Add this feed to your friends list for news aggregation, or view this feed's syndication information.
LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose.
| Sunday, November 16th, 2014 | |
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |
| 2:45 am | Facebook’s in-memory computation engine for social analytics Facebook’s scale is out of the radar for the vast majority of cases, but yet it is very interesting to lookup new ideas there. Audience insight is a way to show us pages which were are about to like with higher probability. It is based on previously liked pages, gender, location and many other features. In particular at Facebook’s scale it is about 35 Tb of raw data and query ‘give me several pages which should be shown to user X’ must be completed within hundreds of milliseconds. That requires to process hundreds of billions of likes and billions of pages – numbers beyond reasonable – and in fraction of a second. It happens that 168 nodes can handle it with some magic like columnar storage, in-memory data, bitmap indexes, GPU and caches. Very interesting reading! |
| Friday, October 24th, 2014 | |
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |
| 8:13 pm | Facebook’s hot, warm and graph data Facebook is a maze for developing data store and access algorithms. Their scale allows and actually requires to find out new ways of storing information. For example social graph data – it is stored in MySQL and used to use aggressive memcached cache. Now Facebook uses Tao – graph-aware storage for social graph with its own graph cache. Facebook uses 3 levels of persistent storage: hot data is stored in Haystack storage – it’s lowest level is the prototype I used for Eblob. I would describe Elliptics storage with DHT, i.e. multiple servers to store one data replica, as this level of abstraction. Second comes so called WARM data – data which is accessed by 2 orders of magnitude less frequently than that at HOT level. Warm data is stored in F4 storage, Facebook describes this split and motivation in this article. And the last is a COLD storage, something weird and scientifically crazy like robotic hand with a stack of Blu-Ray disks. |
| Wednesday, October 15th, 2014 | |
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |
| 6:05 pm | Various flash caches benchmarked Guys from Swrve have benchmarked various flash caches in front of Amazon EBS volume and shared the results. Data shows that Facebook’s Flashcache performs the best. Swrve decided to replace safety with performance and started to use raid-0 stipe for EBS volumes plus SSD cache in front of them. Here is the result:
EnhanceIO is a Facebook’s Flashcache fork with nicer tools. It itself increases performance by about 25% in their workload, while splitting EBS volume into raid0 added another 25%. Above Swrve link contains more details on benchmark and other results. |
| Thursday, October 9th, 2014 | |
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |
| 4:52 pm | Document-oriented databases Amazon has announced that DynamoDB (the grandmother of all nosql databases) extended its free tier (upto 25 Gb) and added native JSON document support. Native JSON document support is basically ability to get/set not the whole document, but only its parts indexed by internal key. Nothing says about how such update will be done in distributed fashion, in particular when multiple copies are being updated in parallel, but DynamoDB doesn’t support realtime replication into multiple regions, and internally it is likely database uses master-slave replication scheme. I wrote it here to ask a question whether such document oriented databases are on demand? I know about CouchDB (and derivatives), MongoDB and others, but I’m quite interested whether and why DynamoDB wants to beat on this arena? I could add native JSON support to Elliptics but not sure it is really needed. Afterall there quite a few document-oriented databases for rather small keys, while elliptics could beat there too, but instead it better works with medium-to-large objects with streaming and distributed replication and parallel upload. |
| Monday, October 6th, 2014 | |
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |
| 3:25 pm | Facebook’s “Cold storage” or saving data on Blu-Ray disks Data has a natural live cycle – the newer the data the most actively it is accessed (read or viewed). This is exceptionally the case for digital content like pictures, movies, letters and messages. Facebook has found that the most recent 8% of the user generated content accounts for more than 80% of data access. But the old data still has to be saved for rare access. Those servers which store the old data are virtually idle and kind of useless – the only thing they do most of the time is heating the air and eating an electricity, which is quite pricey. Facebook experiments with moving this old data (actually only a backup copy of data) into special “Cold storage” which has two particular features: it can shutdown already written disks and data can be copied from those backup disks into Blu-Ray rack of disks with special robot handling blu-ray drives loading. Besides the fact that blu-ray disk is much more robust than spinning disks (it doesn’t afraid of water or dust for example, it can store data for 50 years until something new appears) the rack of disks doesn’t eat pricey electricity. http://money.cnn.com/2014/08/21/technolo |
| Wednesday, September 17th, 2014 | |
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |
| 6:14 pm | A short story on trying to use Vagrant to put elliptics node into container I want to use containers to run multiple elliptics nodes with different versions on the same server mainly to be able to quickly switch between them. I decided to run Vagrant on top of VirtualBox, since I do need for on-demand compilation of the new package versions and can not just wrap some application into container. But main goal was to be able to create ‘a box’ and put it to remote nodes to create a network of different elliptics versions, and that part is rather hard with vagrant. First, I didn’t find how to export vagrant box not to its cloud but into the local file. But I could do that with virtualbox images. But here comes the second problem, the latest vagrant and the latest virtualbox do not work on various debians. Installed the latest virtualbox on wheezy default machine ended up with timed out vagrant. Running it on top of backported 3.14 kernel doesn’t work at all. It was soo good on my development server, and miserably failed on testing machines. |
| Wednesday, September 10th, 2014 | |
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |
| 2:16 pm | Elliptics 2.26 changelog Here is a human-readable changelog of 2.26 major version of elliptics distributed storage: http://doc.reverbrain.com/elliptics:majo The main feature is multiple backends in the single server. One can turn on/off them, change state, each backend has own IO execution pool. Basically it allows to change old scheme of having many elliptics servers, one per disk/directory/mountpoint, to just one server with multiple backends. Also added new C++ structured logger Blackhole. One can send logs into ElasticSearch, syslog or use oldschool files. We also cleaned up code and client logic, introduced new kinds of errors, simplified protocol and fixed bunch of bugs. Enjoy and stay tuned! |
| Tuesday, September 9th, 2014 | |
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |
| 3:42 pm | How is Redis used in twitter Everyone knows Redis – high-performance persistent cache system. Here is an article on how Redis is being used in Twitter. It happens that Twitter not only forked and extended 1 year old Redis version, but looks like it doesn’t have plans to upgrade. Redis and its latencies are much-much-much faster than Twitter infrastructure written in Java because of GC in JVM. This allows to put a bunch of proxies on top of Redis caching cluster to do cluster management, the thing Redis misses for a while. Also Twitter uses Redis only to cache data, doesn’t care about consistency issues, doesn’t use persistent caching, at least article says data is being thrown away when server goes offline. Article desribes Twitter timeline architecture, and that’s quite weird to me: instead of having list of semifixed (or limited by size) chunks of timeline which are loaded on demand, they created a bunch of realtime updated structures in Redis, found non-trivial consistency issues and eventually ended up with the same simple approach of having ‘chunks’ of timeline stored in cache. I started to compare cache management in Twitter using Redis with what we have in Reverbrain for caching: our Elliptics SLRU cache. It uses persistent caching system (which was also described a bit in article in comparison with memcache), but also uses persistent storage to backup cache, and while cache is actually segmented LRU, its backing store can be arbitrary large at size compared to Redis. Although article is written as ‘set of facts’ somehow cut out of context (it was interview with the twitter employee), it is a good reading to think about caching, JVM, Redis and cache cluster architecture. |
| Wednesday, September 3rd, 2014 | |
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |
| 10:00 am | Elliptics, golang, GC and performance Elliptics distributed storage has native C/C++ client API as well as Python (comes with elliptics sources) and Golang bindings. There is also elliptics http proxy Rift. I like golang because of its static type system, garbage collection and built in lightweight threading model. Let’s test HTTP proxying capabilities against Elliptics node. I already tested Elliptics cache purely against native C++ client, it showed impressive 2 millions requests per second from 10 nodes, or about 200-220 krps per node using native API (very small upto 100 bytes requests), what would be HTTP proxying numbers? First, I ran single client, single Rift proxy, single elliptics node test. After some tuning I got 23 krps for random writes of 1k-5k bytes (very real load) per request. I tested 2 cases when elliptics node and rift server were on the same machine and on different physical servers. Maximum latencies with 98% percentile were about 25ms at the end of the test (about 23 krps) and 0-3 ms at 18 krps not counting rare spikes at graph below.
Second, I tested a simple golang HTTP proxy with the same setup – single elliptics node, single proxy node and Yandex Tank benchmark tool. I ran tests using the following setups: golang 1.2 with GC=100 and GC=off and golang 1.3 with the same garbage collection settings. Results are impressive: without garbage collection (GC=ff) golang 1.3 test ran with the same RPS and latencies as native C++ client. Although proxy ate 90+ Gb of RAm. Golang 1.2 showed 20% worse numbers. Turning garbage collection on with GC=100 setting lead to much worse results than native C++ client but yet it is quite impressive. I got the same RPS numbers for this test of about 23 krps, but latencies at the 20 krps were close to 80-100 msecs, and about 20-40 msecs at the middle of the test. Golang 1.2 showed 30-50% worse results here. Numbers are not that bad for single-node setup. Writing asynchronous parallel code in Golang is incredibly simpler than that in C++ with its forest of callbacks. So I will stick to Golang for the network async code for now. Will wait for Rust to stabilize though. |
| Saturday, August 23rd, 2014 | |
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |
| 4:53 pm | Crafting knowledge base the right way Google is automatically building its next generation knowledge graph named Knowledge Vault Although article is very pop-science (not science at all actually) and doesn’t contain any technical detail, it is clear on google’s idea and the way information retrieval systems head. Automatic knowledge gathering and fact extraction is also what I originally aimed at Reverbrain company, although my idea was much simpler – I wanted to automatically build a language model and fact relations between words to understand native language questions. Aug 25 there will be a presentation of Google’s Knowledge Vault, I’m too much tempting to see it and try to gather and understand bits of information on how it is implemented inside. Upfate: a paper on knowledge vault: Knowledge Vault: A Web-Scale Approach to Probabilistic Knowledge Fusion |
| Wednesday, August 13th, 2014 | |
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |
| 8:00 am | Elliptics 2.25 changelog We are proud to announce our current 2.25 production major version changelog in a human readable (not thousands of commits or several hundreds lines of packaging changelogs): http://doc.reverbrain.com/elliptics:majo Elliptics 2.25 is now in ‘support’ mode, i.e. we do not add new features which can break things, but do fix bugs and perform various cleanups. |
| Monday, August 11th, 2014 | |
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |
| 4:00 pm | Multi Data Center Replication in Cassandra A good entry-level article on how replication (including multidatacenter) is implemented in Cassandra. Basic idea is random (iirc there is weighted RR algorithm too) remote node selection which behaves like local storage (commit log + memory table) and ‘proxy’ which asynchronously sends data to remote replicas. Depending on strategies those remote replicas can be updated synchronously and can be in a different datacenter. Seems good except that rack-awareness and complexity of the setup is not covered. Also synchronous update latencies like writing data to one node and then propagate update to others as well as local queue management are not covered at all. |
| Tuesday, August 5th, 2014 | |
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |
| 10:38 pm | Machine learning, optimization and event stream management This is a bit different post – it is not about storage per se, but actually it is. Let me start a bit from the other side – I’ve read Netflix article about how they created their excellent recommendation service ( http://techblog.netflix.com/2012/06/netf Well, machine learning is not quite a learning – it is an explicitly defined mathematical problem, but I wonder whether it can be applied to optimization problem. Consider a simple scenario – robot moves over the road to its final destination point. It has a number of sensors which tell its control system about speed, edge, current coordination, wheel state and so on. And there are 2 rotated wheels. At some point robot’s right wheel moves into the hole. Robot starts turning over and in a few moments it will fall. There are numerous robot control algorithms which very roughly say ‘if sensor X says Y do Z’ and those parameters may vary and be controlled by the management optimization. Solution to this problem allows to solve a storage problem too – if storage control system can write into multiple disks, which one to select so that read and write performance would be maximized, space is efficiently used and so on. A bad solution uses heuristics – if disk A is slow at the moment, use disk B. If robot falls to the right, rotate the right wheel. And so on. It doesn’t really work in practice. Another solution – a naive one – is to ‘try every possible solution’ – rotate the right wheel, if things are worse, stop it. Rotate the left wheel – check sensors, if situation changed – react accordingly. Combine all possible controls (at random or at some order), adjust each control’s ‘weight’, hopefully this will fix the things. But when feature space is very large, i.e. we can use many controls – this solution doesn’t scale. So, what is a generic way to solve such a problem? |
| Monday, August 4th, 2014 | |
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |
| 9:58 pm | Mesa – Google’s analytic data warehousing system I will bring back various tech article analysis in this blog Let’s start with Mesa – Google’s adwords storage and query system. Albeit the article is very self-advertising and a little bit pathos, it still shows some very interesting details on how to design systems which should scale to trillions operations a day. In particular, data is versioned and never overwritten. Old versions are immutable. Queries aka transactions operate on given version, which are asynchronously propagated over the google’s world datacenters. The only sync part is versioning database – committer updates/pins new version after update transaction criteria has been met, like number of datacenters have a copy and so on. As usual – it is Paxos. Looks like everything in Google uses Paxos, not Raft. Recovery, data movement and garbage collection tasks are also performed asynchronously. Since the only sync operation is version update, committer (updating client) can write heavy data in parallel into the storage and only then ‘attach’ version to those chunks. Data is stored in (table, key, value) format, and keys are split in chunks. Data is stored in compressed columnar format within each chunk. Well, Mesa uses LevelDB, it explains and simplifies such things. Mesa uses very interesting versioning – besides so called singletons – single version update, there are also ranges like [0, v0], [v1, v5], [v6, vN] named ‘deltas’ which are basically batches of key updates with appropriate versions. There are async processes which updates version ranges: compaction [0, vX] and new batch creation processes. For example to operate a query on version 7 in example above one could ‘join’ versions [0, v0], [v1, v5] and apply singletons v6 and v7. Async processes calculate various ‘common’ ranges of versions to speed up querying. Because of versioning Mesa doesn’t need locks between query and update processing – both can be run heavily in parallel. Here is an article: https://static.googleusercontent.com/med |
| Wednesday, July 23rd, 2014 | |
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |
| 11:46 pm | RIFT documentation update We’ve updated RIFT documentation at http://doc.reverbrain.com/rift:rift It includes new Authorization header (only riftv1 method is described, S3 methods are coming), handlers ACL updates Enjoy and stay tuned! |
| Monday, June 16th, 2014 | |
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |
| 11:24 am | Data recovery in Elliptics As you know, Elliptics includes built-in utility for data synchronization both within one replica and between number of replicas. In this article I describe different modes in which synchronization could be run, how it works and give details on situations when it could be used. dnet_recovery is the main utility for data synchronization in Elliptics. It is distributed with the package elliptics-client. dnet_recovery supports 2 modes: `merge` and `dc`. `merge` is intended for data synchronization within one replica and `dc` – for data synchronization between number of replicas. Each of the modes can automatically search keys for synchronization or use keys from dump file. Most of described bellow can be found at recovery doxygen documentation. All doxygen documentation will be published on doc.reverbrain.com soon.
How does dnet_recovery work?It is better to consider different modes separately. `merge` synchronizationTo run `merge` synchronization use follow lines:
In first two cases dnet_recovery makes follow steps for each node:
In third and fourth cases dnet_recovery make follow steps for each specified group:
`dc` synchronizationTo run `dc` synchronization use follow lines:
`dc` synchronization can be customized by specifying custom recovery module by `-C`. By default `dc` uses built-in version of custom recovery module `dc_recovery.py` that could be found there and could be used as an example or adapted/rewritten for working with user data. In first two cases dnet_recovery makes follow steps:
Built-in version of custom recovery module makes follow:
In third case dnet_recovery makes follow steps:
Different situations when dnet_recovery should be usedLet our Elliptics clusters consists of 3 groups and 3 nodes in each group: For more details let:
Merge recovering after hardware failuresOnce problem with hardware was occured at one of the nodes from our cluster. Some time one group (let it be group #1) was working without one node. For this time serviceable nodes was responding for key from problematic node. When this node be restored it will have some keys outdated or missed. To deal with such situation use `merge` recovery on all serviceable nodes from problematic groups. Let host_1_2:1025:2 be the node with hardware issue. For synchronization data within group 1 after restoring node host_1_2:1025:2 dnet_recovery should be used with follow parameters:
or
Second way allows to run several dnet_recovery in parallel and run each of them directly near the node with which it will process. If hardware issues were occured at the several groups (let it be 1 and 2), use follow parameters:
Merge recovering after adding new empty nodesOnce we decided that current cluster capacity is not enough and we should add several nodes to group #3. After configurating and starting new nodes we need to move keys from old nodes to new ones. For this we should use `merge` recovery with follow parameters:
or
Second way allows to run several dnet_recovery in parallel and run each of them directly near the node with which it will process. If serveral groups (let it be 1 and 3) have to be enlarged by adding new nodes, use follow parameters:
DC recovering after network or hardware failuresLets all 3 groups of our cluster are located in different 3 DataCenters. For some time connection with one of DataCenter (elliptics group) has been lost. After restoring connection data in this replic can be outdated and/or missed. Let group 2 be problematic group. For restoring consistency between replicas use `dc` recovery with follow parameters:
If the timestamp of issue is known that dnet_recovery can check only keys changed from this timestamp by using -t dnet_recovery option. DC recovering from dump file after some failuresAs a result of scanning logs we have found that some keys are missed/outdated in some groups. Grep hex keys of all found keys and write it to dump file like follow: For synchronization only these keys from all groups (replicas) use `dc` recovery with follow parameters:
Merge recovering from dump file after some failuresAs a result of scanning logs we have found that some keys are missed/outdated in some groups. Grep hex keys of all found keys and write it to dump file like follow: 1f40fc92da241694750979ee6cf582f2d5d7d28e For synchronization only these keys within group 1 (replicas) use `merge` recovery with follow parameters:
|
| Tuesday, May 13th, 2014 | |
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |
| 2:56 pm | React monitoring tool released During last months we’ve been actively developing our monitoring tools and now we are ready to present you React! React(Real-time Call Tree) is a library for measuring time consumption of different parts of your program. You can think of it as a real-time callgrind with very small overhead and user-defined call branches. Simple and minimalistic API allows you to collect per-thread traces of your system’s workflow. Trace is represented as JSON that contains call tree description(actions) and arbitrary user annotations: This kind of trace can be very informative, on top of it you can build complex analysis tools that on the one hand can trace specific user request and on the other hand can measure performance of some specific action in overall across all requests. Also, for human readable representation of react traces we’ve build simple web-based visualization instrument. Now React is used in Elliptics and Eblob and we intent to use it in other Reverbrain products. For more details check out documentation and official repository. |
| Friday, April 11th, 2014 | |
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |
| 1:06 pm | Elliptics 2.24 reached end-of-life 2.24 was LTS release and instead of half a year we supported it more than 1 year. We will answer questions about 2.24 and help with old version for a little while, but I strongly recommend you upgrading to 2.25 |
| Thursday, April 10th, 2014 | |
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |
| 8:28 pm | RIFT is now fully API backed: buckets, acl, bucket directories, listing and so on This day has come – we made all RIFT – elliptics HTTP frontend – features (written in the title and more others) accessible via REST APIs. It required URL format changes, and now URLs are much more like S3 and REST in general: Main base stone of the RIFT – bucket – a metadata entity which shows where your data lives (group list) and how to access it (ACLs) also hosts a secondary index of the keys uploaded into that bucket (if configured to do so). Buckets, directories, files and indexes – everything can be created, processed and deleted via REST API calls. It is like having your own Amazon S3 in the pocket :) Soon we will set up a test cloud at reverbrain.com where everyone can check our technologies before digging deeper you will be able to create (limited) buckets and upload/download data, which will be stored in Germany and Russia for limited period of time. For more details about RIFT please check our documentation page: http://doc.reverbrain.com/rift:rift Stay tuned! |
| Wednesday, April 2nd, 2014 | |
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |
| 1:39 pm | Rift persistent caching Rift allows you to store popular content into separate groups for caching. This is quite different from elliptics cache where data is stored in memory in segmented LRU lists. Persistent caching allows you to temporarily put your data into additional elliptics groups, which will serve IO requests. This is usually very useful for heavy content like big images or audio/video files, which are rather expensive to put into memory cache. One can update list of objects to be cached as well as per-object list of additional groups. There is a cache.py with excessive help to work with cached keys. This tool will grab requested key from source groups and put them into caching groups as well as update special elliptics cache list object which is periodically (timeout option in cache configuration block of the Rift) checked by Rift. As soon as Rift found new keys in elliptics cache list object, it will start serving IO from those cached groups too as well as from original groups specified in the bucket. When using cache.py tool please note that its file-namespace option is actually a bucket name. To remove object from cache one should use the same cache.py tool – it will remove data from caching groups (please note that physically removing objects from disk in elliptics may require running online eblob defragmentation) and update special elliptics cache list object. This object will be reread sometime in the future, so if requested key can not be found in cache, it will be automatically served from original bucket groups. |
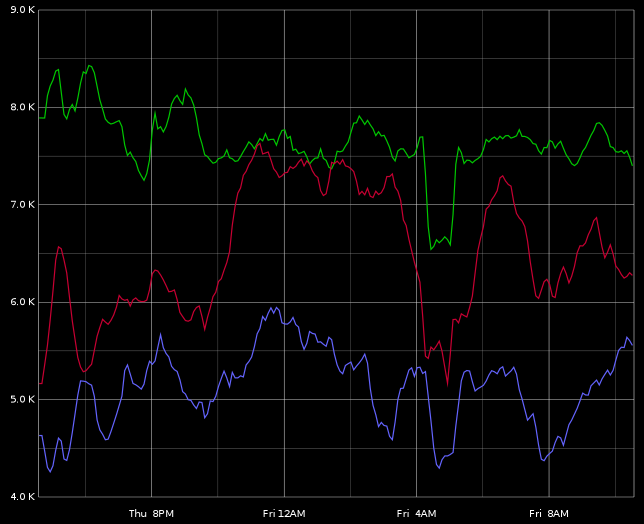
 Rift HTTP proxy writing data into elliptics cache, 1k-5k bytes per request
Rift HTTP proxy writing data into elliptics cache, 1k-5k bytes per request Golang HTTP proxy (turned off garbage collection) writing data into elliptics cache, 1k-5k bytes per request
Golang HTTP proxy (turned off garbage collection) writing data into elliptics cache, 1k-5k bytes per request Golang HTTP proxy (GC=100 garbage collection setting) writing data into elliptics cache, 1k-5k bytes per request
Golang HTTP proxy (GC=100 garbage collection setting) writing data into elliptics cache, 1k-5k bytes per request
LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose.