what we’ve been up to by checking out our respective DBLP pages linked above and the SandboxAQ publications page. Here are some details about the role:
| ||||||||
| Thursday, December 14th, 2023 | |||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |||||||||
| 1:37 pm | Social Foundations of Cryptography I’m rather excited to report that EPSRC decided to fund our grant titled “Social Foundations of Cryptography”. Our project tries to do two things. First, we want to ground cryptographic security notions in rigorous social science findings rather than “simply” our intuitions that we write down in the introductions of our papers. In Burdens of Proof, Jean-François Blanchette characterises what we – as cryptographers – do as follows:
Our approach is to flip this approach around: make cryptographic security notions contingent on ethnographic findings. This is, of course, a tall order when it comes to, say, PRP security of a block cipher (I enjoy Phil Rogaway’s discussion of cryptographic definitions, Phil is also on our advisory board), but it is perhaps a bit more obvious when we talk about ideal functionalities in simulation-based proofs of complex cryptographic protocols. For these ideal functionalities it is not at all immediately clear they are indeed “ideal”. Still, this remains quite a daunting project and I’m rather nervous about it. Second, we picked the settings of large-scale urban protests, i.e. ask about security notions and needs of protesters confronting agents of the state. We think these settings (we plan on doing field work in different sites internationally) are rich yet specific. That is, notions of security depend on context and grounding cryptographic notions in such contexts can unlock insights. Post-compromise security needs for a business traveller (having their phone confiscated at an airport) and for protesters (who face arrest) may be quite different. Another key, distinguishing, feature of these settings is that security notions are quite collective rather than individual, according to our pilot study. In this study we interviewed protesters involved in the Anti Extradition Bill protests in Hong Kong (2019/2020). This work then motivated us to then take a deeper look at Telegram. However, this pilot study has the big caveat that its inquiry was somewhat limited, by necessity. Our study was an interview study, meaning participants self-selected to discuss their security needs with us. Yet, a key challenge in engaging those who depend on security technology is that they are not trained information security professionals. They do not know and, indeed, should not need to know, for example, that confidentiality requires integrity, that existing onboarding practices can be phrased in the language of information security, which different security notions cannot be achieved simultaneously and what guarantees, say, cryptography, can give if asked. Therefore, to know exactly what is taken for granted, or put otherwise, expected or desired, in social interactions, social and technical protocols and, indeed, cryptography is of critical import. This is where ethnography comes in, as it is uniquely placed to “unearth what the group (under study) takes for granted”. In a nutshell, it’s a social science method involving prolonged field work, i.e. staying with the group under study, to observe not only what they say but also what their social reality and practice is. On the cryptographic side, our project consists of Ben Dowling (Sheffield) and me. On the ethnography side, it’s Andrea Medrado (Westminster) and Rikke Jensen (RHUL). But we’re hiring! We will have one postdoc position in ethnography at RHUL (perhaps not so relevant to the audience of this blog, see Rikke’s blog post) and one postdoc position in cryptography. This position is only scheduled to start in a year, but if you’re interested please let us know, we have some flexibility about when to put it on the market. I’ve hired for postdoc positions before, but I think I’ve never been this nervous about that process as here. If working on the protest setting and putting what you’ll do at the mercy of ethnographic findings is for you, please reach out! Our project website is here: https://social-foundations-of-cryptograp | ||||||||
| Thursday, October 12th, 2023 | |||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |||||||||
| 12:12 pm | Postdoc Position(s) I am recruiting a postdoc1 to work with me on “practical advanced post-quantum cryptography from lattices”, the title of my ERC selected, UKRI Frontier Research funded project:
So when I say “advanced”, I don’t mean Functional Encryption or Indistinguishability Obfuscation, but OPRFs, Blind Signatures, Updatable Public-Key Encryption, even NIKE (sadly!). I’m quite flexible on what background applicants bring to the table?
All of that is in scope. If in doubt, drop me an e-mail and we can discuss.
Here is some key data of the position:
I want to draw out the “salary” point above. The position is either for a Research Associate (Grade 6) or a Research Fellow (Grade 7). The distinction between those two grades is not “years since PhD” but being able satisfy the essential criteria for a Research Fellow. I appreciate this can be confusing, especially for people not familiar with UK Higher Education (this is what we call universities here), so I’d encourage candidates to get in touch to discuss what grade would be appropriate. As mentioned in the job ad, the postdoc will sit in the newly established Cryptography Lab at King’s (which itself is part of the Cybersecurity Group). Currently, the Cryptography Lab are: Moreover, the PhD students I work with (who are enrolled at Royal Holloway, University of London, where I was until last year) are what you might call associated members: Benjamin Benčina, Dan Jones, Sasha Lapiha and Shubham Pawar. We’ll recruit more PhD students, postdocs and permanent staff in the next few years. I’d appreciate if you could help me to spread the word to people who might be a good fit for this position. Any questions, drop me an e-mail. Footnotes:1 </p>
I will have more positions over the next few years, hence the plural in the title. | ||||||||
| Monday, October 9th, 2023 | |||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |||||||||
| 11:55 am | A Surfeit of SIS with Hints Assumptions After a “lattice-assumptions winter”
That is, in some shape or form, these assumptions posit that some variant of SIS or ISIS remains hard even if you hand out some short preimages of some specially selected targets. There’s quite some variety here: BASIS instead hands out a trapdoor for a bigger related matrix, one-more-ISIS allows the adversary to pick the targets but has tight norm constraints etc. I’ve started to track these new assumptions in the SIS with Hints Zoo, with the hope of encouraging cryptanalysis, reductions and/or re-use of existing assumptions. That page has been up for a little while. I’m blogging about it now, because it now has a few “non-trivial” entries, that you might have missed and that illustrate well that cryptanalysis and reductions are fruitful endeavours here:
If your (favourite) assumption is missing or is misrepresented, please get in touch: PRs welcome, too. | ||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |||||||||
| 8:01 am | Post-quantum oblivious PRFs from shallow PRFs and TFHE We – Alex Davidson, Amit Deo, Daniel Gardham and me – have updated our pre-print Crypto Dark Matter on the Torus: Oblivious PRFs from shallow PRFs and TFHE. It has been around for a while, but I am now somewhat confident that we won’t squeeze more performance out of it for the time being, so this feels like the right time to blog about. What is an OPRF and why should I care? Oblivious pseudorandom functions allow two parties to compute a pseudorandom function (PRF) Sounds good, seems solved! Despite the wide use of (V)OPRFs, most constructions are based on classical assumptions, such as Diffie-Hellman (DH), RSA or even pairing-based assumptions. Indeed, DH-based OPRFs are currently being standardised by the IETF. Their vulnerability to quantum adversaries makes it desirable to find post-quantum solutions, however, known candidates are much less efficient. Oblivious PRF and FHE, I see where this is going … Indeed, given fully homomorphic encryption (FHE), there is a natural (P)OPRF candidate. The client FHE encrypts input Yet, if we expand our circuit model to arithmetic circuits with both mod where arithmetic operations are over the integers and So what did you actually do? We construct a novel POPRF from lattice assumptions and the “Crypto Dark Matter” PRF candidate in the random oracle model. At a conceptual level, our scheme exploits the alignment of this family of PRF candidates, relying on mixed modulus computations, and programmable bootstrapping in the torus fully homomorphic encryption scheme (TFHE). This allows us to construct an OPRF candidate using only one level of bootstrapping (the most expensive operation in a FHE computation). We also explore a cut-and-choose based strategy for adding verifiability to our OPRF. Performance. For the core online OPRF functionality, we require amortised 10.0KB communication per evaluation and a one-time per-client setup communication of 2.5MB. I’d say his makes our OPRF practical size-wise. Client computation costs are also somewhat manageable but server computation costs are quite unattractive unless you’re willing to invest in some FHE co-processor. We have some early benchmarks (using tfhe-rs) running the server code in ~150ms on 64 cores. Let me stress that this does not account for “circuit privacy” which should add a factor of 5x to 10x (or the zk systems we need, but we assume those won’t add that much overhead in computation, we do include their sizes in the estimates above). Moreover, our relatively small sizes are the effect of aggressive packing, unpacked the key material should weight about ~2GB in RAM. Implementation. We do have a somewhat complete implementation of our scheme, but it is in SageMath and thus extremely slow. I should mention, though, that this implementation, too, does not cover the zero-knowledge proof systems we rely on to achieve malicious security. | ||||||||
| Saturday, September 2nd, 2023 | |||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |||||||||
| 8:30 am | A Formal Cryptographic Analysis of Matrix’ Core Our work – “Device-Oriented Group Messaging: A Formal Cryptographic Analysis of Matrix’ Core” – is now out on ePrint and will be presented at IEEE S&P’24; “us” here being Dan Jones, Benjamin Dowling and myself. Matrix is an open standard for interoperable, federated, real-time communication over the Internet. It consists of a number of specifications which, together, define a federated secure group messaging protocol enabling clients, with accounts on different Matrix servers, to exchange messages. Last year, together with Sophía Celi, we reported several severe security issues in its cryptographic core, invalidating the cryptographic security guarantees of confidentiality and authentication in the protocol and its flagship client Element. What we originally set out to do was to formally analyse Matrix, i.e. not “just” find some vulnerabilities that leave open the question whether there are lurking more, but to get some more rigorous assurances that whole classes of attacks will fail:
This paper is that analysis, some of us originally set out to do. For this, we “had to” define a new security model that matches what Matrix is trying to do: Device-Oriented Group Messaging. We then show that confidentiality and authentication are achieved by Matrix in that model under some standard assumptions, such as that AES is a good block cipher. There are some noteworthy limitations, though. Most importantly, as it stands, Matrix lacks cryptographic authentication for (recipient) group membership (something we pointed out in our previous work). Our model captures this limitation by modelling these attacks as trivial wins; for example, if an adversary manages to add a corrupted device to a session to break its confidentiality. Put differently, “trivial wins” in our and other proofs highlight potentially devastating real-world attacks that simply cannot be prevented by the protocol. For example, if you give the AES key to the adversary, of course, it can decrypt. Or in the case of Matrix, if you inject a rouge device to a group chat, of course it can decrypt. The Matrix developers are working on fixing that, but this is work in progress. This already highlights a challenge we faced in this work is to communicate what these proofs even mean.1 I assume this part is the most interesting for those who read this far. Thus, below, I reproduce an edited and shortened version of our discussion section, our best attempt at offering an interpretation. Our formal security statements should be interpreted to mean that Matrix’ core cryptographic components can achieve the stated security goals after the authentication vulnerabilities previously reported are fixed and formally analysed. In particular, we reiterate that it is currently trivial for a Matrix server to add a user as a recipient to a session or a unverified new device to a user. Both of these will be visible in the flagship Element client, but this behaviour is not prevented. Furthermore, these guarantees would also only apply when composed with a formally analysed cryptographic backup solution, which is not captured by our model. Finally, our guarantees only cover when devices only communicate with other verified devices. Confidentiality and authentication between whom? Matrix guarantees the confidentiality of a message between the sender and the users the sender intended as recipients, i.e. the list of group members displayed in the client. This includes all of their verified devices: past, present and future. However, since there is no cryptographic control of the list of group members, the sender’s list of intended recipients is controlled by the adversary. Matrix guarantees the authenticity of a message in that it ensures its integrity and correctly identifies the user, device and Megolm session it originated from. However, the Matrix protocol will decrypt any message for which it has been sent the necessary inbound Megolm session from a verified user and device (regardless of the sender’s group membership status, for example). A lack of canonical message order limits guarantees. Our predicates define a canonical ordering of messages in a Matrix conversation. Specifically, the challenger indexes Matrix stages (and messages) based on the order they are generated by the sender session in the experiment. Thus, the guarantees we prove must be interpreted with respect to this canonical ordering. However, this session ordering does not map back intuitively to the message order that users might observe in their clients. This is due to Matrix’ use of multiple Olm channels in parallel, making it impossible for receiving clients to determine a canonical ordering of Megolm sessions. For this reason, we suggest that future iterations of the protocol disallow multiple Olm channels between any single pair of devices. FS and PCS enable user management. Typically in the context of secure messaging, forward-secrecy (FS) ensures that messages sent before compromise remain secure, and post-compromise security (PCS) ensure that messages sent after compromise remain secure (assuming the adversary remains passive). Our trivial win conditions (see above) essentially establish that neither security goal, as defined in the cryptographic literature, is attained by Matrix when long-term secrets are compromised. Indeed, once an adversary corrupts one device of a user, the key sharing feature allows an attacker to escalate that compromise to all other devices (and all of their sessions). Furthermore, the Matrix specification allows sessions to maintain old key materials, invalidating FS guarantees. We found it useful to think of the combined states of all of a user’s devices as one big meta state that can be compromised in total and that offers essentially no PCS nor FS guarantees when long-term key material is compromised. Rather, the use of cryptographic techniques typically deployed to achieve FS and PCS serve the purpose of user management: when a new user joins and leaves a room, keys are updated. Conclusion. It is for these reasons that we avoid the standard terminology of “security proof” in this work, which can be misunderstood as a “seal of approval”. That is, rather than stating that Matrix is secure (or not), this work establishes what security guarantees its core components can provide. This is, of course, always what a cryptographic security proof does, but we consider it imperative to stress here. Despite this, our analysis suggests that current efforts by the Matrix developers to remedy the previously reported attacks reported, combined with our suggested improvements, may suffice to produce a secure protocol. Open problems. A central open problem is to analyse the authenticated group management currently in development for Matrix as well as both of its backup mechanisms. While Matrix falls short of what the cryptographic literature expects, this is only partially due to avoidable design flaws (such as long-term authentication keys circumventing PCS guarantees of Olm channels) but partially also due to a deliberate design trade-off. That is, some of the FS/PCS guarantees we establish here match those intended by the Matrix designers who accept this behaviour in favour of utility in a chat context: making older messages available across devices. This design choice limits the authenticity guarantees of the protocol. Whether this trade-off is correct is a question that falls outside the expertise of cryptography in a narrow sense. Indeed, recent work has established that the FS/PCS guarantees provided by cryptography do not align well with the needs of some people reliant on secure messaging in a higher-risk environment. Establishing what FS and PCS should be is an exciting area for future multidisciplinary work. The difficulty of establishing a consistent global ordering of messages within Matrix poses an interesting question about attacks that are possible due to inconsistent message ordering in protocols that allow out-of-order decryption. Some group messaging protocols such as MLS rely on the server to provide such a consistent global ordering: determining the impact of this ability from non-honest servers may be useful in formalising the security of such protocols. Footnotes:1 </p>
IEEE S&P’24 do a new thing this year where the reviewers leave a meta-review with the published version of the paper. You will see our reviewers weren’t quite happy with how accessible (that part of) our work is. They’re right, but we struggled to do better! | ||||||||
| Wednesday, May 17th, 2023 | |||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |||||||||
| 1:56 pm | UK Crypto Day (June 2023 Edition) Together with Nick Spooner and Sarah Meikeljohn, I’m co-organising the next UK Crypto Day.1
We got some nice speakers/talks lined up: Jonathan Bootle: The Sumcheck Protocol, Applications, and Formal VerificationThe sumcheck protocol plays a central role in many constructions of efficient zero-knowledge arguments. In this talk, I will describe the sumcheck protocol, explain why it is so useful, and discuss recent work on a machine-checkable security proof. Bio. Jonathan Bootle is a researcher in the Foundational Cryptography Group at IBM Research – Zurich. His research focuses on constructing efficient zero-knowledge proofs, especially those based on lattice assumptions or error-correcting codes. Bernardo Magri: YOSO – You Only Speak OnceImagine a setting where whenever a party in a protocol sends a message, its IP address becomes known, and it gets immediately killed by the adversary in a DoS attack. This implies that in any given protocol a party can only send a single message at a random point in time. Can we do secure multiparty computation in this setting? In this talk we introduce the YOSO MPC model that is based around the notion of roles, which are randomly assigned stateless parties that can send a single message for the entire duration of the protocol. We will show how one we can leverage the infrastructure of public blockchains to securely YOSO-compute any function with private inputs. Bio. Bernardo Magri is a Senior Lecturer at the CS department at University of Machester. His research interests are on the theoretical and practical aspects of cryptography and distributed ledgers. Sunoo Park: Email Attribution and Election AuditsMy talk will focus on two recent works. The first concerns preventing the exploitation of stolen email data. Email is used widely for personal, industry, and government communication; as such, it is a valuable target for attack. Such attacks are compounded by email’s strong attributability: today, any attacker who gains access to your email can easily prove to others that the stolen messages are authentic. We define and construct non-attributable email using a new cryptographic signature primitive. The second paper concerns a new model of post-election audits, loosely inspired by multi-prover interactive proofs. Post-election audits perform statistical hypothesis testing to confirm election outcomes. However, existing approaches are costly and laborious for close elections—often the most important cases to audit. We instead propose automated consistency checks, augmented by manual checks of only a small number of ballots. Our protocols scan each ballot twice, shuffling the ballots between scans: a “two-scan” approach inspired by two-prover proof systems. Bio: Sunoo Park is a Postdoctoral Fellow at Columbia University and Visiting Fellow at Columbia Law School. Her research interests range across cryptography, security, and technology law. She received her Ph.D. in computer science at MIT, her J.D. at Harvard Law School, and her B.A. in computer science at the University of Cambridge. Michele Ciampi: On the round-complexity of secure multi-party computationIn multi-party computation (MPC), multiple entities, each having some inputs want to jointly compute a function of these inputs with the guarantee that nothing aside from the output of the function will be leaked. In this talk, we are going to investigate how many messages the parties of an MPC need to exchange to securely realise any functionality with simulation-based security in the case where there is no setup and the majority of the parties can be corrupted. We will then consider a relaxation of the standard simulation-based paradigm, and discuss whether this lead to more efficient MPC protocols which still realize non-trivial functionalities which meaningful security. Bio. Michele Ciampi is a Chancellor’s Fellow at the School of Informatics at the University of Edinburgh. His work focuses on theoretical aspects of cryptography, including multi-party computation protocols, zero-knowledge proofs, and blockchain. François Dupressoir: Revisiting machine-checked AKE security — Reports from a possibly active trenchMachine-checked cryptographic proofs, as supported by tools such as EasyCrypt, CryptHOL or SSProve, aim at increasing trust in cryptographic algorithms by producing machine-checkable evidence that their security follows from relatively (sometimes) standard hardness assumptions. With only a few exceptions, their application has unfortunately been limited to small, typically non-interactive, constructions. A significant exception is a Eurocrypt 2015 paper applying EasyCrypt to a family of Authenticated Key Exchange protocols, whose massive proof has unfortunately been lost to time (and some obnoxious IT practices). This talk will report on an ongoing (or perhaps, hopefully, not) attempt at understanding better the interplay between EasyCrypt, interactive protocols, and a few competing pen-and-paper definition and proof methodologies. By doing so, I hope to provoke discussions around the goal and value of security proof and their machine-checked variants, and about what “traditional” cryptographers might expect or want from proof tools. Bio. François Dupressoir is a Senior Lecturer at the University of Bristol, where he heads the Cryptography Research Group. His research revolves around bringing formal methods and formal reasoning techniques to cryptographic security of algorithms, protocols and their implementations. Yixin Shen: Finding Many Collisions via Reusable Quantum Walks — Application to Lattice Sieving Given a random function In this paper, we improve the algorithms for this problem and, in particular, extend the range of admissible parameters where the lower bound is met. Our new method relies on a chained quantum walk algorithm, which might be of independent interest. It allows to extract multiple solutions of an MNRS-style quantum walk, without having to recompute it entirely: after finding and outputting a solution, the current state is reused as the initial state of another walk. As an application, we improve the quantum sieving algorithms for the Shortest Vector Problem (SVP), with a complexity of Bio. Yixin Shen is a research fellow at Royal Holloway, University of London. Her work focuses on quantum algorithms and their application in lattice-based cryptanalysis. She completed her PhD at Université Paris Cité in 2021. After that, she worked as a postdoctoral researcher at Royal Holloway. In 2022, she obtained a five-year EPSRC Quantum Technology Career Development Fellowship. Footnotes:1 </p>
Formerly, known as London-ish Crypto Day, but that produced a name clash with Liz’ London Crypto Day. | ||||||||

 – referred to as a nonce but also used as a key – is passed to a custom key derivation function (KDF), to a function computing a key confirmation hash h and is partially XORed with the server’s nonce to form the server’s salt. These three uses of
– referred to as a nonce but also used as a key – is passed to a custom key derivation function (KDF), to a function computing a key confirmation hash h and is partially XORed with the server’s nonce to form the server’s salt. These three uses of  on the number of sessions each responder can accept. On the other hand, the shortness of the value suggests that collisions between session state identifiers are likely, which complicates the proof. A longer value, even of 128 bits, would have allowed for a simpler proof.
on the number of sessions each responder can accept. On the other hand, the shortness of the value suggests that collisions between session state identifiers are likely, which complicates the proof. A longer value, even of 128 bits, would have allowed for a simpler proof.  , and the public key consists of a uniformly random tall matrix
, and the public key consists of a uniformly random tall matrix  (where
(where  ), and a vector
), and a vector  such that
such that  .
. 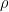 to the public key. This noise can then, for example, be encrypted as an update token, distributed and later decrypted and added to the secret key in a way that ensures the new key-pair is valid.
to the public key. This noise can then, for example, be encrypted as an update token, distributed and later decrypted and added to the secret key in a way that ensures the new key-pair is valid.  and rotate the public key into
and rotate the public key into  and
and  , where
, where  can be any random basis change.
can be any random basis change.  -ary lattices (with
-ary lattices (with  .
. 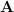 that generate a code with hull dimension
that generate a code with hull dimension  big enough so that hull attacks are not efficient.
big enough so that hull attacks are not efficient.  . In other words, it contains a vector space of dimension
. In other words, it contains a vector space of dimension  dimensions and self-orthogonal.
dimensions and self-orthogonal.  is simply a permutation. This is not much of a loss in the worst case because there the two problems are polynomial-time equivalent.
is simply a permutation. This is not much of a loss in the worst case because there the two problems are polynomial-time equivalent.  as the “secret key” which we then later rerandomise to obtain
as the “secret key” which we then later rerandomise to obtain  . The “trick” here is that
. The “trick” here is that  for any permutation matrix
for any permutation matrix  . Note that we could amortise the online cost to roughly 100KB per query if several queries are sent in parallel, but we do not cost this in our work.
. Note that we could amortise the online cost to roughly 100KB per query if several queries are sent in parallel, but we do not cost this in our work. 
 is the key with small coefficients represented in
is the key with small coefficients represented in  and
and  is essentially a hash function processing the client input
is essentially a hash function processing the client input  . Security of the construction can be reduced to the hardness of RLWE. The construction in [PKC:ADDS21] instantiates this framework with uniformly random public vectors
. Security of the construction can be reduced to the hardness of RLWE. The construction in [PKC:ADDS21] instantiates this framework with uniformly random public vectors  and a bit decomposition function
and a bit decomposition function  . Given a public
. Given a public  the high-level protocol is then:
the high-level protocol is then:  to a small key
to a small key  .
. and
and  , and computes
, and computes  .
. , the server sends
, the server sends  for small
for small  .
. .
. , if
, if  is chosen from a distribution that hides the presence of additive terms
is chosen from a distribution that hides the presence of additive terms  ,
,  and the absence of the additive term
and the absence of the additive term  (which follow some narrow distribution
(which follow some narrow distribution  ) then it is indistinguishable from
) then it is indistinguishable from  . Then if
. Then if  and consequently
and consequently  leaks nothing about
leaks nothing about  chosen from a proper RLWE secret distribution and
chosen from a proper RLWE secret distribution and  is from a discrete Gaussian, the client message
is from a discrete Gaussian, the client message  is also indistinguishable from uniform by RLWE.
is also indistinguishable from uniform by RLWE.  ,
, , and
, and  produces a rounding error for a target value
produces a rounding error for a target value  , i.e. more than what we would naively expect to have correct rounding with overwhelming probability.
, i.e. more than what we would naively expect to have correct rounding with overwhelming probability.  . Since
. Since  , we define it as
, we define it as  where
where  is the output of some Random Oracle called on
is the output of some Random Oracle called on  . In the Random Oracle model,
. In the Random Oracle model,  will round to the correct value
will round to the correct value  with a probability to
with a probability to  . This still requires a superpolynomial gap between
. This still requires a superpolynomial gap between  but this gap is comparable to that in the semi-honest setting of [PKC:ADDS21].
but this gap is comparable to that in the semi-honest setting of [PKC:ADDS21].  with lattice statements. This improves bandwidth by several orders of magnitude.
with lattice statements. This improves bandwidth by several orders of magnitude.  -out-of-
-out-of- -out-of-
-out-of- copies of the
copies of the  (there, I coined it now!) because “knapsack”, the last few years have seen the introduction of a bunch of newfangled SIS-like assumptions along the lines of:
(there, I coined it now!) because “knapsack”, the last few years have seen the introduction of a bunch of newfangled SIS-like assumptions along the lines of: 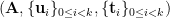 s.t.
s.t.  , with
, with  short, it is hard to find a short
short, it is hard to find a short 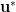 s.t.
s.t.  .
.  , as was shown in
, as was shown in  together: a server supplying a key
together: a server supplying a key  and the user does not learn
and the user does not learn  to obtain a PRF resisting attacks with complexity
to obtain a PRF resisting attacks with complexity 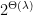 .
.  and mod
and mod  both primes, shallow proposals
both primes, shallow proposals 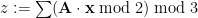
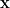 , to a full PRF, taking any
, to a full PRF, taking any 
 with domain
with domain ![[2^n]](https://s0.wp.com/latex.php?latex=%5B2%5En%5D&bg=ffffff&fg=000000&s=0&c=20201002) and codomain
and codomain ![[2^m]](https://s0.wp.com/latex.php?latex=%5B2%5Em%5D&bg=ffffff&fg=000000&s=0&c=20201002) , with
, with 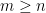 , a collision of
, a collision of  , and matching algorithms are known for any value of
, and matching algorithms are known for any value of  . The situation becomes different when one is looking for multiple collision pairs. Here, for
. The situation becomes different when one is looking for multiple collision pairs. Here, for 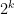 collisions, a query lower bound of
collisions, a query lower bound of  was shown by Liu and Zhandry (EUROCRYPT 2019). A matching algorithm is known, but only for relatively small values of
was shown by Liu and Zhandry (EUROCRYPT 2019). A matching algorithm is known, but only for relatively small values of  instead of the previous
instead of the previous 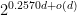 .
. LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose.