Add this feed to your friends list for news aggregation, or view this feed's syndication information.
LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose.
| Monday, July 28th, 2014 | ||||||||||||||||||||||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | ||||||||||||||||||||||||||||
| 5:01 am | История создания алгоритма Быстрого Преобразования Фурье Сразу после публикации статьи Кули и Тьюки [1], в которой описывался алгоритм вычисления быстрого преобразования Фурье (БПФ, FFT, Fast Fourier Transform), к авторам начали приходить письма с различными отзывами. Одни писали, что их новый революционный алгоритм распахнул невиданные горизонты для обработки сигналов и изображений, и теперь любая задача по плечу. Другие говорили [2], что алгоритм давным-давно известен и используется, так что их статья - лишь повтор того, что есть. И те, и другие были по-своему правы. Следует заметить, что время публикации статьи Кули и Тьюки [1] совпало с бурным развитием вычислительной техники, когда всё больше и больше задач решались на ЭВМ. В 1965 году, тем не менее, все высокоскоростные компьютеры были забиты заданиями под завязку. Более того, в те годы начали активно разрабатываться АЦП, которые позволяли вводить информацию в ЭВМ со скоростью нескольких тысяч отсчётов в секунду. Это означало, что теперь можно обрабатывать сигнал цифровым способом вместо использования аналоговых устройств. В свою очередь, потребовались эффективные алгоритмы обработки сигналов и изображений, многие из которых используют преобразование Фурье. Поэтому появление нового алгоритма, сулившего ускорить вычисление дискретного преобразования Фурье в $N/\log_2(N)$ , было очень кстати. Создание алгоритмаПо рассказам одного из авторов алгоритма, Джеймса Кули [3], всё началось в конце 1963 года. Джеймс Кули был нанят в IBM Thomas J. Watson Research Center в Yorktown Heights, что в Нью-Йорке. Кули работал над своим собственным проектом, когда к нему обратился Ричард Гарвин (Richard Garwin) и показал некоторые заметки Джона Тьюки (John Tukey) об алгоритме, который теоретически способен вычислять быстрое преобразование Фурье со скоростью, пропорциональной $N\log_2(N)$, а не $N^2$. Гарвин, в отличие от Кули, хорошо понимал всю важность этого алгоритма и его огромную практическую значимость, и поэтому настаивал на разработке этого алгоритма.``- Позже, - вспоминает Кули [2]. - я выяснил, что Гарвин был значительно более заинтересован в улучшении дистанционного сейсмического мониторинга ядерных взрывов; русские едва ли согласились бы на проведение инспекций на их территории. Гарвин так же видел необходимость в разработке методов раннего акустического обнаружения подводных лодок. Как и многие другие, я не считал это важным, поэтому поставил задаче разработки алгоритма БПФ приоритет ниже, чем собственным исследованиям. Тем не менее, под напором авторитета Гарвина и его постоянных телефонных звонков, я написал алгоритм для вычисления трёхмерного БПФ.'' История БПФПеред публикацией нужно было проверить, является ли идея алгоритма новой, и Кули решил посоветоваться с Джоном Тьюки. Тьюки посоветовал просмотерть несколько статей, в одной из которых [4] описывался очень похожий метод, скорость которого была несколько меньше. Было понятно, что идея их алгоритма в целом не нова, и это заставило Кули глубже изучить историю БПФ. Его непосредственный начальник, Гарвин, обратился к своему коллеге, профессору Томасу (Professor L.H. Thomas), который был в своё время научным руководителем Кули в институте. Томас дал свою опубликованную статью [5], в которой описывалось вычисление рядов Фурье, которые он проделал в 1948 году в IBM на табуляторе с перфокартами. По словам Томаса, он просто пошёл в библиотеку и взял справочник [6]. Методы, опубликованные в этом справочнике, позволяли вычислять ряды Фурье и уменьшать объёмы вычислений используя свойство симметрии тригонометрических функций.Вскоре после публикации [1] Кули получил письмо от Филипа Рудника из Института Океанографии в Санн-Диего, Калифорния. Рудник сказал, что сам реализовал подобный алгоритм, используя метод из [7]. Статья Рудника с улучшенным вариантом такого метода вышла [8] чуть позднее статьи Кули и Тьюки - он не решился публиковать её сразу. Оказалось, что приёмы, лежащие в основе БПФ, были опубликовы ещё раньше. В том же справочнике Стампффа [6] нашлась ссылка на более ранние работы Рунге и Кёнига [9]. В той работе так же использовался метод ``бабочки'' (Метод ``бабочки'', butterfly, заключается в использовании сделанных вычислений для получения соседних значений сложением или вычитанием уже полученных) для ускорения вычислений и контроля ошибок. Кули написал статью [10], в которой приводилась, как он полагал, полную историю предшествующих похожих алгоритмов вычисления БПФ вплоть до работ Рунге [9]. Однако пыль веков скрывала в себе много интересного, и вскоре Кули получил ссылку от коллеги [11] на ещё более ранюю работу по вычислению БПФ. Это была глава книги великого Карла Фридриха Гаусса [12]. В этой главе, написанной на неоклассической латыни, приводились основные соображения алгоритма БПФ. Гаусс применял разновидность интерполяции по Лагранжу, и это могло привести его к возможности сокращения количества операций при быстром преобразовании. Позже были опубликованы работы [13,11], в которых приведён краткий перевод работы Карла Гаусса, предвосхтившей БПФ, а так же упомянуты другие работы, посвящённые БПФ. ВыводыИз всей этой истории читатель может извлечь ценные выводы:1. Очевидно, что понимание важности и быстрая публикация значительных достижений очень и очень важны. 2. Аккуратное отношение к старой литературе может принести большую пользу. Награды за выдающиеся достижения должны предшествовать анализу старых публикаций и книг. 3. Общение между математиками, инженерами и специалистами прикладных областей является крайне плодотворным. 4. Не публикуйте статьи на нео-классической латыни. Литература
| |||||||||||||||||||||||||||
| Monday, June 9th, 2014 | ||||||||||||||||||||||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | ||||||||||||||||||||||||||||
| 12:45 pm | Свистульки, бубенчики и рюшечки в документах LaTeX Как все уже хорошо знают, в ЛаТеХ добиться хорошего качества документов по умолчанию очень просто: используя десяток стандартных команд, вы получите неизменно превосходный результат (ТМ) без лишних усилий. То есть документ будет хорош, но ведь иногда хочется украшательств, мигалок, свистулек и бубенчиков. На эту тему автор уже собрал небольшую коллекцию, которой и рад поделиться. Кроме того, автор открыл для себя удивительные книги Edward Tufte, который знает толк в визуальной подаче информации. Украшательства в ЛаТеХ документахКак правило, в научных документах такое не сильно поощряется, но если есть желание повыделываться, то в приличных местах этому, как правило, не противятся. Среди терпимых украшательств можно выделить буквицы (drop caps), оформление цветом всего и вся, нумерацию строк по главам.Буквица (Drop Capital) в ЛаТеХЕсли открыть старинные книги, то первая буква главы там обычно была большой и вычурной. Хотя в научных публикациях такое, в целом, встречается редко, сделать буквицу в ЛаТеХ можно запросто. Для этого подключаем пакеты:Первый пакет содержит lettrine для LaTeX, второй - вычурные шрифты. Если у вас Debian, то достаточно установить дополнительные пакеты:\usepackage[usenames,dvipsnames,svgnames,table]{xcolor}\usepackage{lettrine} %%% To make a Drop Cap \usepackage{yfonts} %% to make a fancy Gothic drop caps. texlive-fonts-extra - TeX Live: Extra fontsи теперь в документе можно использовать цветные буквицы: Вот как это выглядит в жизни:\definecolor{currentfancycolout}{RGB}{164,179,3} \lettrine[lines=3]{\color{currentfancycolout} \textbf{{\small\initfamily F}}}{ ormulation} of \lipsum[1-2]  Эпиграфы к главамПакет с простым названием epigraph делает то, что и подразумевается: вставляет эпиграфы в начале глав. Для этого подключаем пакет:и начинаем цитировать умных дядь по поводу и без:\usepackage{epigraph} %%% to make inspirational quotes. Первый параметр - цитата, второй - автор цитаты. Вот как выглядит:\epigraph{\textit{The greatest difficulties lie where we are not looking for them.}} {-- Johann Wolfgang von Goethe}  Взято из моей собственной Ph.D. Номера страниц, включающие номер главыВ больших документах, типа книг или в пространных технических отчётах, имеет смысл нумеровать страницы как НОМЕРГЛАВЫ-Страница. То есть, скажем, номер страницы 7-11 означает Глава 7, страница 11. Так как всё уже\usepackage[auto]{chappg} %%% this is to set the page numbers as Chapter-Page. который автоматически пересчитает все страницы в формат Глава-Страница вот так:  Работа с колонтитулами в LaTeXКолонтитулы это, говоря простым языком, тот текст, который появляется вверху и внизу страницы - например, вверху обычно пишут название книги или имя главы отчёта, а внизу - номер страницы.Для переопределения содержимого колонтитулов следует подключить пакеты расширений \usepackage{fancybox,fancyhdr} %this packages provides fancy up and bottom of pageв преамбуле документа. Там же, в преамбуле, будет задаваться содержимое колонтитутов. Как и прежде, чтобы лучше понять команды, откройте на другом виртуальном экране просмотрщик dvi-файлов. После всех этих приготовлений вставляем в преамбуле следующий код: \fancyhead[R]{Это простой пример верхнего колонтитула}Как легко догадается, \fancyhead управляет верхним колонтитулом, а \fancyfoot управляет нижним. Дальше в квадратных скобках следует уточнение, какая часть колонтитула имеется в виду - правая, левая или центральная. Если не указать часть колонтитула, \fancyhead{текст} будет одинаковым в левом, правом и центральном колонитуле. Этот пример интересен ещё и тем, что здесь показан один полезный трюк: левый нижний колонтитул будет выглядеть как "Страница N из M". Для этого следует подключить расширение \usepackage{lastpage}Текст колонтитулов можно задать и более хитро, например менять их в зависимости чётности страницы. Это потребует применения пакета ifthen. Дальше, что называется, для продвинутых. Например, надо на каждой чётной странице писать "чётная", а на нечётной, соответственно, "нечётная". Для этого в преамбуле подключаем Колонтитулы в работеТеперь нужно включить использование "кучерявых и причудливых" колонтитулов:\begin{document}После этого скомпилируйте документ и посмотрите как он выглядит. Если нужно на время отключить вообще все "навороты" на странице, это делается командой \pagestyle{empty} Чтобы убрать полосу вверху страницы, отчёркивающую колонтитул от содержания страницы, можно использовать в преамбуле такое переопределение: \renewcommand{\headrulewidth}{0pt}Эти трюки часто требуются для отображения в документе дополнительной информации, например, номера ревизии в Subversion репозитории, как уже говорилось здесь. Верхний и нижний колонтитул (Header and Footer) для чётных и нечётных страницВариантов проделывания такого трюка по крайней мере два: используя пакет hancyhdr или пакет titlesec.Вариант с пакетом titlesecВ преамбуле документа пишем:\usepackage{titlesec} \newpagestyle{kmvmain}[\small]{ \setheadrule{.2pt}% \sethead[\colorbox{currentfancycolout}{\color{white}{\textbf{\large \thepage}}}]% even-left [\textsc{Chapter~\thechapter: \chaptertitle}]% even-center [\colorbox{lightgrey}{\textbf{\thesection}}]% even-right {\colorbox{lightgrey}{\textbf{\thesection}}}% odd-left {\sectiontitle}% odd-center {\colorbox{currentfancycolout}{\color{white}{\textbf{\large \thepage}}}}% odd-right } тем самым создав стиль kmvmain, который и будем потом использовать. Далее в тексте используем: и после этого стиль колонтитулов изменится на вычурный.\pagestyle{kmvmain} Вариант с пакетом hancyhdrВ преамбуле документа пишем:\usepackage{fancyhdr} \fancyhead[RO]{\colorbox{currentfancycolout}{\color{white}{\textbf{\large \thepage}}}} %% odd-right \fancyhead[LE]{\colorbox{currentfancycolout}{\color{white}{\textbf{\large \thepage}}}} %%% even-left \fancyhead[LO]{\colorbox{lightgrey}{\textbf{\thesection}}}% odd-left \fancyhead[RE]{\colorbox{lightgrey}{\textbf{\thesection}}}% even-right \fancyhead[CE]{\rightmark}% odd-center, with the name of the Section \fancyhead[CO]{\textsc{Chapter~\thechapter: \leftmark}}% Even-center, with the name of the Chapter. \fancyfoot[L,R,C]{} Параметры у fancyhead и fancyfoot одинаковы и означают вот что: Далее вставляем в требуемое место упоминание вычурного (fancy) стиля: Автор черпал вдохновение в посте на stackexchange про fancyhdr полной ложкой.\pagestyle{fancy} Эдвард Тафтэ и искусство отображения информации Отображение данных, представление данных в виде таблиц и построение наглядных графиков - целое искусство. В этой области Edward Tufte - это Леонардо да Винчи отображения данных. Пожалуй, одна из его лучших книг - Envisioning Information, в которой он устраивает Tour De Fource информационного дизайна. Отображение данных, представление данных в виде таблиц и построение наглядных графиков - целое искусство. В этой области Edward Tufte - это Леонардо да Винчи отображения данных. Пожалуй, одна из его лучших книг - Envisioning Information, в которой он устраивает Tour De Fource информационного дизайна. Не говоря о том, что книга сама по себе безупречна с точки зрения дизайна, она содержит огромное количество советов, рецептов и примеров как хорошего, так и плохого дизайна. Большое количество иллюстраций и ссылок отлично дополняют материал, раскрывающий принципы наглядного отображения данных. Например, в главе ESCAPING FLATLAND, Тафтэ рассказывает о принципе small multitude - одна и та же структура, повторяющаяся много раз, и как это использовать в графиках. Этот прицнип позволяет сильно сэкономить место, подавая данные в более концетрированном и удобном для чтения виде. В главе MICRO/MACRO READINGS много говорится об использовании цвета, особенно для компактного отображения статистических данных на графиках. Его фраза Clutter and confusion are failures of design, not attributes of information.отлично проиллюстрирована в главе LAYERING AND SEPARATION, где показан чертёж сложного устройства, но выполненный настолько грамотно, что читается невероятно легко. Мимоходом критикует графики типа candlesticks (пример, такой, что уже обсуждалось в блоге). Вообще, о цвете Тафтэ говорит много и подробно, приводя многочисленные примеры и картографии и построения схем. Прошёлся он и по таблицам: глава NARRATIVES OF SPACEAND TIME одна из самых лучших в книге. Там он подробно разбирает абсолютно кошмарные таблицы, сделанные для расписаний поездов, и приводит примеры того, как это надо делать правильно. Желающим заценить визуальный катарсис можно посоветовать ЛаТеХ-класс tufte-book, который создан по всем канонам. Этот класс можно использовать и для ведения личного дневника. Вот как выглядит образец книги, оформленной tufte-book: ЭпилогОформление документов - дело тонкое, и то, что иногда кажется бесполезным украшательством, может сильно упростить чтение данных. Хотя цветные буквицы в документах - почти всегда выпендрёж, использование цвета и грамотный подход к построению таблиц позволят читателю быстрее вникнуть в суть. | |||||||||||||||||||||||||||
| Sunday, February 9th, 2014 | ||||||||||||||||||||||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | ||||||||||||||||||||||||||||
| 5:32 pm | Как написать статью в LaTeX Результатом любого приличного исследования являются публикации. Вы делаете что-то новое, и это по идее должно немного (или значительно) двинуть научное знание вперёд. А так как научные тексты удобнее писать в LaTeX, специально для этого созданным не абы кем, а Дональдом Кнутом, то возникает непраздный вопрос: как же написать статью в LaTeX?! Вернее, вопросов два: как написать научную статью и как это сделать в ЛаТеХе?
Как написать научную статью
В Сети есть много хороших и правильных постов о том, как следовало бы писать статьи. Там вам скажут, что сначала придумывается заглавие, потом аннотация (abstract), потом красивое введение, потом, собственно, результаты исследований и, как апофеоз экзистенциального катарсиса, заключение.В жизни всё несколько иначе. Обычно стоит большая задача, которую нужно решить. Мы сидим, чещем затылок и листаем журналы в поисках намёков на решение. Пробуем то и это, и чаще всего либо оно не работает вообще, либо работает, но не так, как надо. Потом иногда приходит какая-нибудь хорошая и свежая мысль, и внутренний голос говорит "О! Это интересно", а внешний - "Ахххаааа!". После прихода этого самого "Аха!" вместе с хорошей идеей автор начинает что-то быстро писать на бумаге, прикидывать, покрякивать и энергично потирать ручонки. Далее, в состоянии полного угара творчества что-то ваяется, вычисляется, математически выводится, разливается по колбам, экспериментируется, программируется и численно симулируется. Это самое счастливое время, когда забываешь обо всём на свете и делаешь что-то занятное - за это, собственно, научным сотрудникам и платят деньги. Через некоторое время угар творчества проходит и автор видит наброски, куски кода, булькающие колбы, вереницы данных, таблицы и графики. Работа принимает более организованный характер: нужно сравнить с имеющимися методами, провести дополнительные эксперименты или расчёты. Если это что-то, чего ещё никто не делал - самое время приступать к написанию статьи. Основная часть таким образом у автора в том или ином виде уже есть, так что статья начинается с середины, а именно - с полученных данных. Всё, что написано про оформление диплома или курсового проекта в LaTeX, полностью справедливо и здесь. В основной части считается хорошим тоном привести математическую формулировку или модель, которая соответствует процессам. Сравнение численной модели с реальным экспериментом тоже добавляет веса и доверию статье. Также стоит упомянуть, на каком компьютере проводились симуляции (особенно если вы предлагаете новый алгоритм и сравниваете с предыдущими), какое оборудование использовали и что булькало в пробирках. Заглавие обычно выбирается из пары десятков нагенерированных коллегами и автором вариантов. Как правило, заглавие статьи должно содержать некие ключевые слова, которые описывают содержимое статьи. Это важно, так как позволяет быстрее и проще вашу статью потом найти другим людям в поисковых системах. После этого пишется обычно одна из самых занудных частей статьи - Заключение. Дело это непростое и обычно приходит с опытом и набитием шишек. Так как люди обычно читают аннотацию (abstract), введение и заключение к статье, то они должны быть отполированы до зеркального блеска. Обычно заключение отвечает на три вопроса:
Введение это вторая по трудности часть после заключения. Введение обычно даёт формулировку целей исследования и достаточный обзор существующей литературы. Но это легко сказать, а что писать-то? Ну, например, автор этих строк пользуется следующей болванкой:
Аннотация (abstract) это короткое описание цели работы, результатов и что в работе сообщается. В целом, аннотация пишется обычно из надёрганных предложений из Введения и Заключения. Обычно аннотации короткие и должны быть не длиннее, скажем, 250 слов (у журналов и конференций по этому поводу свои правила).
Как написать научную статью в LaTeX
Эпиграф:
LaTeX is capable of most things
but not always in the most obvious manner.
Собственно, как уже говорилось выше, почти всё, что нужно для этого, есть в постах о написании диплома в LaTeX:
Но если вы думаете, что отправленную вами в журнал статью примут "с колёс" и без редакции, то вы либо крутой нобелевский лауреат, либо большой оптимист. И поэтому скорее всего вам предстоит общение с рецензентами и редактором журнала. Вот тут-то LaTeX нам и сослужит добрую службу.... Рецензии и правки научных статей в LaTeX Ещё до того, как вы отправите статью, лучше всего использовать одноколоночный набор и включить нумерацию строк, чтобы рецензенты ссылались не просто на страницу, а сразу на конкретную строку. Нумерация строк в LaTeX Нумерация строк включается пакетом lineno, который можно скачать здесь. В преамбуле документа добавляем \usepackage[mathlines]{lineno}% Enable numberingОтлично, теперь вставляем команду: \linenumbers\par %%% <---- turn on the numeration of linesтам, где мы хотим начать нумерацию линий. Если нужно оборвать нумерацию в конце статьи перед, скажем, списком литературы, команда выглядит так: \nolinenumbers %%% do not use line numbers any more.Важно то, что пакет lineno позволяет не только автоматически проставлять номера строк, но ещё и ссылаться на них. Автор настоятельно рекомендует использовать эту возможность, чтобы не сойти с ума самому при правках и не злить рецензентов. Для этого в том месте, которое вы обещаете рецензенту поправить (и делаете это), ставим ссылку: \linelabel{review:1R1}Как и везде в ЛаТеХе, ссылки стоит ставить разумные: например, здесь написано, что это ответ на замечание 1 от рецензента 1 (они обычно анонимные). Далее в тексте ответа на замечания рецензентов пишем что-то типа: We clarified this on page~\pageref{review:1R1} line~\ref{review:1R1}. Наступает счастье: здесь мы приводим не только ссылку на строку (\ref{review:1R1}) но и сразу на страницу (\pageref{review:1R1}). Вместо конструкции $$ ..... $$ следует использовать \[ ... \] или \begin{displaymath} ....\end{displaymath}, тогда пакет lineno правильно проставит номера строк в тексте с математическими формулами. Больше о нумерации строк вам расскажет весьма толковая документация к пакету lineno. Ссылка на сноски в LaTeX Допустим, вы сказали, что угоняете часть тектса в сноску. Об этом лучше написать рецензенту прямо, чтобы он не искал кусок пропавшего текста по всему документу. Для этого пишем в преамбуле документа: \newcommand{\footnoteremember}[2]{\footnote{#2} \newcounter{#1} \setcounter{#1}{\value{footnote}}} \newcommand{\footnoterecall}[1]{\footnotemark[\valuТеперь в тексте можно написать: The Finite Element Analysis was perfomed on a crappy computer\footnoteremember{footnotelatitude}{Simulations were run on the Dell Latitude E5400 notebook with Intel Celeron 2.2 GHz processor, 2GB DDR2 SDRAM, 120 GB SATA HDD 5400 rpm under Debian GNU/Linux v 5.0 with MATLAB v2007b for UNIX.}. Так что у нас есть ссылка footnotelatitude которая ведёт на сноску. Теперь сослаться на неё можно так: (see footnote\footnoterecall{footnotelatitude})И вы теперь сможете видеть номер сноски, на которую вы ссылаетесь. Трюк позаимствован отсюда. Перевод PDF в простой текст Сгенерированные ЛаТеХом документы часто переводятся в PDF, но иногда требуется перевести всё в простой текст. Часто это следует делать с сохранением структуры, и тут нам поможет pdftotext: pdftotext -layout -nopgbrk reviewnotes_12-0238_MS.pdfгде ключи означают: -layout : maintain original physical layoutЕсли нужно перевести в текст только со страницы 5 по страницу 10, даём команду: pdftotext -f 5 -l 10 reviewnotes_12-0238_MS.pdfПосле этого текст можно вставлять в веб-форму для ответа рецензентам. Ссылка название раздела или главы в LaTeX Тоже часто используется, особенно если вы при правках радикально меняете структуру статьи (скажем, рецензенты вам это настоятельно советуют). Делается ссылка на название раздела с помощью пакета nameref и который входит в пакет hyperref - он входит в стандартный набор TexLive и потому уже должен быть установлен. \usepackage{nameref} Ставим метку для раздела (section): \section{Introduction}\label{intro}И ссылемся в тексте: See more details in the \nameref{intro} section that has number \ref{intro}.Вместо этого мы при компиляции увидим: See more details in the Introduction section that has number 1.Этот удобный и простой трюк подсмотрен тут.
Вместо заключения
Собственно, этот пост - небольшая зарубка на память и собрание нескольких рецептов из моего уже порядком разросшегося черновика. Полностью приведённый пример можно посмотреть на моей странице в Google Code. | |||||||||||||||||||||||||||
| Sunday, January 5th, 2014 | ||||||||||||||||||||||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | ||||||||||||||||||||||||||||
| 5:32 pm | Вырываем список книг для чтения из zotero с мясом, Tcl-ем и SQlite-ом В этом посте мы продолжим беспощадную борьбу с кошмарным интерфейсом недо-системы управления библиографией под названием zotero с целью получить список книг для чтения. Даже для такой простой вещи, как получения списка книг, находящихся в базе zotero, нужно брать в руки автоген, скальпель и кувалду. Линуксоидов этим, конечно, не напугать, но маководов от экранов просьба удалиться во избежание. В этом посте мы безтрепетной рукой вырвем с мясом из зотеры список книг, засунутых туда через графический, скажем так, интерфейс. В этом нам поможет язык Tcl (Тикль), Debian и SQLite3. Нам, тем не менее, НЕ ПОМОЖЕТ на редкость убогая документация (пародия на неё), которая в целом рекомендует нам читать исходники и проваливать к такой-то матери. Поэтому мы решим проблему с помощью Tcl и Sqlite3. Установка SQLiteВ нашем Debian Linux все очень просто:# apt-get install sqlite3 libsqlite3-dev libsqlite3-tclименно так, поскольку установка только sqlite3 недостаточна. Теперь у нас есть все средства для работы с SQLite, на котором построена зотера. Вкушая SQlite...SQLite есть движок для баз данных - простой, не требующий перечитывания томика квантовой механики и использования синхрофазотрон-конструкций. Десять минут листания отличных туториалов по SQLite дадут нам всё, чтобы взять
Подключение к базе данных zotero.sqlite делается командой в консоли Linux:По умолчанию, вывод будет сжатым и не слишком дружественным к гуманоидам: sqlite> .mode columnи sqlite> .headers onчто повернёт SQLite к нам лицом, а к лесу - задом, и заставит печатать заголовки таблиц: и это намного понятнее. Ковыряемся в реляционно-базоданных кишках zoteroНаша цель - выдрать из базы данных зотеры список всех книг, которые нам бы хотелось прочитать, в виде простого текстового списка (точнее, в виде списка Markdown, который мы потом конвертируем в латех). Можно, конечно, экспортировать всё это в BiBTeX и потом вручную выковыривать оттуда книги с помощью JabRef, но мы выбираем Путь Самурая и делаем всё скриптами. Да, это ёпенсорс, детка...Структура SQLite базы данных zoteroСначала мы пробуем выяснить, что содержится в базе данных и в каком порядке. Для этого мы посмотрим на таблицы, которые есть в базе с помощью команды.tables которая выдаст нам всю правду:Так, мы ищем все элементы с itemTypeID=2. Посмотрим, есть ли в нашей базе книги - они должны быть: Дизайн базы данных, конечно, феерический, но кое-что удалось выдрать: теперь у нас в руках itemID каждой книги. Неплохой старт, но нам хотелось бы заголовки книг (Titles), которые очевидно хранятся где-то ещё. Немного поматюгавшись и перебрав ещё таблиц, мы натыкаемся на: Ага, теперь мы ищем fieldID=110 в которых зарыты все названия (Title) книжек и статей. Чуть раньше мы нашли книжку itemID=48 и теперь для примера мы хотим выудить её название (Title) зарытое в fieldID=110. Это можно сделать вот так: Это подводит нас совсем близко к нашей цели - ещё один окоп, ещё рывок и победа так близка! Заглавия элементов (в том числе книг) хранятся в valueID, так что нам нужно смотреть в поле itemDataValues в котором всё свалено в одну большую кучу: Ещё немного терпения, ещё один запрос к базе данных: Ага! Вот оно! Мы у цели! Можно ещё посмотреть, есть ли у книги прикреплённый нами честно купленный PDF файл: Есть, и это именно та книжка, которую мы собираемся читать. Отлично, закрываем базу данных: sqlite> .quitи идём писать на коленке скрипт на Tcl для генерации списка книг. Подключаем TCL к базе данных SQLiteЗа что мы любим Tcl, так это за философию batteries included - все батарейки уже в комплекте, и ещё немного туториалов:дают нам всё необходимое для общения с зотеровской базой данных, от которой мы теперь уж точно возьмём всё. Команды очень просты, и к примеру вот этот код на Tcl: Tcl спешит на помощь!Немного усилий, и мы имеет следующий скрипт:#!/usr/bin/tclsh ### This script connects to the SQLite database and extracts all the necessary data from it. package require sqlite3 ### First, select the type of the document to output ### sqlite> select * from itemTypes; # itemTypeID typeName templateItemTypeID display #---------- ---------- ------------------ ---------- #2 book 2 #15 report 1 set doc_type_select 2 ;#this is code for the zotero SQLite base set field_of_interest 110 ;# 110 is a Title of the book ############## This is output files in LaTeX and Markdown set mdown_prefix "- " set reading_list_filename "./Projects/actionsProject-BooksToRead" set tex_reading_list_filename "" append tex_reading_list_filename $reading_list_filename ".tex" set mdown_reading_list_filename "" append mdown_reading_list_filename $reading_list_filename "_mdown.tex" set write_fp [open $mdown_reading_list_filename w ] ############## This is output files in LaTeX and Markdown set user_name [lindex [split [pwd] "/"] 2] ;# from the working directory, split the name and get only the second one. sqlite3 db "/home/$user_name/READ/ZoteroLibrary/zotero.sqlite" ;# associate the SQLite database with the object __db__ ### Now find all the items of the type selected in $doc_type_select # sqlite> select * from items where itemTypeID=15; #itemID itemTypeID dateAdded dateModified clientDateModified libraryID key #---------- ---------- ------------------- ------------------- ------------------- ---------- ---------- #46 15 2013-09-09 08:19:06 2013-09-15 07:33:26 2013-09-15 07:33:26 ZJ4SKMQP #68 15 2013-09-10 00:25:09 2013-09-10 00:26:30 2013-09-10 00:26:30 AQ2A3NWW #set get_itemIDs_for_the_doc_type [db eval {select * from items where itemTypeID=15} ] set cmd "set substituteMe_SQLiteCommand {select * from items where itemTypeID=$doc_type_select}" ;# here we glue the stings together to make a dynamically regenerable command eval $cmd ;# evaluating the string above as a command, and thus setting regexp set get_itemIDs_for_the_doc_type [db eval $substituteMe_SQLiteCommand ] set counter 1 # tmp_itemID tmp_itemTypeID tmp_dateAdded tmp_dateModified tmp_clientDateModified tmp_libraryID tmp_key foreach {tmp_itemID tmp_itemTypeID tmp_dateAdded tmp_dateModified tmp_clientDateModified tmp_libraryID tmp_key} $get_itemIDs_for_the_doc_type { # puts $tmp_itemID set booksarray($counter) $tmp_itemID incr counter } ############ The title is stored in the fieldID=110. ############ Now figure out the valueID for each of the items foreach { num itemID } [array get booksarray] { set cmd "set substituteMe_SQLiteCommand {select * from itemData where itemID=$itemID}" eval $cmd set get_valueIDs_for_the_doc_type [db eval $substituteMe_SQLiteCommand ] #itemID fieldID valueID #---------- ---------- ---------- foreach { tmp_itemID tmp_fieldID tmp_valueID } $get_valueIDs_for_the_doc_type { set is_rightField [string compare -nocase $tmp_fieldID $field_of_interest] if { $is_rightField == 0 } { set cmd "set substituteMe_SQLiteCommand {select * from itemDataValues where valueID=$tmp_valueID}" eval $cmd set get_Title [db eval $substituteMe_SQLiteCommand ] ####### Finally, we have the book titles! foreach { numm book_title } $get_Title { regsub -all "_" $book_title " " book_title regsub -all {\x5B} $book_title "" book_title ;# replacing underbrace and square brackets regsub -all {\x5D} $book_title ", " book_title ;# replacing underbrace and square brackets puts $write_fp "$mdown_prefix $book_title" } ;####### Finally, we have the book titles! } ;# if { $is_rightField == 0 } } ;# foreach { tmp_itemID tmp_fieldID tmp_valueID } $get_valueIDs_for_the_doc_type } close $write_fp db close ;# close the SQLite database exec pandoc -f markdown -t latex $mdown_reading_list_filename -o $tex_reading_list_filename Тиклеристы-пуритане, конечно, могут сказать, что код мог бы быть и поизящнее, но нам ехать, а не шашечки, тем более что это вообще-то должна быть функция зотеры. Но так как зотероиды предпочитают длинные философские дебаты о том, "как правильно", и функций в зотере нифига от этого не прибавляется, мы пойдём другим путём. Немного о трюках в коде скрипта. Самый простой - сделать скрипт независимым от машины, на которой он исполняется. То есть мы берём имя пользователя скриптом и выдираем его командой pwd :set user_name [lindex [split [pwd] "/"] 2] ;# from the working directory, split the name and get only the second one. sqlite3 db "/home/$user_name/READ/ZoteroLibrary/zotero.sqlite" ;# associate the SQLite database with the object __db__ Ещё трюк: #set get_itemIDs_for_the_doc_type [db eval {select * from items where itemTypeID=15} ] set cmd "set substituteMe_SQLiteCommand {select * from items where itemTypeID=$doc_type_select}" ;# here we glue the stings together to make a dynamically regenerable command eval $cmd ;# evaluating the string above as a command, and thus setting regexp здесь иллюстрируются могучие способности Tcl в плане обработки строк: мы формируем команду как строку, а потом исполняем её, как команду. То есть мы подставляем itemTypeID динамически, и потом выполняем с помощью eval.Немного регекспов для удаления скобок из названий книг: regsub -all {\x5B} $book_title "" book_title ; люлистрирует возможности регекспов в Tcl по замене через ASCII-коды (ибо \x5B есть символ ] ). Последний кусочек - конвертирование списка из Markdown в LaTeX: exec pandoc -f markdown -t latex $mdown_reading_list_filename -o $tex_reading_list_filename полностью автоматизирует нашу задачу Всё.Пост иллюстрирует убедительную и беспощадную победу Tcl над Zotero и показывает немного трюков по работе с простой базой данных SQLite.Код раскрашен с помощью hilite.me | |||||||||||||||||||||||||||
| Monday, December 16th, 2013 | ||||||||||||||||||||||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | ||||||||||||||||||||||||||||
| 4:40 am | Как сделать календарь в LaTeX на год и месяц автоматически? Это краткая заметка в стиле "как отстрелить себе ногу с помощью LaTeX". Автору этих строк потребовалось сделать себе календарик, в котором отображались бы оповещения о событиях, и чтобы это дело регенерировалось автоматически при смене месяца. ПредисловиеАвтор этих строк - человек очень ленивый, но любопытный и обожающий ковырять свой Дебиан на предмет того, как бы сбросить побольше рутины на компьютер. Так появилась LaTeX-реализация организационной системы Getting Things Done, которая выполнена полностью на латехе, вместе с адресной книгой и календарём.Календарь на LaTeX реализован с помощью пакета расширений calendar [скачать ZIP-файл]. Проблема в том, что месяцы в календаре нужно обновлять самому, а вот это как раз и забывается чаще всего. Поэтому хочется, чтобы дни, месяцы и годы в календарике LaTeX обновлялись автомагически латехом и без вмешательства ленивого и забывчивого автора этих строк. Нужно сказать, что LaTeX является Turing complete language, то есть на нем можно писать любые программы. Например, можно написать интерпретатор Бейсика, симулятор машины Тьюринга, Mandelbrot with LaTeX и другие программы. То есть на латехе можно писать что угодно. Не всегда это просто (особенно в случае с календарём), но можно.Пост поделён на две части: сначала немного о возможностях пакета Calendar, а потом про то, как обновление названий месяцев сделать автоматически из LaTeX. Возможности пакета Calendar в LaTeXО возможностях пакета Calendar уже говорилось, но тем не менее. Последнюю версию пакета расширений calendar, который можно загрузить отсюда. Файлы примеров этого поста доступны здесь, батарейки в комплекте (пакет calendar там уже есть).После распаковки всех файлов в преамбуле документа подключаем пакеты: %%% Turning on the Monthly calendar and Event listдля календаря на месяц и списка событий, и: %%% Turning on the Yearly calendarдля календаря на год соответсвенно. Создание событий для календаряПакет calendar не просто создаёт календарь, но и позволяет отображать в нём события. Все события хранятся в одном текстовом файле myEvents.cld из которого они дёргаются календарём. Файл событий выглядит так:%%%%%%% My Personal CalendarСначала указываем год в отдельном файле Essentials/Calenda/year2010.cld в котором пишем: %% Span the whole year hereПовторяющиеся события будут определены только в интервале из этого файла. Список событий из календаряЧасто нужно просто видеть события, приуроченные к календарным датам (особенно если их не так много). Для этого мы пользуемся окружением eventlist, которое предоставляет пакет calendar. Настройки того, как выглядит список событий, хранятся в файле evntlist.sty который можно приукрасить разными значками и иконками.Чтобы распечатать события между нужными датами, вы просто ставите две даты, между которыми хотите показывать события (хранятся в файле events.cld): \begin{eventlist} {} {Essentials/Calendar/myEvents}и собираете LaTeXом документ, получая список календарных событий на это время:  Иконки сделаны пакетами шрифтов marvosym и wasysym. Календарь на месяц с отображением событийПакет calendar может больше - можно создать календарь на месяц и показывать там события. Код такой:\begin{monthly}Все события в календаре на указанный месяц (январь 2010 в данном случае) берутся из того же файла events.cld, который мы использовали для генерации списка календарных дней на неделю. Компилируем документ и вот он, календарь на месяц, обновлённый и со вставленными событиями:  Календарь работает с кириллицей, во всяком случае кодировка KOI8-R у него возражений не вызывает. Календарь на годМеста для отображения событий в календаре на год особенно не много, но возможность сгенерировать годовой календарь, не\begin{yearly}После сборки документа годовой календарик будет выглядеть так:  Можно посылать в печать. Вызов скриптов из LaTeXС календарём всё сравнительно понятно, и теперь настало время его автоматизировать: хочется, чтобы названия месяцев и дней подставлялись автоматически. Это не такая простая задача, как может показаться. Дело в том, что стандартные команды типа \the\year с пакетом calendar работать не будут, как не получится и подставлять значения из файлов через команду \input.Поэтому мы пойдём другим путём, как завещал нам Ильич, и напишем скрипт на питоне, генерирующий полный текст латеховского файла с использованием безграничных возможностей команды date. Собственно, идея в том, чтобы написать простенький скрипт на Питоне и вызывать его каждый раз латехом для обновления файлов календаря. Скрипт на Питоне для генерации файлов календаряСкрипт просто склеивает строки для латеха, дёргая команду date и вставляя даты куда нужно. В примере ниже показана часть генерации файла календаря на месяц.Весь латеховский файл представляет собой склеенные строки в переменной out. Вставка символа r в строках out +=r'\begin{landscape}'+'\n' указывает Питону не интерпретировать \b а печатать как есть. Вызов команды date делается через os.popen(cmd), хотя теперь так уже не модно (но тем не менее работает), а модно через subprocess.check_output (но у меня так не получилось).От полученной строки из команды date отдельно откусывается символ новой строки через .rstrip('\n') и далее сшивается с другими стоками. Результат записывается в файл tmpCalendarMonth.tex, который в свою очередь вставляется в ЛаТеХ через \input{Calendar/tmpCalendarMonth} и обрабатывается при сборке. Скрипт на питоне ниже: #! /usr/bin/python import string, os import commands kmvStartDir = '.' kmvDestDir = kmvStartDir+'/Calendar/' #destination directory for graphs ###### Getting dates and months as text using DATE command in Linux #### cmd='date --date="today" +%Y' stdout_handle = os.popen(cmd) kmv_year = stdout_handle.read() kmv_year = kmv_year.rstrip('\n') stdout_handle.close() cmd='date --date="today" +%B' stdout_handle = os.popen(cmd) kmv_month = stdout_handle.read() kmv_month = kmv_month.rstrip('\n') stdout_handle.close() cmd='date --date="today" +%e' stdout_handle = os.popen(cmd) kmv_day = stdout_handle.read() kmv_day = kmv_day.rstrip('\n') stdout_handle.close() #################################### #### Month Calendar regeneration ### #################################### kmvCalName = kmvDestDir+'tmpCalendarMonth' out = '' out +=r'\begin{landscape}'+'\n' out +=r'\begin{monthly}' out +='\n {firstday=1} \n' out +='{Calendar/myEvents} \n' out +=kmv_month+' '+kmv_year+'\n' out +='\end{monthly}\n' out +='\end{landscape}\n' ### Output to the Calendar's file ###### kmvCalName+='.tex' fout=open(kmvCalName,'w') fout.write(out) fout.close() #################################### calendar_regenerate.py и все остальные файлы можно взять отсюда. Скрипт написан для того, чтобы быть максимально понятным, а не красивым или эффективным.Вызов скрипта на Питоне из LaTeXВызывать скрипты из латеха можно несколькими способами:Здесь я приведу второй вариант, как наиболее простой. Для этого мы помещаем питоний скрипт calendar_regenerate.py в тот же каталог, где лежит файл 4myGTD.tex, из которого скрипт будет вызываться. В преамбуле документа пишем:%%% Python script for calendar regeneration \immediate\write18{./calendar_regenerate.py} Чтобы всё это заработало, нужно вызывать LaTeX с параметром -shell-escape который позволяет выполнение внешних скриптов.Кто такой \write18 и почему так называется?!Команда \write это низкоуровневая инструкция TeX, которая используется для того, чтобы производить запись в файловые "потоки". ТеХ ссылается на каждый открытый файл не по имени, а по номеру. Поток 18 является особым и зарезервирован для того, чтобы попросить операционную систему что-то выполнить - например, внешний скрипт.
Внимание! Как совершенно справедливо отмечается многими, подобный трюк в сочетании с параметром
Команда \immediate приказывает ЛаТеХ выполнить скрипт немедленно,
не дожидаясь окончания генерации всего документа. В данном случае это
оправдано, так как мы хотим, чтобы в документ вставился уже обновлённый
календарь.ЗаключениеЗаметка имеет своей целью показать возможности автоматизации в латехе с использованием сторонних скриптов на примере автоматизированной генерации календарей. Пакет calendar довольно навороченный, потому его описание заняло добрую половину поста. Пример в посте доступен здесь. | |||||||||||||||||||||||||||
| Monday, November 18th, 2013 | ||||||||||||||||||||||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | ||||||||||||||||||||||||||||
| 1:06 am | Как объединить и разбить PDF в Linux подручными средствами В этой безблагодатной и беспросветной жизни, когда тебе в линукс присылают документы в DocX и формы в последнем Adobe Acrobat, приходится несладко. Часто заполненные с воем и рыданиями PDF-файлы приходится склеивать или, наоборот, разрезать на несколько. К счастью,деятели опенсорса иногда отвлекаются от Wayland, Mir и прочих systemd и делают годные костыли для простых страждущих. Объединение файлов pdf в один с помощью PDFSaMДля тех, кто не хочет перечитывать томик квантовой физики от авторов pdftk, есть вариант с рюшечками и бубенчиками под названием PDF Split and Merge (pdfsam).Как это всегда бывает, когда что-то кажется слишком прекрасным, чтобы быть правдой, обязательно найдётся заподлянка. И pdfsam не исключение - написан он на Java, а это значит кучи exceptions по поводу и без, лютые тормоза и интерфейс из фильма ужасов. Установка и использование PDFsam в LinuxСкачать самую свежую версию можно здесь. Запуск этого поделия командой$ java -jar pdfsamдаёт что-то вроде:  Собственно, дальше всё довольно просто: pdfsam умеет объединять (merge), разрезать (split), поворачивать (rotate) документы PDF. Кроме того, имеет место быть режим burst, при котором из одного PDF-файла будет сделана куча одностраничных.  Например, для объединения PDF-файлов в один, просто добавляем файлы в порядке следования, выбираем новое имя файла и жмём RUN. Из преимуществ можно отметить разве что графический, скажем так, интерфейс. Всё остальное - это типичное джава приложение: глючное, медленное и корявое (например, при split нужно указывать номер страницы, на единицу меньший той, с которой разрезание начнётся, и т.д.). Сжатие и компрессия PDF файловПобочным продуктом работы pdfsam может быть раздувание PDF-файла до непричиных размеров. Этому горю можно помочь с помощью утилиты gs вот так:gs -sDEVICE=pdfwrite -dCompatibilityLevel=1.4 -dPDFSETTINGS=/screen -dNOPAUSE -dQUIET -dBATCH -sOutputFile=output.pdf input.pdfЭто может сжать PDF, по крайней мере в большинстве случаев. Мастерам консоли: резка и склейка PDF файлов в pdftkPDFtk расшифровывается как pdf tool kit, и, как и подобает настоящему набору инструментов, требует некоторого изучения. Зато работает быстро, умеет много и клацать мышью не надо.Установка pdftk проста - он уже есть в Debian: $ sudo apt-get install pdftkСинтаксис pdftk можно описать примерно так: pdftk исходный_файл.pdf ДЕЙСТВИЕ страницы output получаемый_файл.pdfИтак, поехали.... Как разбить PDF файл на несколькоДля того, чтобы разрезать PDF-файл на несколько, нужно воспользоваться ДЕЙСТВИЕМ cat, например вот так:$ pdftk document.pdf cat 140-142 output zz1.pdfЭта команда выдаст файл zz1.pdf, в котором будут три страницы, а именно 140, 141 и 142. Если же нужно разбить файл с какой-то страницы до конца, делаем так: $ pdftk foo.pdf cat 30-end output biography.pdf Объединение нескольких файлов PDF в один с помощью PDFtkТа же самая команда cat может склеивать PDF-файлы в один:$ pdftk zz* cat output Issue26.pdfслужит для объединения всех файлов, содержащих zz в имени, в один Issue26.pdf Если файлы называются по-разному, можно использовать следующую команду для объединения файлов в один: $ pdftk 1.pdf 2.pdf ... cat output merged.pdfбудет объединён в один файл merged.pdf. Изменение полей PDF-документаРечь идёт о полях в PDF файле вроде автора, заголовка или времени создания: Не раз и не два товарищи, работающие с документами повышенной важности, оставляли в этих полях значения, подставленные услужливым MS Word - и имели на этом немало проблем. Это можно поправить с помощью pdftk сравнительно легко. Сначала достаём исходные данные (metadata): pdftk book.pdf dump_data output report.txtВ этом файле мы увидим нечто вроде: InfoKey: TitleЭти значения можно отредактировать в полученном текстовом файле (report.txt в этом примере) и загрузить обратно: pdftk book.pdf update_info report.txt output bookcopy.pdfУ pdf-документов могут быть и другие поля, которые тоже можно поправить при желании. И это ещё не всё!Возможности pdftk весьма велики, и желающие могут припасть к официальной документации.Склейка страниц PDF файла в буклет с помощью LaTeX pdfpageОтличная иллюстрация мощи пакета pdfpages была найдена на tex.stackexchange.com. Идея сводится к тому, что сначала мы создаём исходный документ, а потом ещё один, в который вставляются PDF-страницы в нужном порядке.Например, у нас есть документ под формат А6, созданный в ЛаТеХе (назовём его mya6doc.pdf: Теперь создаём ещё один документ (назовём его mya4doc): Скомпилировать его нужно с помощью pdflatex. Это позволит получить все страницы ( pages=-) в 2x2 страницы на одной (nup=2x2) с прорисованной границей вокруг каждой страницы (frame). Это означает, что pdfpages воспринимает вставляемые страницы как изображения, так что можно дополнительно задать поля для обрезки: то есть страница будет обрезана на 1, 2, 3, 4 сантиметра слева, снизу, справа и сверху. Опция clip=true обрежет страницу. Путь джедая: склеивание PDF документов с помощью gsКак многие джедаи уже в курсе, gs это GhostScript, свободный как Столлман интерпретатор postscript и, соответственно, PDF. Командой gs можно не только орехи колоть, но и соединять документы. Соединять документы с помощью Ghostscript можно вот так:$ gs -dBATCH -dNOPAUSE -q -sDEVICE=pdfwrite -sOutputFile=finished.pdf file1.pdf file2.pdfТеперь что это всё значит: Сохранение размеров EPS файлов при конвертировании в PDFНе совсем в тему, но тем не менее про PDF. Дело в том, что при конвертировании файлов EPS в PDF разными поделками вроде ps2pdf вы получаете PDF в виде пустой страницы A4 с картинкой EPS где-то в углу. То есть поделка ps2pdf просто игнорирует выставленный BoundingBox при использовании по умолчанию:Я не буду говорить о вменяемости авторов ps2pdf, но всякий разработчик с IQ выше комнатной температуры должен понимать, что подобные WTF-моменты в пользовательском опыте в конечном итоге приводят к тому, год линупсов на десктопе уезжает в голубую даль. И это происходит именно из-за таких вот казусов, коих в ёпенсорце год от года становится только больше из-за набегающих леннартов поттерингов и прочих ковбоев, склонных к тяжёлому велосипедостроению там, где этого абсолютно не требуется.Так как ps2pdf принимает те же аргументы, что и Ghostscript, имеющий 900 газиллионов опций, среди которых должна быть возможность сохранять BoundingBox. И таки да, чудо случилось: который даёт тот самый PDF, который от него, собственно, и ждёшь. ЗаключениеПеречисленные возможности - не предел мечтаний, и всегда можно найти свежесобранный опенсорцовый велосипед со спойлером, антикрыльями и колёсами в форме листа Мёбиуса. Обнаружившим нечто интересное в деле работы с PDF документами просьба не стесняться в комментариях. | |||||||||||||||||||||||||||
| Monday, October 28th, 2013 | ||||||||||||||||||||||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | ||||||||||||||||||||||||||||
| 3:33 am | Как экстрагировать подсвеченный (highlight) текст из PDF файлов в Linux: Zotero и ZotFile Когда читаешь текст статей и книг в PDF-файлах, есть желание подсветить (highlight) интересные участки и вернуться к ним ещё разок - прямо как на бумаге. Более того, хочется текст из этих самых подсвеченных участков выдрать из PDF и экспортировать куда-нибудь ещё. И желательно это сделать в Linux и без необходимости загружать виртуальную машину с десктопным софтом для Windows. Казалось бы, в опенсорце так любят изобетать велосипеды, и должен же какой-нибудь велосипедостроитель до этого дотумкать. И таки нашёлся один герой, который это сделал! Но, как и полагается в опенсорце, для этого нужно установить другую софтину, взять автоген, бензопилу и начать процедуру ректального удаления гланд. Чем автор сейчас и займётся. Леденящие душу подробности, кишки, море крови и вагон изуродованных трупов прилагаются к посту ниже. Работа с PDF-файлами в человеческом декстопеНа всякий случай для тех, кто ест суп отвёрткой: люди читают PDF-файлы в Android и Windows и делают в них пометки\аннотации. Это удобно и помогает быстро набросать выжимку из читаемого.Любителей линукса ждёт жестокое разочарование: никаких вменяемых средств для пометок в PDF и уж тем более выдирания текста оттуда в Linux нетЪ. Да, в 2013 году мы имеем только xournal, который может тупо рисовать поверх текста, и Okular, который не умеет сохранять выделения и аннотации внутри PDF-файла. Даже в Андроиде софта для работы с PDF больше: тот же ezPDF отлично справляется с аннотациями и выделениями (можно настраивать даже цвет и прозрачность). Вот так: Для Windows есть PDFXchange-viewer который отлично работает в WINE (и бесплатен для загрузки!). В работе он ещё проще ezPDF, так как имеет специальный инструмент для подсвечивания, чтобы не пришлось подтверждать каждый раз:  Как мы с неудовольствием наблюдаем, что в Windows и Android таких программ - завались, в то время как разработнички ёпенсорца заняты куда более важными вещами вроде systemd, Mir и Wayland. Но мы не об этом - обещанные кишки и море крови впереди. Zotero + ZotFile = экстрагируем выделенный текст (Highlights) из PDF в Linux без наркоза!Есть такой сорт программ, которые пытаются управлять коллекциями материалов для чтения. Одна из таких попыток называется Zotero и представляет собой урезанный Firefox (оно называется Standalone, то бишь отдельностоячая версия) или плагин к Firefox.Так вот, сам по себе интерфейс Zotero ужасен настолько, насколько может быть убог интерфейс, созданный опенсорцными деятелями. Но у зотеры есть один волшебный плагин, который называется ZotFile - и вот он-то умеет вытаскивать подсвеченные куски текста из PDF-файлов. Казалось бы, что ж автор-то злопыхает? Вот оно, решение-то. Ан нет: чтобы получить искомое, придётся взять автоген и безнозпилу. Установка сопутствующих инструментов: zoteroПо этой ссылке можно скачать либо Firefox extension либо зотеру Standalone в виде отдельного приложения. После установки zotero нам потребуется плагин ZotFile, который позволяет получить искомую возможность экспорта выделений из PDF-файлов.Установка ZotFileИдём на ZotFile official website или mozilla page и скачиваем расширение ZotFile. Далее в zotero идём в меню Tools -> Addons и устанавливаем ZotFile: Всё, теперь начинается битва с зотерой - добавление PDF-файлов и работа с ними. Да, массовый импорт PDF-файлов из меню Import невозможен и сочтён разработчиками zotero ненужной и мало полезной функцией. Если вы подумали, что импортировать файлы можно через File -> Import... то вас ждёт сюрприз: так сделать не получится.  Оказывается, что для добавления PDF-файлов пользователь должен на зелёный ПЛЮС "New Item" -> "Story copy of file" и, зажав шифт  Эти файлы будут сохранены в виде приложения (attachments) в каталогах ./Library/storage с затейливыми подкаталогами. Но так как мы не собираемся использовать эту поделку ни для чего серьёзного, это нам не важно.Я уже хочу попросить местного Санта Клауса подарить мне вертолёт с миниганом для полётов над местами скопления девелоперсов зотеры. К ним я хочу прилететь даже больше, чем к поттерингу и девелоперсам Гнома3: в отличие от зотерщиков, эти отморозки ничего толкового не делают. Зотрещики же откровенно издеваются над пользователями, городя наименее вменяемые интерфейсы для в целом годной и хорошей программы. Посылаем чтиво из ZoteroДля того, чтобы послать PDF файлы на планшет \ таблетку \ директорию для чтения (это может быть каталог Dropbox, который синхронизируется с декстопом и планештом), выбираем файлы, зажав Shift, кликаем правой кнопкой мыши по ним и выбираем "Manage Attachments"-> "Send to Subfolder on Tablet". Это функция ZotFile - зотера из коробки этого не умеет. Расположение каталога можно настроить в опциях ZotFile. Для этого идём в "Tools" -> Add-ons -> ZotFile -> "Tablet Settings" и меняем по вкусу.  Читаем и делаем пометки (highlights) в PDFТак как на линуксовом "десктопе" ничего удобоваримого нет, идём на поклон к проприетарщине:
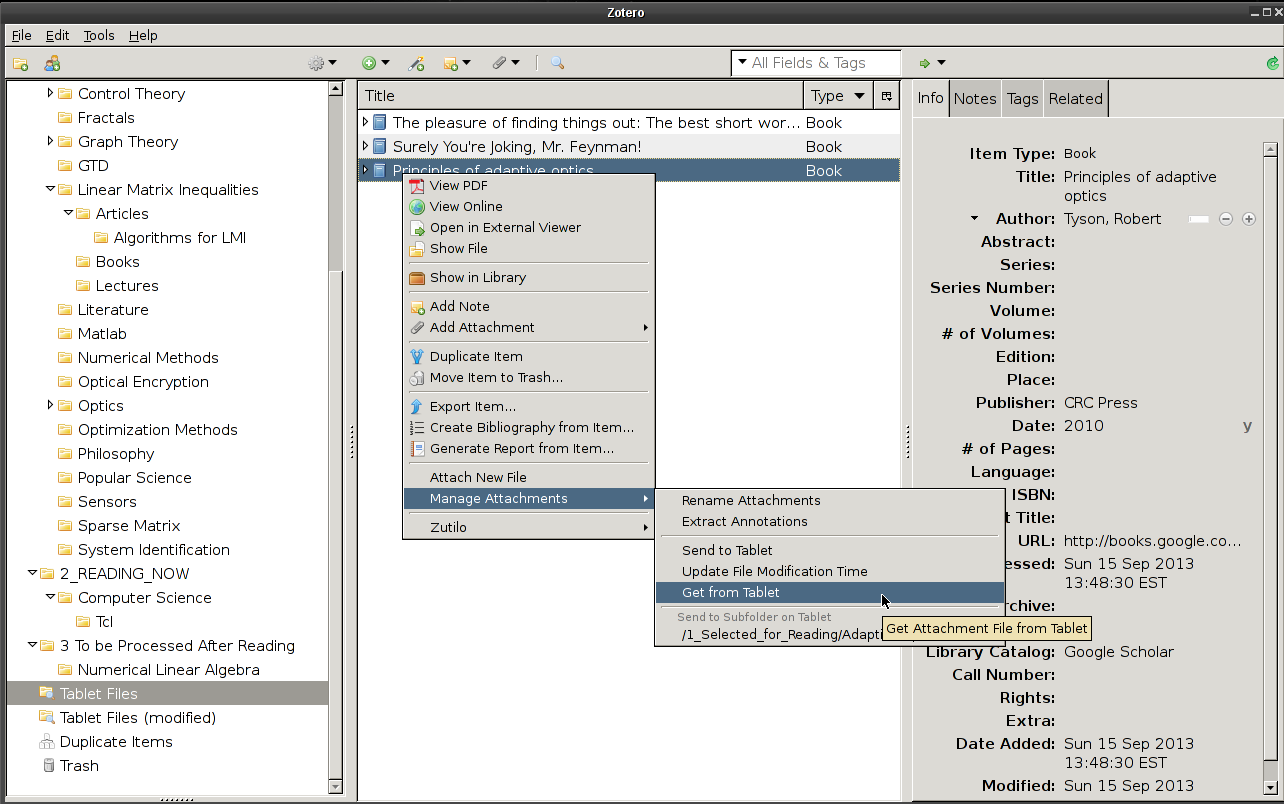 Выдираем подсвеченный текст из PDF используя ZotFileВыделяем прочитанный PDFник с подсвеченным текстом, жмём правую кнопку мыши и выбираем Manage Attachments-> Extract Highlights. И вот они, наши бесценные пометки, в красиво оформленном виде - ZotFile вставит даже номер страницы, откуда пометки взяты. Пометки выдираются без проблем как в случае использования ezPDF, так и PDFExchange. Всё, пометки можно скопировать как в виде простого текста, так и в HTML:  У ZotFile есть много скрытых параметров (hidden options) и ручек, за которые можно подёргать для более тонкой настройки. Как и в Firefox, это делается через 'about:config' или, в случае с Zotero Standalone, в меню 'Actions -> Preferences -> Advanced -> Open about:config'.  Здесь мы видим обычное конфигурационное месиво от Мозиллы. Ищем строки вида 'extensions.zotfile' для скрытых опций zotfile. На примере выше я убрал кавычки для цитат, извлечённых из highlights в PDF изменив .pdfExtraction.ClosingQuotation. Теперь текст выделений не содержит кавычек. Итоги забега: zotero - квадратно-колёсный велокактусzotero, как система управления коллекцией статей и книг в PDF, хуже, чем просто бесполезна: она отнимает больше времени на борьбу с идиотизмом разработчиков, чем экономит. Примеры шедевральных решений:
Вебдвальноль спешит на помощь: SumNotes
Замечательный, простой и работящий вебсервис http://www.sumnotes.net позволяет даром извлекать выделенные слова и аннотации из PDF-файлов. Просто загружаем наш PDF файл: | |||||||||||||||||||||||||||
| Sunday, October 13th, 2013 | ||||||||||||||||||||||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | ||||||||||||||||||||||||||||
| 5:35 pm | Репозиторий deb-пакетов своими руками: сборка пакетов в Debian из исходников и бинарников на скорую руку Часто бывает нужно по-быстрому собрать deb-пакет в Debian, особенно когда уже имеется бинарный файл. Так как мы не слакварщики и не хотим засорять систему make & make install, мы пойдём другим путём и сделаем собственный пакет. А чтобы они не валялись по всему диску, закатаем наши пакеты в собственный же репозиторий. Распаковка существующих пакетовСначала посмотрим, что внутри пакета deb или rpm.Распаковка deb-пакетаРаспаковать пакет Debian нужно в два этапа - сначала извлекаем из него файлы, а потом добираемся до собственно бинарников. Вскрываем пакетик:# ar vx mypackage.debФайл пакета mypackage.deb содержит три вложенных файла:
$ tar -xzvf data.tar.gzВ текущем каталоге появится ./usr текущего каталога. Желанный бинарник лежит в ./usr/bin подкаталоге. Если же вам нужно просто извлечь файлы из пакета, можно всё сделать одной командой $ ar p mypackage.deb data.tar.gz | tar zxэто распакует пакет deb в текущий каталог. Другой вариант - использовать dpkg-deb в виде: $ dpkg-deb -x что.deb куда/ Распаковка rpm-пакетаНа всякий случай о том, как распаковать пакеты$ rpm2cpio mypackage.rpm | cpio -vidЕсли же нужно просмотреть содержимое пакета, не распаковывая его, даём команду: $ rpm2cpio mypackage.rpm | cpio -vtДля того, чтобы (попытаться) конвертировать RPM-пакет в Debian, можно воспользоваться командой: # alien mypack.i386.rpmНадо сказать, что пакеты RPM и DEB сильно отличаются друг и друга, и такое простое конвертирование не всегда проходит. Deb-пакет из бинарного файлаТеперь, когда мы знаем, что ничего волшебного внутри deb-пакетов нет, можно попробовать сварганить свой собственный дебиановский пакетик.Часто хочется сделать побыстрее, чтоб "завелось и поехало" - и вместо пакетов пользователи устанавливают программы в виде ./configure, make & make install (вместо make install можно использовать checkinstall). Как уже говорилось не раз, не стоит поддаваться искушению и ставить программы в Linux в обход менеджера пакетов - пакетный менеджер ничего о них знать не будет, и при обновлении системы вы рискуете получить больше проблем на свою голову, чем представляете.Иногда бывает так, что исходников к пакету нет - скажем, поступила к нам проприетарщина, а упаковать её в пакет хочется. Или мы наваяли скрипт, и хочется, чтобы он был на многих машинах. Нет проблем: завернём это в deb-пакет и скормим apt-у. Для этого нам понадобится утилита # apt-get install dpkg-devПодопытным кроликом будет служить бинарный файл системы контроля версий fossil, о котором уже говорилось ранее. Идея в том, чтобы в локальном каталоге (назовём его ~./tempprog) отдублировать структуру каталогов для программы так, как она лежала бы в системе в установленном виде. Большинство бинарников находится в системном каталоге /usr/bin, поэтому создаём такую же структуру в локальном: $ mkdir -p ./tempprog/usr/bin/Так мы создадим все подкаталоги за один проход. Зайдём внутрь: $ cd tempprog/и увидим созданные подкаталоги: $ treeВот они: .
└── usr
└── bin
2 directories, 0 files
Отлично, теперь в локальном каталоге ./tempprog создаём подкаталог ./DEBIAN: $ mkdir ./DEBIAN Внутри подкаталога ./DEBIAN создаём текстовый файл control с таким содержимым: Package: имя-пакета Version: версия пакета, скажем 1.0 или 2.7.9. Architecture: архитектура(i386, amd64, all...) Maintainer: сопровождающий_пакета Installed-Size: размер программы в килобайтах Depends: зависимости (пакет (>= версия)) Recommends: рекомендации (пакет (>= версия)) Suggests: предложения (пакет) Section: секция (multimedia, games, system, или другое) Priority: приоритет (optional) Homepage: http://www.домашняя_страница Description: описание программы Таким образом, в нашем локальном каталоге ./tempprog будет лежать вот что: .
├── DEBIAN
│.. └── control
└── usr
└── bin
└── fossil
3 directories, 2 files
Теперь из каталога ./tempprog даём команду на сборку этого простенького пакета: $ dpkg-deb -b ./ ./В результате появится пакет (в нашем примере с fossil) вида: fossil_1.21_i386.debкоторый можно сразу же установить в систему: $ sudo dpkg -i fossil_1.21_i386.deb [sudo] password for starscream: Selecting previously deselected package fossil. (Reading database ... 247627 files and directories currently installed.) Unpacking fossil (from fossil_1.21_i386.deb) ... Setting up fossil (1.21) ... И всё, наступает счастье. Небольшое примечание: если кто хочет установить программу в директорию Deb-пакет из исходников на скорую рукуЗдесь приводится простой вариант упаковки исходников, если все зависимости уже на месте и нам ничего не нужно делать. В общем случае это не так, и сборка пакетов с прописыванием зависимостей представляет собой довольно нетривиальный процесс.Если нам повезло и все зависимости уже в системе, можно скомпилировать исходные тексты программы и по-быстрому завернуть всё в пакет Debian. Для этого скачанные исходные тексты программы (для примера foobar версии 1.2.3) распаковываем в каталог foobar-1.2.3, и от рута даём команду: # dh_make --createorigДалее пишем # debuildОпять, если нам повезло, всё должно собраться без вопросов. Полученный пакет устанавливаем # dpkg -i foobar_1.2.3-1_i386.debОхочим до тонкостей дебиановской кулинарии и прочим правильно писающим мальчикам просьба пройти сюда и насладиться The Debian Administrator's Handbook. Эта Создание собственного локального репозитория Debian своими рукамиКогда количество собственноручно собранных пакетов перевалит за десяток, захочется удобства и комфорта установки софта. К счастью, создание собственного локального репозитория - дело сравнительно простое.Создаём каталог, в котором будут лежать все собранные непосильным трудом пакеты - пусть это будет ~/zips/virensdebianrepositor в который копируем deb-пакеты. Для создания репозитория нам понадобится dpkg-scanpackages который является (во всяком случае на момент написания поста) частью пакета dpkg-dev, как это неожиданно выяснилось. Создаём список пакетов: $ dpkg-scanpackages . /dev/null | gzip -9c > ./Packages.gzМожет быть, нам будет выведено сообщение типа: dpkg-scanpackages: warning: Packages in archive but missing from override file: dpkg-scanpackages: warning: fossil linux-headers-3.8.0-avl9-pae linux-image-3.8.0-avl9-pae pdfsam sublimetext virtualbox-4.2 xserver-xorg-input-wacom zotero dpkg-scanpackages: info: Wrote 8 entries to output Packages file. Теперь в нашем репозитории 8 пакетов. Отлично, добавляем наш репозиторий в файл: # vim /etc/apt/sources.listстрочкой типа: deb file:///home/имя_пользователя/zips/virensdebianrepository ./ Теперь нужно обновить список пакетов, чтобы они стали доступны для установки: # apt-get updateВсё, теперь можно установить, к примеру, свежесобранный текстовый редактор Sublime Text 2 (отличная инструкция там) как всегда: Теперь, для того, чтобы установить SublimeText достаточно сделать: # apt-get install sublimetext Reading package lists... Done Building dependency tree Reading state information... Done The following NEW packages will be installed: sublimetext 0 upgraded, 1 newly installed, 0 to remove and 245 not upgraded. Need to get 0 B/11.4 MB of archives. After this operation, 17.4 MB of additional disk space will be used. WARNING: The following packages cannot be authenticated! sublimetext Install these packages without verification [y/N]? Y Selecting previously deselected package sublimetext. (Reading database ... 247813 files and directories currently installed.) Unpacking sublimetext (from ..././sublimetext_2.0.2_i386.deb) ... Setting up sublimetext (2.0.2) ...Всё, пакет будет распакован и установлен, а то, что он из местного репозитория, видно вот тут: (from ..././sublimetext_2.0.2_i386.deb) ЗаключениеОписанные в этом посте рецепты - блюда на скорую руку, а не фуагра с трюфелями. Для больших репозиториев или сложных пакетов придётся-таки ознакомиться с документацией и руководствами. Ещё можно воспользоваться программой APTonCD, которая умеет не только создавать репозитории, но и записывать их на CD/DVD диски. | |||||||||||||||||||||||||||
| Monday, September 23rd, 2013 | ||||||||||||||||||||||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | ||||||||||||||||||||||||||||
| 11:37 am | Исчезновение старых картинок в Google Blogger, или Что бывает, когда всё бездумно затаскивается в Google Plus Исчезновение старых картинок на Google BloggerЕсли кто заметил исчезновение изображений из старых постов, например в этом, не думайте, что автор решил выкосить старые посты.У многих людей (включая автора) начали пропадать изображения в блогах на Blogger. Это есть результат затаскивания гуглом всех и вся в этот проклятый Google+. Дело в том, что они начали менять права доступа изображений: хотя изображения в постах исчезли, они на самом деле никуда (скорее всего) не делись, а просто к ним нет доступа. Это особенно касается старых постов, которым более 3-4 лет. Часто картинок просто не видно - отрисовывается пустая строка. Иногда вместо изображения видно "кирпич" - это значит, что нет доступа. Эта гуглопслюсовская чума постигла кучу народа. Проблема 1: в Google Picasa картинка есть, но в Blogger её не видноЗдесь проблема в том, что Blogger не имеет доступа к картинкам в Picasa, даже если выставлены права "Limited, anyone with link". Раньше всё отлично работало, но сейчас перестало: для того, чтобы Blogger увидел изображения, нужно выставить права на альбом "Public on the web". Так удалось вернуть часть картинок в посты, где они и продолжают быть видимы.Проблема 2: старые картинки c blogspot завернули на Google+, но в Picasa их нет и Blogger их не видитЭто куда серьёзнее: нет никакой возможности с ними работать, потому как они хостятся на старых серверах вида bp2.blogspot.com - они не были загружены в Picasa.Опять, раньше всё отлично работало, но недавно кому-то Пример поста с отвалившимися изображениями. Вместо картинок видно вот что:  Изображения со старого Blogger никуда не пропали: если зайти в пост, найти ссылку на картинку и вставить её напрямую в адресную строку - она отлично видна. В адресной строке справа favicon показывает мерзкий G+. То есть оно типа перенаправлено:  Та же самая проблема в Google Blogger Editor: этих картинок не видно:  но если вставить в адресную строку - картинки есть. Это затрагивает только изображения в старых постах, 2007-2009 годов. Остальные изображения (пока) на месте. От броузера не зависит (Opera/Firefox/Chrome). Вести с полейХорошие новости: похоже, гугловцы в курсе происходящего факапа и пытаются это разрулить: некоторые посты, например этот,Небольшое расследование показало, что: It's only a small group of user experiencing this issue, and it's not country related. There are users in the Netherlands which can see the (missing) images on my weblog just fine.Выдаваемая ошибка в браузере выглядит так: This web page has a redirect loop Другая хорошая новость в том, что это скорее всего проблема прав доступа, а не физического уничтожения картинок: если ввести в адресную строку броузера адрес картинки - она будет отображена. Но ни в Blogger Editor, ни в собственно посте изображения не видно. Хотя оно физически никуда не делось. Пост на googleforums - отписываться можно и там. Участники обсуждения обещали написать в Спортлото довести это дело до инженеров Google - и видимо это сделали, потому как пока (22 Сентября) картинки к старым постам снова с нами. | |||||||||||||||||||||||||||
| Monday, September 16th, 2013 | ||||||||||||||||||||||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | ||||||||||||||||||||||||||||
| 6:30 am | Как втиснусть много данных в график gnuplot Собственно, этот пост есть коллекция трюков, которая набралась в процессе подготовки двух последних конференций. Проблема в том, что нужно вместить много данных в небольшой график, и делается это порой весьма нетривиальным образом. Как известно, с помощью gnuplot можно сделать всё, что угодно, но мало кто знает как именно. Демонстрация чёрной магии в стиле Gnuplot с полным разоблачением ниже. В инженерии мало наснимать кучу данных или наделать симуляций - важно все эти данные наглядно и красиво представить. Так и самому проще анализировать полученные результаты, и проще убеждать других в их, результатах, полезности. И потом, красиво построенный информативный график смотрится намного лучше (и куда компактнее) унылой таблицы с вереницей цифр. Следующая по сложности задача - запихнуть побольше данных в график, так как статья не резиновая и часто имеет жёсткие ограничения по объёму. Вот тут-то и начинается чёрная магия.
Использование обеих вертикальных осей, но с разными подписями
В переводе это значит, что мы будем строить два массива данных на одном графике, но подписи на оси Y с двух сторон будут разные. Вот как это выглядит: Если читатель внимательно присмотрится к вертикальным осям слева и справа, то увидит, что эти оси означают разные, хотя и взаимосвязанные, данные. Смысл в том, что два набора данных влияют друг на друга, и в тексте статьи это довольно подробно излагается со ссылками в тексте на график, подсвеченные тем же цветом, что и данные на графике. Так что автор злоупотребляет цветовой раскраской не только в блоге, но и в консервативных научных журналах - не в ущерб содержанию, по возможности. Теперь серьёзно - вот код для графика:
Ключевые для понимания строки:
и далее присваиваем оси другую (независимую) подпись set y2label Обратите внимание на параметры команды на строчках 23-24: мы строим два ряда данных и указываем, какие оси использовать. Сначала это axis x1y1 а потом axis x1y2 для того, чтобы два массива данных строились относительно двух разных осей.
Три графика один под другим
Чтобы показать один и тот же сигнал, обработанный двумя разными фильтрами, полезно разместить три графика на одном, график под графиком: В строительстве подобных графиков нам поможет инструкция set multiplot в gnuplot. Вот как выглядит код для этого графика:
До строки 17 всё в общем вполне очевидно - задаём стили для линий разных типов, диапазоны на осях и сетку. Кроме того, строка 2 явно указывает гнуплоту внедрять шрифты, о чём уже была заметка ранее. Чёрная магия начинается дальше: с помощью инструкци set multiplot на строке 17 мы просим строить gnuplot несколько графиков на одном. График начинаем строить с конца, то есть с нижнего графика. Для этого мы меняем размер и позицию графика: на строках 17-22. После этих танцев с бубном строим график:set size 1,0.35 set origin 0.0,0.0 set bmargin 3 set tmargin 0 plot "./data.data" index 23 using 3 title " " with linespoints linestyle 1 lc rgb "red" из файла данных ./data.data, используя блок с результатами номер 22 (ибо index 22 а нумерация идёт с блока 0), в котором строим 3-ю колонку (using 3) стилем линий linestyle 1 используя красный цвет линии lc rgb "red" Вообще полезно продумать структуру данных для строительства графиков заранее. Например, размещать данные для разных случаев блоками (ряды данных, отбитых двумя пустыми строками), чтобы использовать возможности gnuplot и особенно инструкции index.График, расположенный в середине (строки 32-43 ), строится точно так же, только: Ну и наконец верхний график в примере это строки 44-54, после чего выключаем multiplot и скармливаем всё gnuplot для графопостроительства. Всё легко и просто :-)set size 1,0.3 set origin 0.0,0.39
Графики с осями, имеющими разрывы
Разрывные оси (broken axis) на графиках иногда нужны, чтобы показать данные только в тех значениях, где происходит что-то интересное. При этом масштаб нужен линейный, а применение логарифмических осей нежелательно или невозможно (например, когда показывается probability density function). И если вы думали, что предыдущий пример мозговыносящий - пристегните ремни, товарищи, сейчас начнётся...Рецепт подсмотрен на блоге одной суровой японской девушки, и далее будет адаптирован для ещё более мозголомного случая. Но всё по порядку. Собственно, требуется построить простой график, но чтобы оси были разрывные. Выглядит график вот так:  Код для построения графика, взятый с сайта Gnuplot Surprising, приводится далее:
Выглядит, конечно, устрашающе. Тем не менее, это тот же самый set multiplot только сбоку. В отличие от предыдущего примера, здесь мы строим левую и правую части графиков отдельно, с разными осями и диапазонами, а потом сшиваем вместе. Новизна тут в засечках на осях, которые строятся с плачем и рыданиями - реально, это самая сложная и занудная часть графика (строки 13-17):
Далее идёт построение левой части (строки 24-29): Сложность здесь в том, чтобы угадать с полями ( set lmargin и set rmargin ). У японской девушки всё легко и просто, но если нужно построить что-то посложнее, угадывание может отнять время. После убираем засечки: и строим левую часть:#unset the labels and arrows, otherwise they will be plot #for the second time unset label 1 unset label 2 unset label 3 unset arrow 1 unset arrow 2 unset arrow 3 unset arrow 4 Всё, выключаем мультиплот unset multiplot и вставляем эффектный график в статью.#the right part set border 1+4+8 #the left border is not plotted set lmargin at screen 0.53 #the right-part's location set rmargin at screen 0.94 #ytics is not plotted, as the second plot will share it with the first one unset ytics set xtics 0.9,0.02,1.0 plot [0.9:1] f(x) w l lt 1 lw 2
А теперь всё вместе: три графика в одном с разрывными осями!
На всякий случай: это не просто дешёвый выпендрёж автора этих строк и желание эпатировать публику, а реальная нужда запрессовать данные в ограниченный объём страниц конференции. Вот как выглядит график: Здесь показано время р? | |||||||||||||||||||||||||||
| Sunday, August 25th, 2013 | ||||||||||||||||||||||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | ||||||||||||||||||||||||||||
| 9:31 pm | Getting Things Done: вся идея GTD одним рисунком Сегодня весь день у автора этих строк работа никак не клеилась, и он по этому поводу решил А что за GTD, собственно?GTD это аббревиатура от Getting Things Done - название первой книги (ныне классической) от David Allen, где он предлагает систематизированный подход по управлению своими делами. GTD это не просто "ещё один тайм-менеджмент", а именно структурированный подход к упорядочиванию своих дел. Некоторое представление о том, как работает GTD, можно получить из поста по этой ссылке. Книг на самом деле три:
Вторую книгу можно пропустить без ущерба для понимания, а вот Making It All Work как раз стоит внимательно прочитать. Здесь Дэвид Аллен как раз и раскрывает всю идею GTD в понятной схеме:  Эта схема как раз и взята из книги Making It All Work где она подробно и доступно объясняется. Она показывает, что для того, чтобы быть Капитаном и Командиром, следует иметь не только контроль над ситуацией, но и перспективу. О том, как достичь и того, и другого, GTD и рассказывает в трёх книгах - каждый раз несколько иначе, добавляя недостающих деталей и предлагая информацию к размышлению. Достигаем контроля (Control) над своими делами с помощью GTDДостижение контроля означает освоение пяти шагов:
 Идея в том, чтобы всё сложить в одну корзину "Входящие" - бумажные данные оцифровать, цифровые - переместить в один файл для обработки. Далее принимается решение о том, что представляет собой данный клочок бумаги \ данных - можно ли предпринять какие-то действия по этому поводу или нет. Actionable stuffЕсли клочок бумаги в ваших руках требует каких-то действий, то это может быть:
На самом деле, создание GTD-системы "под себя" - не такая сложная задача, как кажется. Можно использовать LaTeX, как это сделал я, или Markdown, если web-просмотр вам ближе - важно, чтобы язык или программа позволяла легко создавать и менять списки. Список - ядро GTD, поскольку многое в GTD это просто список:Использование готовых программ, хотя и полезно на первых порах, в дальнейшем может привести к трудностям - рано или поздно вы захотите подстроить GTD под себя, и это в сторонней программе может быть нетривиально. Non-actionable stuffПо многим вопросам не нужно делать активных действий, но тем не менее они важны и нужно их хранить:
Зачем делать еженедельный обзор (Weekly Review)?Любая система устаревает - как сама по себе (вашу реализацию GTD придётся время от времени допиливать под обстоятельства), так и данные, которые в ней содержатся (проекты, активные шаги и цели). Поэтому как бы вам не было лениво, Еженедельный обзор есть самая важная привычка в деле GTD.Схематично еженедельный обзор можно представить в виде:  В Интернете вы найдёте массу рекомендаций о том, как делать Еженедельный обзор за рулём, под водой и в коленно-локтевом положении, но горькая правда всегда одна: либо вы его делаете регулярно (и это входит в привычку), либо вся эта изящная GTD-система перестаёт на вас работать. Ключ на старт!Всё запланировано, разложено по полочкам, загружено и распечатано - время, собственно, делать дело! Вся эта GTD-система от товарища Аллена на то и создана, чтобы позволять делать дела быстрее и эффективнее. При этом решения принимаете вы, руководствуясь четырьмя критериями:
 Всякий раз, когда ваши мысли мутны, неясны или бесцельны, стоит подняться над ситуацией и подумать на другом горизонте:
Ясность - одно из проявлений полного тумана. Чтобы видеть ясно, заберитесь повыше. Достигаем перспективы (Perspective) с помощью GTDНужно мыслить перспективно для того, чтобы ставить себе цели и формулировать проекты для достижения этих целей. Здесь нам снова пригодится GTD: будучи структурированным подходом для самоорганизации, GTD поможет разложить проекты, зоны ответственности, цели, видение и назначение. Аллен предлагает аэрокосмическую аналогию по высотам - чем больше высота, тем более абстрактные и перспективные идеи там лежат:
Поэтому самая сложная часть GTD - взлётная полоса: создание структуры, которая содержит все ваши действия - сложное занятие. Наоборот, описание назначения ваших проектов (и жизни) и принципов - просто (это просто список), но формулировать их, по понятным причинам, нелегко.  Начнём с самого приземлённого уровня, как советует Дэвид Аллен - со взлётной полосы. 0 футов, Взлётная полоса: Следующие шагиГоризонт Следующих шагов - это список всех активных действий, упорядоченных по проектам, контекстам или приоритетам. Каждый выполненный шаг, по идее, приближает вас к реализации проекта, который с этим шагом связан.Вопрос, который здесь следует задать себе на этом уровне: "Что мне нужно сделать?"  Любой самый навороченный проект можно разбить на последовательность шагов. Иногда проще всего продвинуть проект, задав себе (и окружающим) вопрос: "Так каков следующий шаг?" 10.000 футов: ПроектыГоризонт Проектов, который содержит все ваши проекты, достижимые в течение года. Такой срок объясняется тем, что эти проекты нужно мониторить и обновлять каждую неделю.Вопрос, который здесь следует задать себе на этом уровне: "Что я хочу завершить?"  Проект, как и цель - не то, что вы делаете: вы можете только выполнить шаги, достаточные для того, чтобы проект считать завершённым. Каждый проект должен содержать цель, видение, активные шаги и материалы для проекта. 20.000 футов: Зоны ответственностиГоризонт Зон ответственности (фокуса) содержит список областей или категорий, которым вы отдаёте предпочтение или уделяете особое внимание.Вопрос, который здесь следует задать себе на этом уровне: "Что я хочу поддерживать?"  Зоны ответственности это такой высокоуровневый проверочный список (checklist), который определяет микс ваших проектов. Если вы слишком много работали, есть смысл больше уделить времени отдыху, например. 30.000 футов: Цели и СредстваГоризонт Целей и Средств содержит список целей, которые вам хотелось бы достичь в течение года или двух.Вопрос, который здесь следует задать себе на этом уровне: "Чего я хочу достичь?"  Цели придают вашей лодке устойчивость в океане событий: оценивая, сколько времени и средств отнимет большой проект, вы приобретаете возможность точнее прогнозировать свои действия. 40.000 футов: Видение и Стиль жизниГоризонт Видения и Стиля жизни содержит список интересных, увлекательных, заманчивых долгосрочных целей, мечтаний и желаемого стиля жизни, которые вам хотелось бы достичь. Это не "как добраться отсюда вон туда", а скорее "а что там-то?".Вопрос, который здесь следует задать себе на этом уровне: "Как выглядит долгосрочный успех?"  Если у вас хорошо развито воображение, то можно сделать небольшой коллаж из картинок и текста, который отражает ваши мечты на будущее. Хорошо сделать нечто вроде карты сокровищ:  На этом уровне не обязательно прилинковывать проекты для достижения своих мечтаний - это скорее мотивирующий плакат, видение, перспектива, которая определяет направление ваших повседневных действий. 50.000 футов: Назначение и ПринципыГоризонт Назначения и Принципов - самый философский из всех. Это короткое, но энергичное (а главное правдивое) описание того, зачем вы всё это делаете. В конечном итоге это должен быть ответ на вопрос "в чём назначение вашей компании\жизни?"Вопросы, который здесь следует задать себе на этом уровне: "Зачем я всё это делаю?" и "Я в своей лучшей форме, когда...?"  Самый верхний горизонт часто представляет собой одно предложение с ответом на вопрос для себя "Зачем я это всё делаю?" и списком Принципов (это некие стандарты и ценности, ниже которых вы не позволите себе жить и работать). К этому ещё можно прибавить список цитат, которые вам дороги. Контроль и Перспектива = Капитан и КомандирЭтот пост призван подвести итог более чем шестилетнему опыту использования мной системы GTD. За это время несколько раз сменился формат бумаги (А6 -> A5 -> A4 -> A5), формат электронной версии (текстовые файлы -> чистый LaTeX -> LaTeX + Kile + Markdown + Zim) и прибавилась техника тайм-менеджмента Pomodoro.Сначала живётся в режиме выживания (Survivalist), имея мало контроля и мало перспективного видения. С приобщением к GTD, появилось больше контроля над обстоятельствами. Но способность (и смелость) перспективного видения - не то, что приобретается за неделю, и автор постепенно скатился в микроменеджмент (много контроля, мало перспективы). Обладая контролем над проектами, действиями и идеями, автор начал слишком много фантазировать и редко обновлять GTD-систему, на некоторое время превратившись в Мечтателя (Crazymaker). Прочтение Making it all work имело тонизирующий и оздоравливающий эффект: набранный контроль и упорядоченное мечтательство позволило приблизиться к состоянию "Капитана и Командира", и уверенно выдерживать курс к своим целям, не смотря ни на что.  Не стоит думать, что GTD есть попытка свести всю жизнь к механистическому вычёркиванию заранее запланированных шагов: GTD просто помогает держать картину своих планов и проектов под контролем. Этот пост, например, вообще не был запланирован и никогда не присутствовал в моей системе - просто этим утром какой-то винтик повернулся в голове, и я решил, что это именно то, что стоит сегодня сделать. Как и было обещано, полная картина GTD в виде одного коллажа:
Так или почти так выглядит вся идея Getting Things Done, сформулированная и практикуемая Дэвидом Алленом и миллионами людей по всему миру. Вся схема доступна для загрузки:
БлагодарностиАвтор в неоплатном долгу перед сервисом shutterstock и другими сайтами, откуда были надёрганы векторные картинки для GTD-схемы. Ну и перед David Allen, разумеется, который помог (и делает это по сей день) многим GTDшникам делать дела быстрее, мыслить ширее и поступать смелее. | |||||||||||||||||||||||||||
| Monday, July 29th, 2013 | ||||||||||||||||||||||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | ||||||||||||||||||||||||||||
| 3:04 am | Перенос таблиц из MS Excel или OpenOffice Calc в LaTeX через Calc2LaTeX Это небольшая заметка может пригодится помимо автора этих строк тем, кому нужно переносить или создавать сравнительно простые таблицы из Excel или Calc в LaTeX, потому как создание таблиц в LaTeX это занятие, часто причиняющее адские боли ниже поясницы. Дизайним таблицы в Calc и переносим их в LaTeX через Calc2LaTeXСобственно, Calc2LaTeX это расширение, которое транслирует код из Calc в LaTeX. А что там автор тогда заливал в заголовке про Microsoft Excel? Дык Calc-то уже давно открывает любые* таблицы Excel. Создатели LibreOffice гарантируют это :-)Не будемте отвлекаться на мелочи - лучше о том, как всё это установить. --- любые* - Your Mileage May Vary, как говорят за океаном, но многие таблицы в самом деле хорошо поддерживаются OpenOffice Calc. Установка Calc2LaTeXДля установки идём на сайт и скачиваем плагин (или вот тут моё зеркало).После этого запускаем Calc и идём в меню Tools -> Extension Manager, где нажимаем кнопку Add (Добавить). Добавляем плагин:  На этом установка не заканчивается - нам хочется какую-нибдь кнопку для этого макроса или пунктик в меню. Как нам сообщает "отменная" документация, Some day, I will try to add this button to the extension.Разумеется, этот знаменательный день, пламенно обещанный автором jarom аж в 2009 году, наступит тогда же, когда мир во всём мире, линукс на десктопе и всеобщая экономическая стабильность. Поэтому нам придётся попотеть и ускорить наступление оного счастья собственными мозолистыми руками: Tools -> Customize -> Toolbars (или Menu, если мы хотим добавить Calc2latex в пункт меню)Нажимаем кнопку "Add... ". Далее прокручиваем список "Category" до "OpenOffice.org Macros" слева, и открываем: My Macros -> Calc2LaTeX -> Calc2LaTeXВыбираем интуитивно понятный пукт (команду) в правой части под названием "Main", и нажимаем кнопку "Add".  Теперь кнопку на панели можно переместить или присобачить ей другую иконку (кнопкой Modify):  Так что у вас в Open/LibreOffice Calc должна появиться кнопка для Calc2LateX:  и сейчас мы её начнём неистово тыркать. Конвертирование таблицы Excel или Calc в LaTeXВсё готово для старта, и сейчас мы приступим: открываем или создаём таблицу в Calc, выделяем нужные ячейки и жмём кнопку Calc2Latex, которую создали на предыдущем этапе. При этом появится диалоговое окно, которое даст выбрать нам немного параметров. Результат Calc2LaTeXЛучше, чем ждёшь от ёпенсорца, но хуже, чем надеешься получить.Плюсы:
Минусы:
Как и многий другой опенсорц, плагин, конечно, работает, только очень медленно и несколько коряво. Никакого цветового оформления можно не ждать, но полужирное и курсивное начертание будут переданы. Для того, чтобы сконвертировать первые пять (5!) столбцов, на Core i5-560M 2.66Ghz ушло 20 секунд. Теперь сравнение того, что было в оригинале:  c тем, что выдал плагин:  то есть таблица, конечно, есть, но страшная, как смерть водолаза и потому требует дальнейшей работы. Для самых любознательных: эта таблица может представлять интерес для тех, кто решает Online Box-constrained Convex Quadratic Programming - ограниченные конвексные оптимизационные задачи, причём очень быстро (online). Здесь перечислены алгоритмы и их основные характеристики, протестированные автором этих строк. Если кто может эту таблицу расширить - пишите в комментарии. Эта же таблица в Google Docs: | |||||||||||||||||||||||||||
| Monday, June 17th, 2013 | ||||||||||||||||||||||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | ||||||||||||||||||||||||||||
| 10:01 am | ЛаТеХ для продвинутых. Floatrow - картинки и таблицы в ряд. Как уже обсуждалось в предыдущем посте из серии "ЛаТеХ для продвинутых", одним из самых универсальных средств для контроля над расположением картинок, таблиц и подписей к ним в пределах плавaющего объекта является пакет floatrow. В предыдущей части мы рассмотрели всевозможные способы взаимного расположения картинки и подписи (снизу, сверху, сбоку), выравнивания их по горизонтали и т.п. Этот же пост будет посвящён расположению нескольких объектов (рисунков, таблиц) в ряд. Обратите внимание, что имеется в виду именно расположение нескольких объектов типа figure и/или table, а не нескольких картинок/таблиц (обычно помеченных как а, б, в, ...) в пределах одного объекта, как это делают пакеты Все примеры из данного поста могут быть найдены здесь и здесь в виде tex-файлов готовых к компиляции. Документация к пакету Краткий анонсСначала мы познакомимся с командами Затем будут освещены средства, необходимые для контроля над горизонтальным выравниванием:
И, наконец, будут разобраны способы выравнивания объектов по вертикали, как то
Команда \ffigboxОсновной рабочей лошадкой во всех примерах ниже является команда Она определяет бокс, в который помещается картинка и подпись к ней, например создаст обычный плавающий объект, как произошло бы и без использования \ffigbox, с той единственной разницей, что благодаря \ffigbox автоматически включается горизонтальное выравнивание по центру.  Для таблиц определена аналогичная команда Расположить несколько рисунков в ряд нам поможет окружение
 Горизонтальное выравниваниеВолшебная длина \FBwidthПредыдущий рисунок выглядит очень неуравновешенно, так как ширина отводящаяся на подпись не соответствует ширине картинки. Гораздо более симпатичного результата можно добиться вот так:
 По порядку
Волшебная длина \XhsizeПомимо очень полезной длины Например, в случае, когда одна из подписей очень длинная, под неё может быть желательно выделить побольше места:
 Несколько картинок в рядДо сих пор мы рассматривали расположение только лишь двух рисунков в ряд. Однако, ситуацию легко обобщить для произвольного числа рисунков. Для этого небходимо задать необязательный аргумент к окружению
 Из этого же примера очевидна гибкость использования Вертикальное выравниваниеВесь объектДо сих пор во всех примерах использовались картинки приблизительно одинаковой высоты, т.е. особой нужды в форматировании их вертикального положения не возникало. Если же рисунки отличаются по высоте, то встаёт вопрос об их вертикальном положении относительно друг друга. Эта проблема решается с помощью одной из команд приводит к такому результату:  Только картинкиВ большинстве случаев, однако, необходимо выровнять только картинки, а подписи к ним оставить на одном уровне. Без проблем:
 Здесь использованы два параметра:
floatrow инструктирован выделить под обе картинке блоки одинаковой высоты.
ПодписиДля рисунков, когда подписи размещены под иллюстрацией, нет необходимости их дополнительно "выравнивать": подписи и так выровнены "по верху". Однако у таблиц, когда подписи размещены сверху, так как использована директива или, что то же самое, то подписи автоматически оказываются вырoвненными "по низу", вот так:  Чтобы вырoвнять их "по верху" используем или же
 Полностью код примера выше: открыть
Картинка рядом с таблицейВсе трюки, приведённые выше, обсуждались на примере или картинок, или таблиц. Если картинка и таблица должны находиться рядом, нужно воспользоваться командой\killfloatstyle. Например произведёт следующий результат  И всё-таки subfloatsХотя во введении и было обещано не рассматривать вопросы, связанные с расположением "подрисунков" (subfigures, subtables), стоит отметить, что все вышеприведённые рецепты действуют и в их случае с той лишь разницей, что надо использовать окружение Простой пример ниже демонстрирует это в деталях  Пара пунктов, на которые стоит обратить внимание:
Абсолютно аналогично можно это применить и к таблицам, заменив Заключительный сложный пример для любознательныхПомимо рассмотренных выше трюков, В следующем примере использованны эти возможности:

Подведение итоговПакет Все примеры из данного поста могут быть найдены здесь и здесь в виде tex-файлов готовых к компиляции. | |||||||||||||||||||||||||||
| Monday, June 10th, 2013 | ||||||||||||||||||||||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | ||||||||||||||||||||||||||||
| 12:16 pm | ЛаТеХ для продвинутых. Floatrow - расположение иллюстрации и подписи Одним из самых часто задаваемых вопросов о LaTeX является вопрос о вставке картинок. Рисунки чаще всего помещаются в так называемые плавающие объекты (floats). То, как ЛаТеХ размещает эти объекты, уже обсуждалось в одном из предыдущих постов из серии "ЛаТеХ для продвинутых". Теперь же стоит уделить внимание содержанию плавающего объекта: расположению картинок и подписей к ним внутри объекта float. Одним из самых продвинутых средств в этой области является пакет floatrow. Он предоставляет удобный интерфейс для
Целью данного поста является продемострировать возможности предоставляемые Все примеры из поста могут быть найдены здесь и здесь в виде tex-файлов готовых к компиляции. Документация к пакету Для нетерпеливыхПосле загрузки пакета настройка параметров плавающих объектов осуществляется командой где тип флоат может быть, например, figure или table. Наиболее интересные параметры, значение которых рассмотренно подробнее далее в тексте, приведены в таблице ниже
Подпись сверху, подпись снизуПодпись к рисунку, схеме или таблице можно располагать сверху, снизу или сбоку от самого объекта. Традиционно, подписи к таблицам располагают над ними, тогда как рисунки подписывают снизу. Конечно, этого можно добиться переставляя команду позволит автоматически перенести подписи ко всем таблицам наверх, все wrapfigure останутся подписанными снизу, а обычные figure плавающие объекты будут подписаны сбоку.  \floatsetup[]{}. Она принимает два аргумента. Первый, необязательный, задаёт тип плавающего объекта. Если он не указан, то опции, следующие во втором (обязательном) аргументе будут применены ко всем типам floats в документе. В данном случае мы использовали опцию В комбинации с поместит подпись сбоку справа внизу. Параметры выделит на картинку 60% страницы, а всё остальное отдаст под подпись. Заметьте, что здесь был использован ещё один параметр floatwidth. Обычно этот параметр задаёт ширину отводящуюся под весь флоат. Однако, если подпись находится сбоку, то floatwidth задаёт ширину отведённую под непосредственно саму картинку, вставленную, например, посредством \includegraphics{}. Опции необязательно задавать глобально. Если использовать Пропуски, поля и выравниваниеВсемогущая команда Кроме того, в примере задана ширина floatwidthвсего float равной половине ширины текста и заказано разместить весь float слева: margins=raggedright (напомним, что по умолчанию и без floatrow, ЛаТеХ выравнивает плавающий объект по центру горизонтали).  margins принимает также значения centering (по умолчанию), raggedleft и др. Если параметр приводит к такому результату  Все параметры схематически изображены на рисунке ниже.  Выравниваем подпись по ширине картинкиДо настоящего момента мы в подробностях рассмотрели всевозможные варианты взаимного расположения и выравнивания картинки и подписи к ней. Один весьма специфический случай, однако, остался без внимания: как сделать так, чтобы весь флоат (то есть картинка и подпись) по ширине совпадали с шириной картинки. При этом хотелось бы, чтобы ширина определялась автоматически, а не вручную посредством Сделать это можно с помощью команды
 floatrow определяет длину \FBwidth, которая равна ширине текущего объекта. Для таблиц, просто заменяем СтилиПакет позволяет создавать стили, которые могут впоследствие быть использованы как Мы не будем здесь рассматривать создание собственных стилей , а лишь заметим, что floatrowпредоставляет набор стилей, некоторые из которых вполне могут буть использованы в реальных документах.
Стили можно комбинировать с другими командами, например
ЗаключениеИтак, пакет Осуществляется это посредством команд где тип флоат может быть, например, figure, table, wrapfigure, и т.п. Список наиболее интересных параметров можно найти в таблице приведённой выше. Основным достоинством Во всей своей красе Все примеры из данного поста могут быть найдены здесь и здесь в виде tex-файлов готовых к компиляции. Документация к пакету | |||||||||||||||||||||||||||
| Monday, May 27th, 2013 | ||||||||||||||||||||||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | ||||||||||||||||||||||||||||
| 3:35 am | Sleep as Android - умный будильник для Android со статистикой и фазами сна Некоторое время назад был пост про наручные часы с гуманным будильником по имени Sleeptracker. Принцип их работы основан на попытке увязать показания акселерометра и фаз сна. Всё отлично, кроме высокой цены (около 100$) и необходимости надевать их каждую ночь. Современные смартфоны напичканы всеми вообразимыми датчиками, включая акселерометры, так что кому-то должна была постучаться в голову светлая мысль реализовать умный будильник для Android на смартфоне, благо смартфоны есть у многих и на этом можно срубить пиастров. Так и поступил товарищ Petr Nálevka, который вместе с Martin Šťava написали приложение Sleep as Android. Приложение платное и стоит безумные (по меркам пользователей Android) деньжищи - почти целых 3 доллара. Автор этих строк, придушив жабу и выложив кровные, делится впечатлениями и сравнивает Sleep as Android со Sleeptracker. Принцип работы умных будильников... сравнительно прост: снимаются показания акселерометра, которые пропорциональны движениям тела во время сна. Амплитуда акселерометра делит фазы на лёгкий сон и глубокий сон . Такое с виду примитивное деление на самом деле даёт весьма реалистичную картину сна: То есть фаза глубокого сна (REM) в самом деле неплохо описывается акселерометром (изображение взято со страницы 11, Figure 2-7, Principles and practice of sleep medicine, 5th edition, Chapter 2 - Normal Human Sleep : An Overview). Хотя Sleep as Android не может (да и не преследует такой цели) тягаться с клиническими исследованиями, разработчики Sleep as Android выкатили страницу с пояснениями того, как приложение работает. Чем больше пользователь дрыгается ночью, тем больше амплитуда, выдаваемая акселерометром смартфона. Авторы утверждают, что акселерометры смартфонов не сильно хуже таковых на медицинских приборах: Moreover, during development of Sleep as Android the accuracy of the mobile phone sensors has been tested and compared with satisfactory results to special accelerometers used in medical applications (especially in psychiatry).Вообще, в процессе написания поста автор набрёл на весьма занятную книгу: Principles and Practice of Sleep Medicine: Expert Consult - Online and Print, 5e (PRINCIPLES & PRACTICE OF SLEEP MEDICINE. [Amazon]Главы этой книги можно скачать бесплатно, что довольно удивительно для научного справочника. Можно полистать и найти немало интересного в Chapter 2 – Normal Human Sleep : An Overview и в главе Chapter 141 – Monitoring and Staging Human Sleep, откуда автор этих строк надёргал немного текста и картинок. Засовываем и напяливаемТак как мы не собираемся проводить научных исследований на себе, то достаточно включить режим отслеживания сна в приложении и положить смартфон рядом с собой, а ещё лучше - под подушку. На подушках обычно есть наволочки, и чтобы не скинуть на пол во сне свой драгоценный смартфон, засовываем его под подушку, напяливаем сверху наволочку и жмёмУмный будильник Sleep as Android в действииСпят усталые игрушки, Книжки спят, Одеяла и подушки Ждут ребят, Даже сказка спать ложится, Чтобы ночью нам присниться, Глазки закрывай, Баю - бай... (C) Интерфейс Sleep as Android написан гуманоидами, поэтому сравнительно прост в освоении. Для работы нужно выставить время для будильника и не забываем его активировать:   Это всё - далее нажимаем на кнопку Sleep tracking, кладём смартфон под подушку и ложимся спать. Здесь стоит отметить несколько важных моментов:Последние версии Sleep as Android очень экономно расходуют батарейку: за всю ночь может потратить не более 10-15% от 2000 мАч. Так что даже если батарейка заряжена только наполовину - её должно хватить. Утром вас разбудит   Что нам дают эти графики? Эти графики нам дают статистику сна, и вот она-то как раз очень важна. Статистика сна в Sleep as Android Statistics are like miniskirts - they give you good Statistics are like miniskirts - they give you good ideas but hide the important things. — Ebbe Skovdahl Что бы там не говорили, а статистика, выполненная с умом и без желания наврать, рассказывает много интересного тому, кто понимает, что делает. Так и в в "умном будильнике": вкладка Stats покажет выжимку данных о сне за последнее время. Самым важным параметром, конечно, является время (и процент) глубокого сна. Все данные хранятся в каталоге /sdcard/sleep-data во внутренней памяти смартфона (файл sleep-export.csv). При желании можно выдрать статистические данные оттуда самостоятельно.  Внизу вкладки Stats находится Detailed statistics, которая поведает нам немало интересного (изображение слева, кликабельно). Можно увидеть процент глубокого сна (данные и среднее значение), рейтинг сна (который выставляете вы сами) и время, когда будильник прозвенел ещё до выставленного времени. Можно изменить временной интервал - за неделю, две недели, месяц, полгода или год. Но куда больше полезного можно выжать с помощью плагина SleepStats (платный, стоит 1.5 долларов). Помимо Trend и Sleep rating, можно посмотреть на статистику сна и Pattern (то есть на модель сна). Pattern (скриншот в центре) особенно интересен, так как содержит много полезных данных на одном рисунке. Время отхода ко сну и просыпания можно видеть одновременно с диаграммами глубокого и лёгкого сна (показа синим и зелёным цветом соответственно).    Так же плагин SleepStats содержит весьма навороченный статистический анализ данных, на основе которых предлагается оптимальная длительность сна и время отхода ко сну:   На скриншоте слева можно видеть рекомендации по хорошему сну, сделанные по данным за четыре месяца. Вообще, плагин SleepStats определённо стоит своих денег, выдавая много ценной информации для улучшения сна. Что, кстати, видно на динамике увеличения продуктивности по данным Pomodoro. Предсказания, как и многое другое в статистике, тем точнее, чем больше данных (то есть чем чаще вы пользуетесь программой). Sleep Cloud BackupSometimes your cloud rains and there is nothing you can do about it (c) Anonymous Конечно, cloud это не бекап, и тем не менее очень удобно (на время, по крайней мере) хранить свои не очень важные данные в Dropbox. И плагин SleepCloudBackup (платный - стоит 1.3 доллара) как раз сохраняет данные о вашей статистике сна в Dropbox. Всё, что для этого нужно - привязать свой Dropbox аккаунт к плагину SleepCloudBackup.   После этого на вкладке Graphs появится слева от настроек иконка типа "Recycle" - это и есть вызов плагина SleepCloudBackup для бекапов в Dropbox. Он же может загружать и восстанавливать данные о сне, если вдруг что-то случилось с памятью смартфона. Конкуренты Sleep as AndroidТакое место пусто не бывает: умный будильник Sleep as Android имеет множество конкурентов, хотя они менее навороченные. Перечислю наиболее выдающиеся из них:
 Sleep as Android vs SleeptrackerОни используют один и тот же принцип, так выдают ожидаемо похожие данные. Временное окно для умного будильника Sleep as Android (30 минут) я взял из данных Sleeptracker. Сравнение длительности сна и Fall Asleep time похожи на обоих устройствах, так что теперь использую смартфон вместо Sleeptracker. Кроме того, ранним утром выползать из-под одеяла всё равно не хочется, а на смартфоне можно ещё проверить почту.ЗаключениеПри всей своей простоте, смартфоны с акселерометром и программами для отслеживания сна помогают лучше спать и просыпаться бодрее и свежее. Но самое главное - это возможность узнать намного больше о своём сне, не прибегая к медицинскому обследованию. Так что теперь ваш смартфон может заменить ещё и будильник! | |||||||||||||||||||||||||||
| Sunday, May 5th, 2013 | ||||||||||||||||||||||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | ||||||||||||||||||||||||||||
| 6:02 pm | ЛаТеХ для продвинутых. Как подружить LaTeX и Inkscape. (La)TeX является одной из наиболее продвинутых систем обработки текста. Тексты созданные в ЛаТеХе, обычно естественно-научной направленности, легко узнать не только по красивым формулам, но и по исключительно сбалансированному тексту. В тоже время, графики и рисунки, обычно созданные в "посторонней" программе и импортированные в ЛаТеХ, зачастую изрядно портят внешний вид документа. Хотя их расположением занимается ЛаТеХ (см. пост о плавающих объектах), сам внешний вид рисунков полностью на совести пользователя. Одним из наиболее бросающихся в глаза недостатков рисунков является несоотвествие шрифтов (размера и начертания) между иллюстрацией и основным текстом. В одном из предыдущих постовмы разобрали как с этим бороться в случае графиков функций, импортируемых из MATLAB. Одним из самых удобных средств для создания рисунков (поясняющих иллюстраций, диаграм, схем и т.п.) является Inkscape: свободный, кросплатформенный векторный графический редактор. Цель этого поста: применение аналогичного трюка для экспорта иллюстраций, схем и рисунков из Inkscape таким образом, что текст на них будет соответствовать использованному в основном тексте. Импорт рисунков Inkscape в LaTeXОсновная идея и простой примерInkscape создаёт рисунки в формате svg. Наша задача: "красиво" вставить их в ЛаТеХ-документ. Итак, по порядку: 
 Оптимизация процессаУ описанного выше процесса есть два больших недостатка. Во-первых, каждый раз, когда что-то изменено в Inkscape, надо заново сохранять файл как PDF+LaTeX, тыкая мышкой в разные пункты меню. Кроме того, включение файла срабатывает только, если файлы картинок находятся в текущей директории. От обоих недостатков можно легко избавиться, используя следующий код в ЛаТеХ-файле: Здесь для начала указано, что \includegraphics должен искать картинки в поддиректории figs. Затем определены две новые команды. Первая Вторая Для компиляции используем Возможности и ограниченияПосле вставки в ЛаТеХ, не должно быть никаких проблем с цветами, градиентными заливками и т.п. вещами: они сохранены в pdf-файле. С текстовыми же эффектами могут быть проблемы. Поддерживается только цвет и поворот текста. Такие навороты, как "текст вдоль линии" или "отображение" работать не будут, хотя в большинстве случаев они и не нужны. Единственным действительно неприятным недостатком является то, что не поддерживается текст в несколько строк.  Связка MATLAB - Inkscape - LaTeXИногда приходится "усовершенствовать" график, например, указав стрелками на какие-то его особые точки или разместив дополнительный рисунок поверх графика. Инкскейп идеально для этого подходит: он может "читать" файлы в формате eps и pdf. Однако, если график построен в MATLAB, то лучше его сохранить напрямую в svg-формате, вместо промежуточного (для наших целей) eps. Сделать это очень просто с помощью функции plot2svg, которую можно скачать с MATLAB Central. На всякий случай, файл Строим график, а затем сохраняем его как, например,   ЛаТеХ в ИнкскейпеИтак, прямая задача — экспорт рисунков из Инкскейпа в ЛаТеХ — решена. Но иногда приходится решать и обратную задачу: вставлять формулы из ЛаТеХа в Инкскейп. Сделать это можно двумя способами. Способ первый: Render LaTeX FormulaСтандартное расширение Инкскейпа (из базовой поставки) позволяет легко и просто вставить формулу. Идём в пункт меню Extensions, выбираем Render, а потом LaTeX Formula.  Если в вашем Инкскейпе отсутствует пункт меню "LaTeX Formula", то попытайтесь найти файл extension-errors.log и посмотреть, что именно произошло. Например, в Windows велики шансы, что Инкскейп не смог найти програмку pstoedit, необходимую для функционирования "LaTeX Formula": если дело действительно в этом, то установите pstoedit и добавьте его в путь Способ второй: Tex TextЭто расширение не входит в базовую поставку Инкскейпа, но его можно установить самостоятельно, скачав отсюда. Пожалуй, наиболее очевидным преимуществом Tex Text перед описанным выше способом является возможность подключать свой стилевой файл, через который можно подгрузить другие пакеты или определить свой команды  Заключение и выводыИтак, экспортировать рисунки из Инкскейпа совсем несложно. Процесс легко автоматизировать с помощью простого ЛаТеХ-скрипта, автоматически конвертирующего svg-рисунок в связку PDF (картинка) и ТеХ (текст), которые вставляются в ЛаТеХ-документ один поверх другого. Достоинством этого метода является весьма неплохо выглядящий результат (рисунок с ТеХ шрифтом, формулами, ссылками) при минимальных затратах времени. Хотя мы рассмотрели данный рецепт на примере Инкскейпа, аналогичные методы могут быть использованы и с другими программами. Из графических редакторов, ЛаТеХ неплохо поддерживается Xfig: об этом написано, например, здесь. Справедливости ради, стоит отметить, что весьма неплохих результатов можно также добиться с помощью inkscape2tikz. Но это уже совсем другая история... Все примеры из данного поста доступны для скачивания по адресу tinyurl.com/amorua-inkscape. Зеркала на случай сбоя: зеркало1зеркало2 | |||||||||||||||||||||||||||
| Sunday, April 21st, 2013 | ||||||||||||||||||||||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | ||||||||||||||||||||||||||||
| 10:32 pm | Zim - настольная вики, структуризатор и каталогизатор в одном флаконе: zim wiki outliner Согласно заветам Ильича, коммунизм есть советская власть плюс электрификация всей страны. Так и Zim, в духе духа духовных предков, представляет собой каталогизатор (outliner) плюс возможность пользовать вики-разметку. Простой и незатейливый, но полезный в хозяйстве, Zim поможет простым колхозникам быстро разгрести ворох заметок, файлов и набросков и превратить в организованную структуру, расфасованную по каталогам. Кто такой Zim и что умеет?Ни майнтейнеры Debian, ни сам автор Zim, похоже, не вполне могут описать, что же такое Zim. Нет, это не вики в чистом виде - вернее, не MediaWiki, которую ожидаешь увидеть при слове Wiki. И не текстовый редактор, как пишется в пакете Debian:zim - graphical text editor based on wiki technologiesЭто не редактор, а скорее outliner, то есть структуризатор и каталогизатор информации - что-то вроде Notecase. То есть каталогизатор с вики-разметкой и простеньким редактором текста.   Установка Zim в Debianпроста и незатейлива - пакет есть в репозитории Debian, и всё легко:apt-get install zimотнимет всего пару мегабайт. Несмотря на то, что на сайте есть пакет только для убунты, в Debian он отлично ставится и работает. Можно скачать отсюда и установить (или обновить) через # dpkg -i zim_0.59_all.debи если у вас установлены необходимые зависимости (указано для версий до 0.59):
Первый запуск ZimПри первом запуске Zim попросит создать новый блокнот (Notebook), который потом будет открыт. После этого начинаем набивать наш новый блокнот данными. Скорее всего, у вас уже есть некоторое количество заметок, записок, набросков и раскиданных по разным местам PDF-файлов и рисунков - вот это всё можно легко привести к одной упорядоченной структуре, в которой легко ориентироваться.Правая кнопка мыши в Zim - наш друг и союзник, с её помощью можно создавать новые страницы и подстраницы.  После того как вы создали свой ноутбук, Zim откроется с простеньким окном для редактирования текста - теперь можете начать писать заметки. По мере ввода текста, вы можете ввести имя новой страницы (начиная с двоеточия :) и Zim автоматически создаст эту страницу. Если начать строку со звёздочки "*", то она будет преобразована в список. Чтобы выйти из режима маркированного списка, просто нажмите Enter дважды. Начните строку со "[]" (две квадратные скобки, затем пробел) и скобки будут преобразованы в пустые флажки для ToDo-списка.  Имеет место быть отличный полнотекстовый поиск как по заметке, так и по всему блокноту, и на не слишком больших блокнотах работает замечательно:  Структурирование информации в Zim: каталоги и подкаталоги из заметокКаждая заметка (страница) хранится в своём отдельном plain-text файле с расширением .txt, а каталог с тем же именем - для вложений (рисунки, PDF-файлы и всё прочее). Если страница содержит подстраницу (Subpage), то в каталоге для вложений появятся ещё файлы .txt - это дочерние заметки. Это весьма удобно, так как позволяет синхронизировать данные с Dropbox и смартфонами.Поэтому базу заметок Zim можно открыть обычным текстовым редактором и файл-менеджером. Собственно, вот как выглядит структура каталогов:  Вставка иллюстраций и вложенийКартинки можно вставлять в текст заметок - картинки вставляются и отображаются прямо на странице, а сама картинка попадает во вложения (у каждой замети "Заметка.txt" есть каталог рядом "Заметка" - для вложений). Для этого заходим в меню Tools -> Start Web Server, далее запускается вебсервер на порту 8080 и можно запускать броузер для просмотра:   Плагины в ZimВот где настоящий клондайк! Большое количество полезных плагинов поставляются вместе с Zim, так что можно порыться в списке плагинов и найти немало интересного, вызвав меню Edit -> Preferences -> Plugins: Из наиболее полезных (для версий 0.5х) мы имеем:
Поддержка систем управления версиями (Version Control Systems)Zim не только умеет каталогизировать информацию, но и поддерживает автоматическое управления версиями наших справочных данных. Это отличная возможность, особенно когда блокнот Zim является частью большей системы (например, GTD).В моём случае используется Mercurial, и Zim при добавлении или перемещении справочной информации, хранимой в виде заметок Zim, добавляет или удаляет соответствующие файлы, которые потом коммитятся вместе с другими изменениями. Занятно, но похоже, что Zim (0.5x по крайней мере) не добавляет attachments в систему управления версиями, только страницы.  Ссылки и информация к размышлениюОфициальный сайт Zim с кучей скриншотов, годный туториал на английском в двух частях, и ещё один пост о десктопном применении Zim. Есть так же плагин-клиппер для Firefox.Аналогом Zim можно считать Outwiker и Notecase. | |||||||||||||||||||||||||||
| Sunday, April 7th, 2013 | ||||||||||||||||||||||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | ||||||||||||||||||||||||||||
| 6:45 pm | ЛаТеХ для продвинутых. Как подружить LaTeX и MATLAB: вставка рисунков из MATLAB в документы LaTeX В документе всё должно быть прекрасно — и текст, и картинкиБлагодаря ЛаТеХу научные работники (и не только) получили возможность создавать красивые, уравновешенные документы с чётко просматривающейся структурой. Однако "сфера влияния" ЛаТеХа распространяется только на текст и формулы, а внешний вид графиков и иллюстраций находится полностью на совести автора. И вот здесь-то и начинаются полные разброд и шатания: на некоторые рисунки трудно смотреть без слёз :) Целью данного поста является продемонстрировать один из способов создания математических графиков гармонично сочетающихся с окружающим их текстом. Постановка задачиЧто отличает рисунок гармонично вписывающийся в основной текст от рисунка плохого? Безусловно, содержание, размер и расположение являются важными эстетическими параметрами. Однако наиболее бросающимся в глаза диссонансом, свойственным львиной доле естественно-научных рисунков, являются шрифты. Да-да, именно шрифты... Речь идёт о подписях к осям графиков, о легендах и т.п. Порой создается ощущение, что у автора серьёзные проблемы со зрением: скажем, рядом с текстом набранным Times 12pt вдруг оказывается график с подписями 16-ым шрифтом... Или, ещё лучше, нечитаемым 8-ым... А о соответствии типа шрифта (начертания) между рисунками и текстом и мечтать не приходится! Итак, наша основная задача: графики, шрифт на которых совпадает по размеру и начертанию с основным шрифтом документа. Все дороги, которые ведут в РимДостичь нашей цели можно разными путями. Наиболее общеизвестные из них, в порядке убывания ортодоксальности:
Каждый из этих способов имеет свои достоинства и недостатки, обсуждение которых выходит за рамки данного поста. Последний способ является, по мнению автора, оптимальным по параметру "отношение качества результата к затраченному времени". Поэтому, именно ему и будет уделено внимание. В этом посту мы рассмотрим алгоритм экспорта графиков из MATLAB в LaTeX. Выбор Матлаба для построения графиков диктуется исключительно личными предпочтениями автора. Аналогичные методы применимы и к другим программам — об этом в самом конце. Как ЛаТеХ с Матлабом подружитьЦельСобственно: экспорт графиков из Матлаба в ЛаТеХ. При этом предполагается, что подписи и т.п. на графике должны сочетаться с основным текстом.
Желаемый результат изображен ниже. Специально выбран нестандартный
фонт (Kepler-подобный из 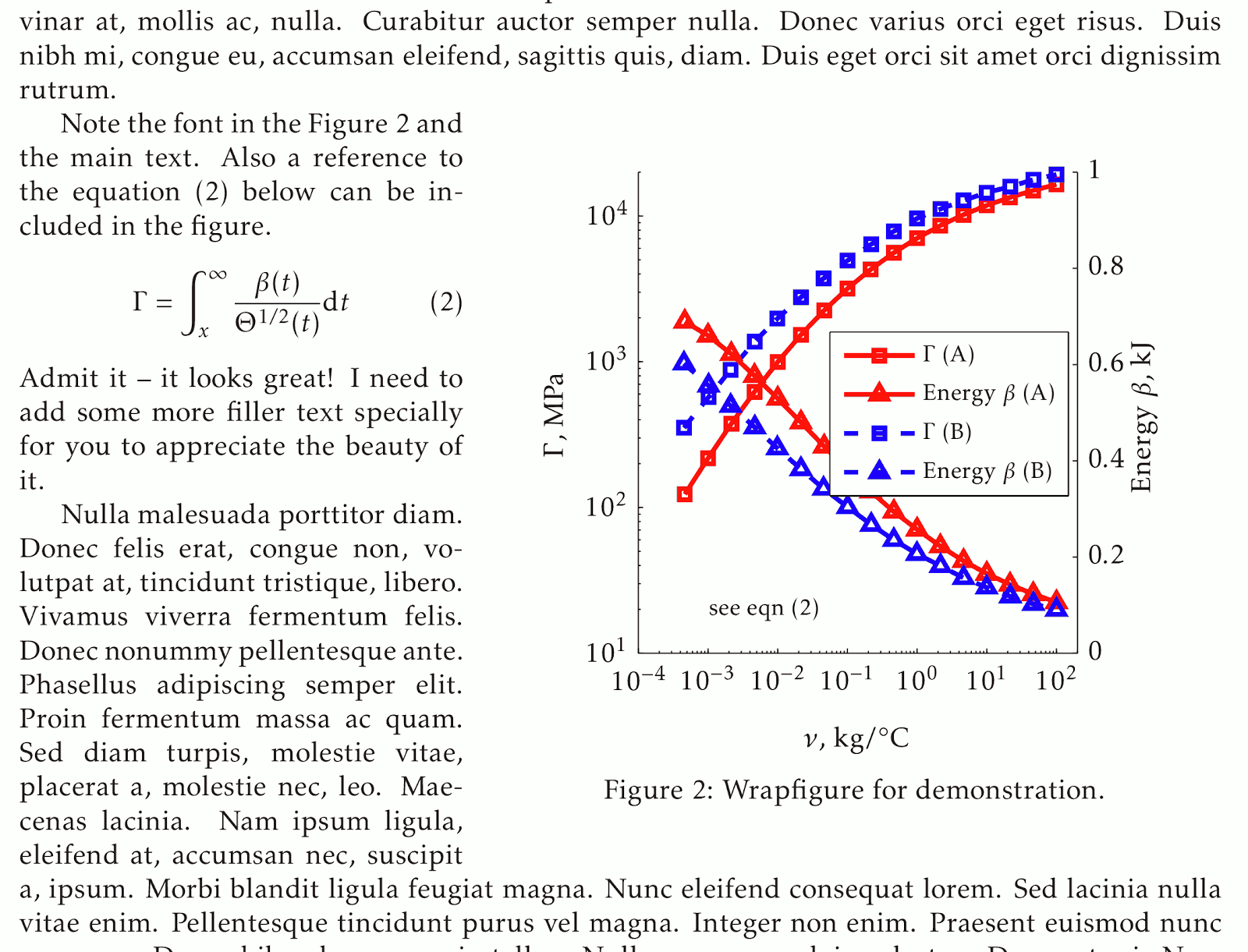 Средства
Матлаб, версии новее 7.6 (release name 2008a).
Кроме того, скрипт
matlabfrag.m.
Его можно скачать самостоятельно, но он (вернее его улучшенная версия)
есть и в архиве с примерами из
этого поста: tinyurl.com/amorua-matlabfrag.
Поместите его в текущую директорию:
туда где будут находиться ваши скрипты для построения графиков.
Поместите туда же файлы
ЛаТеХ. Нам понадобится пакет
Если Строим графикЗдесь всё почти как обычно:
Теперь по порядку:
Вставляем график в документ ЛаТеХ
Как видно из предыдущего рисунка, ЛаТеХ-текст будет вставлен
с помощью команды
Обратите внимание, что имя файла картинки без расширения. Если картинка находится не в текущей директории, то нужно указать путь к ней. Кроме того, размер шрифта в самом первой строке установлен в 12pt, в соответствии с размером шрифта на рисунке в Матлабе.
Компилируем командой
Пакет Результат наших усилий показан внизу. Как видите, на графике использованы Computer Modern шрифты ЛаТеХа, размер которых совпадает с размером, использованным в тексте (см. подпись к рисунку).  Тонкая настройкаТеперь, когда последовательность действий в достаточной степени понятна из предыдущего примера, можно обратить чуть больше внимания на детали. Деталь нулевая
Деталь, к Если использовать myfigure(10,8), то размер картинки
будет 10см на 8см. Если задать только первый аргумент
myfigure(10), то функция сама посчитает высоту исходя
из золотого сечения. Файл myfigure.m находится в архиве
с примерами.
Деталь первая: UserData matlabfrag
В принципе, необязательно пользоваться
интерпретатором
latex в Матлабе. Функция Недостаток этого способа в том, что придётся набирать больше текста. Кроме того, картинка, как её покажет Матлаб, вообще говоря, будет отличаться от той, которую вы увидите в ЛаТеХе. Зато такой способ гораздо более гибок. Он позволяет вставлять в текст подписей команды, определённые в ЛаТеХ документе, о которых Матлаб ничего не знает. Например: использует команду \myint, а кроме того, ссылается
на уравнение из основного текста.
Обратите внимание на то, как добавляется UserData к легенде:
здесь для облегчения процесса использована функция
Дело в том, как Матлаб хранит текстовое содержимое легенд: если легенды две, то их текст будет сохранен в 6-м и 3-м элементах "детей легенды". Если легенды три, то в 9-м, 6-м и 3-м. И так далее.
Файл Деталь вторая: текстовые эффекты
Функция даст эффект, очевидный из картинки ниже. 
Обратите внимание, что для набора текста в несколько строк
использованны cell arrays, вроде
Деталь третья: поддержка русского языкаС русским тоже никаких проблем: просто, набираем подписи и текст на русском. Только не забываем в ЛаТеХ-документ вставить в преамбулу
Результат:  Деталь четвертая: подписи к меткам на осяхИногда хочется заполучить у меток на осях не числа типа 3.14, а что-то посимпатичнее, вроде числа "пи". Делается это просто:
Всё остальное — как прежде. Результат:  Деталь пятая: необязательные аргументы
| |||||||||||||||||||||||||||
| Sunday, March 31st, 2013 | ||||||||||||||||||||||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | ||||||||||||||||||||||||||||
| 11:15 pm | Отложенная отправка электропочты: scheduled email Сегодня первое апреля, и автору хотелось немного отдохнуть. Чего мне не хватает в интерфейсе Gmail, на фоне всех этих бесполезных свистулек и бубенчиков, так это отправки электропочты по расписанию. Например, у Васи Пупкина день рождения в субботу, а я в субботу колесю на своём После долгих блужданий нашёлся небольшой сайт LetterMeLater, который делает как раз это: отправляем на него письмо, в нём указываем срок, и всё. Оно приходит в точно назначенный день и час! Настройка Нужно зарегистрироваться на сайте LetterMeLater чтобы иметь возможность им пользоваться. При этом они будут принимать почту только с адреса email, с которым вы зарегистрировались. После этого заходить на сайт не обязательно - и это самая сладкая возможность, ибо можно отправлять отложенную электронную почту прямо из своего почтового клиента. Что позволяет делать LetterMeLater:
Ахтунг! Прайваси! Естественно, что сайт организован не просто так, а тайной массонской ложей мировой закулисы. А как может быть иначе, если даже в Gmail есть реклама, а тут её нет? Так что ваши письма, скорее всего, станут доступны злобным агентам ЦРУ и Моссада, которые скопируют всю ценную информацию оттуда в секретные досье. В чём они открыто признаются в своих Terms and Conditions: The user's email address (as well as any other personal information) will be kept strictly confidential ["Зуб даём и спамерам ваш адрес электропочты не засветим даже с утюгом на животе!"]. While attempts are made to secure personal information from public viewing, lettermelater is not responsible for the failure of any such attempts ["Конечно, мы постараемся не сильно светить содержанием вашей личной переписки направо и налево, но ничего не обещаем"]. All information you submit to lettermelater may be accessible to lettermelater owners, employees, partners, or other associates may be viewed or modified by them, ["Конечно, мы не устоим перед соблазном, чтобы не посмотреть в ваши письма при случае - мало ли, может вы там героин по три бакса за тонну продаёте, мы же тоже люди..."] or others associated with the operation of lettermelater, for any reason at their sole discretion, including but not limited to ["И другим тоже дадим поглядеть, мы же не жадные..."] (a) debugging or maintaining the services lettermelater provides ["Где подебажим, а где пошпионим..."] and (b) ensuring compliance with the Terms and Conditions ["... и убедимся, что вы правила не нарушаете"].В общем, для поздравлений с днём рождения и напоминаний о встречах (если вы обогащённым ураном не приторговываете налево, конечно) оно подойдёт. Но шибко приватную информацию я бы там слать не стал. Но если это не пугает, можно пользоваться, о чём дальше. Отложенная электропочта Для отправки сообщений в поле адреса выставляем me@lettermelater.com Теперь переходим в тело сообщения, и там пишем две строки: to:Первое понятно - кому отправить, пишем адрес электронной почты: to: nigerianletters@spam.govЕсли адресатов несколько, то пишем их отдельными строчками. С полем when немного сложнее, так как нужно знать GNU format. Например:
Процесс Например, хотим отправить спамерам утренний привет в восемь вечера с копейками. to: nigerialetters@spam.govПосле отправки сообщений, придёт либо подтверждение об отправке:
либо сообщение об ошибке:
Здесь нужно сказать, что кириллические письма сервис может обрабатывать как-то криво. Например, могут обрезаться строки, особенно если содержат форматирование (несколько писем было так искажено при отправке из Gmail). Письма на латиннице обрабатываются нормально. Альтернативы:

Знающие всё на белом свете Анонимусы могут предложить другой вариант отправки отложенных сообщений.
| |||||||||||||||||||||||||||
| Sunday, March 24th, 2013 | ||||||||||||||||||||||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | ||||||||||||||||||||||||||||
| 10:34 pm | Китайский Android-смартфон THL W5: приятный сюрприз по вменяемой цене Некоторое время назад я писал о том, как завёл себе Андроида - гигантскую электроовцу под названием HTC Desire HD. Время шло, смартфон был в активном использовании, несмотря на (частично) алюминиевый корпус, постоянные сжатия от тесного чехла HTC не понравились, и через некоторое время накрылся экран. По гарантии смартфон был отправлен обратно (+ почтовые расходы), но после ремонта через некоторое время экран стал отходить от корпуса. В общем, надо искать замену - пока смартфон жив. И тут автор этих строк заметил, что китайцы из компании THL для внутреннего узкоглазого рынка клепают вполне себе неплохие агрегаты... HTC, THL и другие китайские балалайкиКомпания THL расшифровывается как Technology, Happy Life, и представляет собой лавку дядюшки Ляо, разросшуюся до размеров нескольких десятков магазинов с фабрикой по поклёпу смартфонов. Как и вся продукция из Китая, она чем-то напоминает что-то, что уже кем-то сделано. В случае с THL их смартфоны, сделанные по сходному дизайну, чем-то напоминают продукцию HTC (а конкретно HTC One X) и Samsung, которая, в свою очередь, сильно напоминает продукцию Apple.Работая в интернациональном коллективе, невольно замечаешь особенности конкретных наций в деле инженерии. Конкретно у китайцев всё очень здорово, когда нужно выдать большой объём работ при точно известной схеме. То есть, например, задача genome sequencing для них - идеальна: схема есть, оборудование есть, и просто нужна толпа квалифицированных исполнителей. Всё становится намного хуже, когда нужно придумать что-то новое, особенно если до этого народ приходил к выводу, что так сделать нельзя. Один китаец меня как-то спросил: какой метод для создания новых вещей? Как ты придумываешь новое? Он искренне думал, что я сейчас ему дам книжку, в которой это написано. Я же честно ему ответил: рву на жопе волосы :-) Он после этого меня больше ни о чём не спрашивал, хотя я ответил ему предельно честно.Почти весь модельный ряд THL построен на базе одной и той же платформы (SoC, System on Chip) MTK6577, в которую они вставляют разные экраны и батарейки. Так как THL, что называется, "без роду и племени", то денег за свои Душа горит огнём желанийСобственно, автору этих строк хотелось получить за вменяемые (до 300 долларов) деньги смартфон вида:
THL W5 3G Smart Phone MTK6577 1GB RAM Dual Core Android 4.0 4.7" IPS ScreenДолго ли, коротко, но я набрёл на смартфон вот с таким длинным названием. По размерам он почти такой же, как мой старый HTC Desire HD, только длиннее за счёт большего экрана (всё-таки 4.7 дюйма). Вот он, наш герой: Хотя он сделан весь из пластика, выглядит строго и достойно. Более того, за свои 200 долларов под капотом имеется весьма достойное железо, а именно:
 Покупалось это чудо на Ebay вот тут за 209 долларов вместе с доставкой.  В комплект добрые китайцы положили, помимо телефона, наушники, USB-кабель, зарядник, плёнку для экрана и аж целых две (2!) могучие 2000 mAh батарейки. Да, так же в комплекте замечена инструкция для простых китайских колхозников на таком простом и понятном китайском же языке:  Смартфон долетел из Гонк-Конга в Австралию за 8 дней в целости и сохранности:  и далее начал радовать автора этих строк неимоверно, о чём ниже. Внешний вид, комплект и сборка THL W5На фотографиях THL W5 выглядит очень прилично, но каков он в жизни? А в жизни он выглядит не менее достойно: несмотря на полностью пластиковый корпус, выглядит строго, собран хорошо и в широкой руке автора лежит отлично. Задняя крышка сделана из мягкого и "шелковистого" на ощупь пластика, скрывая под собой здоровенный Собственно, кнопок и штекеров минимум: вкл\выкл, стандартное гнездо наушников на 3.5", кнопка громкости, microUSB, камера сзади (с дистрофичной подсветкой) дырка для микрофона снизу. КрышкаКрышка держится на десятке небольших защёлок, которые легко поддаются при применении небольшой, но грубой физической силы. Тут вылезает первый небольшой недостаток: microSD карта расположена так, что без изъятия аккумулятора её не достать. Не то, чтобы это часто требовалось, но тем не менее. Крышка после закрытия плотно прилегает к корпусу, и единственное, что её выдаёт - небольшая выемка в нижней части корпуса, которая позволяет эту самую крышку найти и открыть. Скрипов и люфтов не замечено, смартфон радует на удивление качественной сборкой. Кнопка включения - в верхней части, в центре. Если обхватить смартфон и положить указательный палец на верхнюю часть, он точно приземлится на кнопку включения. Чуть левее притаился Audio Jack 3.5" выход на наушники.  НаушникиДа, наушники идут в комплекте, но, признаться, лучше бы не шли. На china-review пишут, что эти затычки а-ля "наушники вакуумного типа с довольно хорошим качеством звука" - с чем автор этих строк категорически не согласен. Такого кошмара я не слышал уже давно: звук как из бочки, басы отсутствуют как класс, высоких частот нет в принципе. Конечно, "Владимирский централ" в них слушать можно, но, скажем, Боккерини и Моцарта, к которым тяготеет автор, лучше даже не пробовать. Для сравнения, оставшиеся наушники от HTC по сравнению с THLевскими звучат как Hi-End студийная запись. Но за 200 баксов это можно и простить, благо разъём стандартный и можно воткнуть всё, что угодно. Железо: что под капотом у THL W5Как отмечалось выше, под капотом у THL W5 весьма приличное железо, особенно учитывая его цену. Двухядерный процессор, много памяти, приличный WiFi чип и огромный яркий экран - обо всём этом чуть подробнее далее.БатарейкаЦелых два могучих 2000 mA*h кирпичика в комплекте, которые призваны поддерживать жизнь огромного 4.7" яркого экрана, двухядрёного процессора и что-то вечно энергично качающего WiFi чипа. На тему энергопотребления и времени работы, как всегда, мнения несколько разнятся. Официальных данных на сайте THL нет, но есть восторженные комментарии пользователей под описанием смартфона (которые всегда выставляют 5 звёзд): The battery life is great. It gets me all the way through the day without having to plug in and that's with very heavy usage - I've been an Android user for years and I've never had a phone that will do that...или: The battery exceeds my expectations, getting through a full day is no problem for me using web, email, text, google talk, streaming music via BT, checking weather, reading Kindle, you name it. Average 12 hours or so battery for me with 20% or so remaining at the time I plug it in at night.То, что это опубликовано на официальном сайте, это, конечно, лучше чем ничего, но отсутствие цифр от производителя несколько смущает. Охочим до цифр и замеров - их есть у нас:
Две SIM-карты - Про и КонтраСмартфон, как и полагается по древней китайской традиции, имеет две SIM-карты (Dual SIM) и, естественно, не залочен на мерзких капиталистических операторов связи.Как уже говорилось, у смартфона - две SIM-карты под стандартные SIM (полноразмерные). Здесь нужно ещё немного попенять узкоглазым: места для двух симок очень мало, и слоты очень тугие. Вставка SIM-карты, особенно нижней, это то ещё развлечение - автору этих строк, при всей его инженерной подготовке, потребовалось добрых полчаса, чтобы просунуть обе SIM-карты. Лирическое отступление. Разного рода проприетарщики обожают изобретать новые несовместимые стандарты, на радость простым пользователям. Нынче появилась тенденция делать не нормальные SIM-карты, которые были ещё до изобретения огня, колеса и электричества, а micro-SIM.  Но Apple не была бы Apple, если бы не выпендрилась со своим форматом NanoSIM. В ихний iPhone 5, видите ли, microSIM не влезают, и давайте уже сделаем новый формат.Вопреки расхожему мнению о том, что Dual SIM потребляет много энергии, автор не заметил ощутимой разницы между включением двух сим-карт (в комментариях сообщают, что в смартфоне один радиомодуль), одной или Airplane mode: главные потребители батарейки, как и всегда, это экран и WiFi. Занятно, но вот тут говорят, что в таких Dual SIM смартфонах - два разных GSM-приёмника, которые работают одновременно, мониторя состояние сигнала двух сим-карт. Знающие всё на свете авторитетные Анонимусы приглашаются это прокомментировать.  В нашей австралийской глухомани это важно: покрытие сотовой связи неравномерно, и можно пользоваться услугами того оператора, который лучше представлен в данной местности и\или дешевле. IPS Экран 4.7 дюймаОн прекрасен - яркий и большой, хорошо смотрится даже в солнечную погоду и под большими углами обзора. При своей внушительной диагонали он вытянут чуть больше, чем HTC Desire HD - то есть он такой же широкий, только длиннее. Отлично смотрится на солнце и не слепнет. Экран очень чёткий - ну ещё бы, 10 точек на миллиметр - и довольно яркий (хотя не глазовыжигающий, как самсунг). Радуют большие углы обзора и цветопередача.  Здесь следует отметить один момент: на экране видна сетка тачскрина, хотя видна она только на ярких участках изображения. На HTC Desire HD её заметно не было, а здесь её видно. Запишем в недостатки, а то кто-нибудь подумает, что THL заплатила мне мильён юаней за обзор :-) Забавный момент с регулятором яркости: шагов яркости не так много, и даже на 1%, выведенный с помощью Elixir2, это не похоже. В темноте читать не очень удобно, хотя я нашёл ScreenDim Full, который решает эту проблему (утилита стоит целых 99 центов). WiFi, GPS, Bluetooth...и прочий беспроводный ливер вполне достойные: wifi цепляется к домашнему и университетскому роутеру, GPS выдаёт координаты, Bluethooth кидает файлы на планшет и десктоп. Дабы проверить WiFi, автор этих строк, естественно, пошёл на свой бложик: WiFi чип очень охоч до батарейки, и расположен, судя по нагреву во время работы, недалеко от камеры - в верхней части смартфона. Батарею ест от души, хотя WiFi на моём старом HTC более чувстсвительный, и ловит сильно удалённые WiFi точки, которых THL не видит. В остальном WiFi работает без вопросов и проблем. GPS работает без проблем, хотя холодный старт занимает ощутимо больше времени, чем на HTC Desire HD. Тем не менее, отлично работает в паре с GPStest и Osmand. Камера и подсветкаКамер две, фронтальная и задняя, и обе выдают пристойного качества снимки.Фронтальная камера на 2 мегапикселя для видеозвонков - выдаёт немного засвеченную картинку, хотя вполне приличную. Задняя камера на 8 мегапикселей тоже радует приличными картинками:  Приличные для телефонной камеры снимки, неплохая цветопередача. Снимает на удивление быстро, и так же шустро работает автофокус. Подсветка... имеет место быть, и это уже радует. Я не знаю, о чём думали в THL, когда ставили эту пародию на LED-подсветку. Картинка стоит тысячи слов: слева HTC Desire HD, справа THL 5W.  В общем, во мгле ада это лучше, чем вообще ничего, но, как бы это помягче, недостаточно для повседневных нужд. Пожалуй, это самый большой недостаток THL W5, но за 200 баксов чего только не простишь. Выводы по железуЗа 200 долларов железо в смартфоне очень достойное: быстрый двухядерный процессор, много (1 Гб) памяти, Dual SIM, могучая батарейка, яркий и качественный экран, достойная камера и долгое время работы (HTC Desire HD в этом плане тихо покуривает в сторонке). Из недостатков стоит отметить дистрофичную подсветку и нагревающийся при работе WiFi.Софт: Андроид "Мороженый бутерброд" и как сделать его съедобнымНа THL W5 залит Android 4.0.4 ICS с минимумом софта и который при первом включении выглядит вот так: То есть часы, иконки внизу, аутентичные китайские обои и неубираемая строка поиска от Google. Если общую убогость тем и изкоробочный вид Андроида ещё можно терпеть, то надоедливую строку гуглопоиска, отнимающую целый ряд иконок, терпеть решительно невозможно. Go Launcher EXПоэтому было решено установить GO Launcher EX в качестве штатной оболочки. Небольшой напилинг, красноглазинг и подбор тем - и вот что из всего этого получилось в итоге: Тема Stained Glass, виджет для часов пришлось искать отдельно. По сравнению со стоковым убожеством выглядит отлично и, что самое приятное, конфигурировать можно до посинения.Есть много красивых тем, в том числе платных. На скриншотах выбрана тема Stained Glass (бесплатная). Три скриншота отражают установленные приложения, конфигурацию виджетов Elixir2 и календарик от Go:  Из специфичного софта отмечу Andie Graph (эмулятор TI калькуляторов - мечта любого инженера), G Cloud для переноса настроек и AirDroid для связи со смартфоном по WiFi. SIM Card managementЭто ещё одно специфичное отличие от большинства смартфонов - управление двумя SIM-картами. Выше в разделе про железо уже говорилось, что с THL W5 можно посылать и принимать SMS на оба номера одновременно, при этом в сообщениях они будут отображаться все вместе.Можно выключать и включать SIM-карты в настройках:  назначив каждой цвет для удобства:  Если же вы захотите отправить SMS-сообщение, то в стандартном виджете можно выбрать, с помощью какого оператора сообщение будет отправлено:  Так что теперь можно рассылать и принимать сообщения с обеих SIM-карт одновременно. Выводы по софтуПосле HTC Sense и привычного Android 2.3, новый Android 4.0.3 Ice Cream Sandwich выглядит убого и минималистично, с неубираемой строкой поиска вверху, которая отнимает место, и урезанными настройками. К счастью, в отличие от Apple, на андроиде оставлено большое поле для настройки под себя, и сторонняя оболочка GO Launcher EX исправляет положение. В остальном всё как прежде: перенос настроек, уже купленные приложения из Play Store ставятся на новый аппарат, и вот он уже радует нас всеми возможными и невозможными приложениям.ЗаключениеСмартфон THL W5, несмотря на своё безродно-китайское происхождение, более чем стоит своих денег, имея мощное железо, отличный экран и кастомизируемый современный Андроид на борту.Из недостатков можно назвать чахлую подсветку (неизлечимо), небольшой диапазон регулировки яркости экрана (лечится сторонним приложением), несколько заторможенным GPS приёмником и видимой сеткой тачскрина на экране. Плюсы-таки перевешивают: замечательный большой экран, мощный процессор, море памяти, две батареи, двуxядерный процессор, отличное качество сборки и андроид, не захламлённый предустановленным мусором. Так держать, THL! СсылкиЕсть хороший обзор на украинском сайте china-review, откуда автор позаимствовал немного картинок. Краткий обзор на английском здесь. | |||||||||||||||||||||||||||




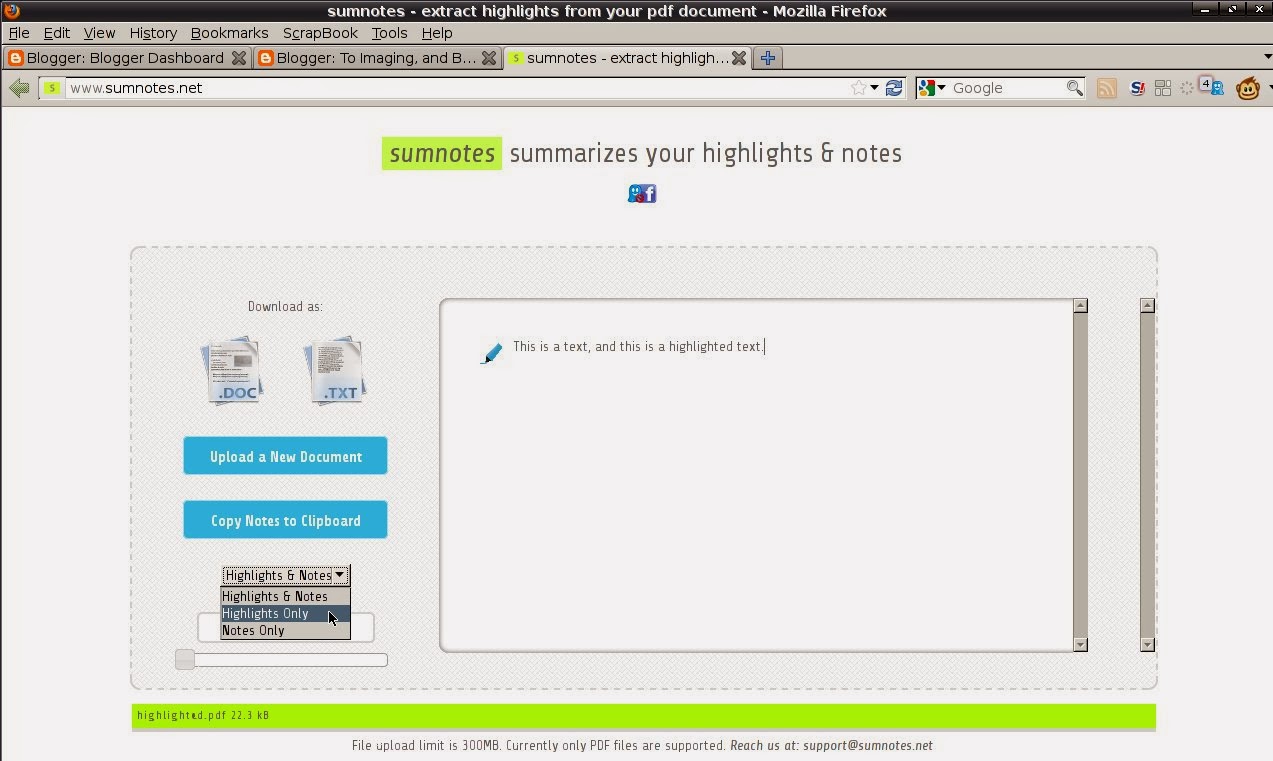
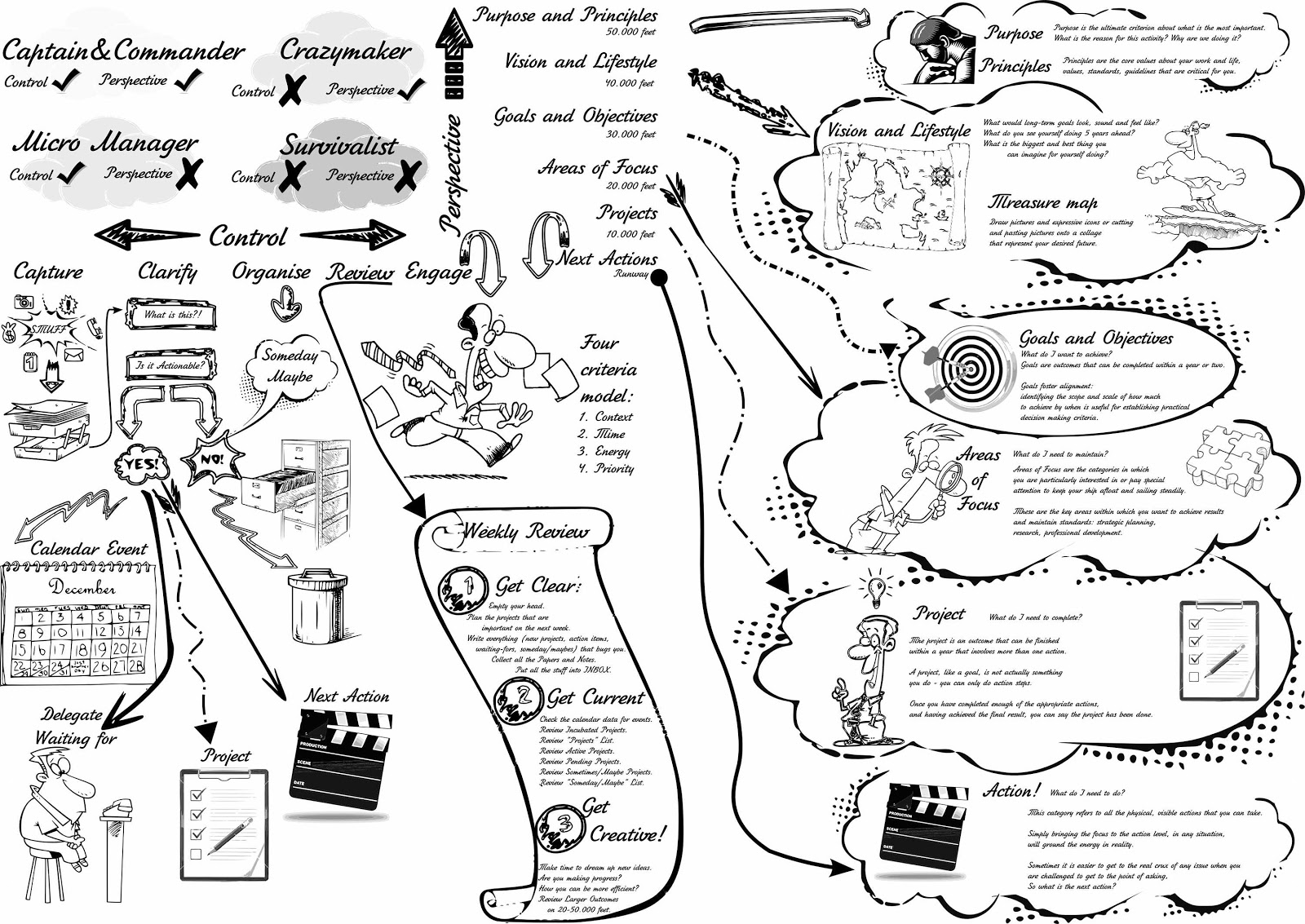










{kind=link}
{kind=link}
LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose.