Записки дебианщика
The following are the titles of recent articles syndicated from Записки дебианщика
Add this feed to your friends list for news aggregation, or view this feed's syndication information.
LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose.
| Monday, March 18th, 2013 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 1:01 am | Закрытие Google Reader: альтернативы и что теперь делать  Альтернативы Google ReaderЗакрытие Google Reader это, конечно, очень грустно, но свято место пусто не бывает, и свои RSS-фиды можно экспортировать в OPML и загрузить куда-нибудь ещё. Автор потратил это утро на пляски с бубном вокруг вебдваноля и решил выложить итоги.Надо сказать, что небо от решения Google прикрыть Reader не упало на землю, хотя точно добавило геморроя пользователям. Хорошие новости: Google Reader может экспортировать все ваши RSS-подписки через OPML (генерирует XML-файл), который может быть загружен на аналогичные [netvibes.com] сервисы [newsblur.com] чтения RSS [feedly.com]. Мы имеем следующие альтернативные бесплатные веб-сервисы:
Для настоящих мужиков, которые всё любят делать сами, есть:
Забираем RSS-подписку из Google ReaderСначала мы забираем свои фиды из Google Reader. Это можно сделать с помощью Google Takeout:
Переход из Google Reader на NetvibesТеперь, когда XML-файл с RSS-подписками в наших руках, мы можем загнать его в другие сервисы. Netvibes предлагает сходный интерфейс: Теперь для импорта своих RSS-фидов делаем следующее::
 Другой режим, Reader, больше похож на Google Reader, где каталоги с фидами слева, а сами посты - справа в виде строчек:  Просто, функционально и со вкусом. Мобильный интерфейсНемного дёгтя в бочку с мёдом: нативного приложения для iOS или Android у Netvibes просто нет. Зато есть специализированные веб-сайты, заточенный под мобильные устройства:Заходим на эти сайты, в зависимости от вашего смартфона, через броузер в смартфоне\планшете, и читаем. Выглядит неплохо:  Соответственно, количество непрочитанных постов показывается слева в виде чисел. Интерфейс выглядит несколько спартански, но тем не менее весьма функционально. Переход из Google Reader на FeedlyFeedly это расширение для броузеров (для Chrome, Chromium и Firefox) и приложение для Android и iOS, которые тягают Google Reader. В будущем, когда Google Reader закроют, они обещают простой переход на их собственные мощности:When Google Reader shuts down, feedly will seamlessly transition to the Normandy back end. So if you are a Google Reader user and using feedly, you are covered: the transition will be seamless.Так как Feedly представляет собой плагин для Firefox (и не только), то установка сравнительно проста:
У Feedly есть много настроек, и по умолчанию Feedlу попробует сделать из ваших фидов некое подобие журнала:  У автора этих строк при взгляде на этот праздник жизни начался приступ морской болезни от передозировки вебдваноля :-) Особенно учитывая Featured заголовок (это, кстати, реальная газета - Northen Territory News). Хорошо, что режимов просмотра у Feedly несколько: режим Latest более походит на Google Reader:  В настройках можно сделать этот режим по умолчанию. Мобильный интерфейсПриложения для iOS и Android у Feedly есть, хотя... В общем, то приложение для Android, которое я тестировал на своём смартфоне, работает, скажем мягко, не слишком впечатляюще. Вот как выглядит режим Latest на смартфоне: При том, что диагональ экрана 4.7", умещается всего шесть постов. Интерфейс Greader для смартфонов намного более продуман, хотя о вкусах не спорят. Настройки Feedly в смартфонной версии открываются при прокрутке вправо:  Хотя Android-приложение ещё очень сырое и медленное, пользоваться им можно, после некоторого привыкания к интерфейсу. Чтение RSS-фидов на смартфонеЗдесь стоит отметить очень простую и бесплатную, но тем не менее пригодную для пользования программу Sparse RSS. Спартанский интерфейс, минимализм, граничащий с мазохизмом, и поддержка загрузки через OPML с карты памяти - вот, собственно, и всё: То есть загружаем XML-файл со своими RSS-фидами на карту памяти и импортируем это в Sparse RSS. Просмотр только в текстовом виде - собственно, опенсорц как он есть. Альтернатива - Android-приложение gReader, которое выглядит куда более фукнциаонально:  Здесь есть полноценный просмотр и синхронизация фидов, и RSS-фиды можно читать в том числе offline:  Разработчики намекают, что Android-приложение gReader будет работать и после закрытия google reader: gReader will work after the closure. We are working on a solution.А пока можно пользоваться и искать другие альтернативы. Чтение RSS-фидов на Linux-десктопеДля десктопа есть отдельные приложения, которые позволяют читать RSS-ленты, импортируя подписки через OPML. Выглядит достойно: Занимая немногим больше 5 Мегабайт и присутствуя в репозиториях любого уважающего себя дистрибутива, Liferea умеет работать как самостоятельно, так и в связке с Google Reader и Tiny Tine RSS. Можно скачать отсюда и собрать самому. Вместо заключенияЭта краткая заметка ни в коем случае не есть исчерпывающий обзор, а просто делёж опытом по поиску сколько-нибудь вменяемых альтернатив Google Reader. Желающие поделиться своими находками, всячески приветствуются в комментариях.Ещё можно подписать петицию | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Sunday, March 3rd, 2013 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 9:02 pm | ЛаТеХ для продвинутых: Как контролировать положение плавающих объектов "floats"? О плавающих объектах (например, картинках) в ЛаТеХе написано много книжек, статей, блогов, заметок, и т.д. Тем не менее вопросы вроде: "Почему я поставил там [!h], а ЛаТеХ всё равно засунул картинку на последнюю страницу?", — наверняка войдут в горячую десятку любого ЛаТеХ-форума. Причина этого проста: механизм размещения плавающих объектов (floats) довольно сложен и отнюдь неинтуитивен. Его описания же в основном рассчитаны на докторов физ-мат наук, решивших посвятить остаток своей жизни разборкам с ЛаТеХом. В этом посте я попытаюсь коротко осветить вопрос о том, как можно контролировать расположение плавающих объектов (в качестве примера будут использованны рисунки "figure", но все написанное применимо и к другим floats, например, table). Большая часть поста состоит из рецептов и примеров, исходники которых лежат здесь. Тем не менее, начать придется с небольшого кусочка теории. Итак, ... Немного теории или "почему ЛаТеХ не делает то, что я хочу?"Никто не сможет объяснить, как ЛаТеХ помещает флоатс (floats), точнее и лучше, чем сам Франк Миттельбах. Однако поскольку сделал он это на вражеском языке, мы позволим себе здесь повторить коротко его разъяснения.Когда ЛаТеХ натыкается на плавающий объект в tex-файле, он пытается его немедленно разместить на странице. Страница для ЛаТеХа состоит из двух частей: верхней и нижней. Кроме того, флоат можно поместить "прямо здесь". Да-да, вы уже поняли, что речь пойдёт об этих загадочных буковках "h", "t" и "b" в \begin{figure}[htb].
ЛаТеХ делает следующее:
[hbt] и
[tbh] возымеют абсолютно одинаковый
эффект! Если аргументы не указаны, то по умолчанию предполагается
[tbp].
Можно или нельзя поместить плавающий объект
на текущей странице вверху (или внизу,...)
определяется исходя из двух критериев:
! означает,
что эти два правила будут проигнорированны.
Если не предполагается полностью игнорировать все эти правила, то можно изменить значения параметров. Например, может пригодиться, если в документе много невысоких картинок. А разрешит ЛаТеХу поместить высокую картинку на странице со всего парой строк текста. Помимо вышеупомянутых параметров, при размещении плавающих объектов используются длины
чтобы всунуть больше плавающих объектов на одну страницу. Каковы последствия алгоритма? Прежде всего, [!h]
означает вовсе не
"здесь и только здесь", а "здесь, если оно поместится". Точно также, как
[!htpb] и
[pb!th] означают абсолютно одно и то же.
То есть порядок символов, в том числе и вослицательного знака,
никакой роли не играет.
Всё, выдыхаем... Дальше пойдут рецепты. Здесь, здесь, здесь и только здесь.Об этом уже писал в блоге virens, но повторюсь: параметр[H] всунет плавающий объект именно там,
где он встречается в tex-файле. Если флоат не помещается, то
будет начата новая страница, оставив, как результат,
пустое место на предыдыщей.
Не стоит использовать этот параметер без особой надобности. Ну, и не
забудьте сначала сказать \usepackage{float}.
A вам нужны эти флоатс?Вообще говоря, если вы хотите поместить картинку и её подпись "прямо здесь", то вовсе необязательно использовать плавающий объект. Команда\captionof{}{}
из замечательного пакета
caption
позволяет снабдить подписью что угодно. Например, вот такой код
вставит картинку и снабдит её подписью. Первый аргумент — тип плавающего объекта, в данном случае, figure, но с
таким же успехом могло бы быть table,
wrapfigure и т.п.
Пример использования
"А для чего оно нужно?", — спросишь ты, привередливый читатель. А,
например, для вот такого:
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Sunday, February 17th, 2013 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 6:01 pm | Вглубь синтетических джунглей файловой системы sysfs в Linux Файловая система /sys в Linux отличается от /proc тем, что предоставляет детализированную информацию о работе ядра пользователю (например, параметры устройств и загруженных модулей). Информация строго организована и обычно форматируются простом ASCII тексте, что делает её очень доступной для пользователей и приложений. Так что можно занять шаловливые ручонки чем-нибудь полезным, вроде дёргания разных крутилок в /sys и подсматриванием в системные переменные. Далее - немного подробностей о синтетических джунглях файловой системы /sys. Зачем нужна /sys, когда есть /proc? Основной лейтмотив создания /sys было навести некоторый порядок в том бардаке, который являет из себя /proc и выделить информацию о структурах ядра в отдельную директорию. Sysfs это файловая система, находящаяся в памяти (in-memory), основана первоначально на Ramfs, которая в свою очередь была написана во время перехода на ядро 2.4.0. Как говорит один из авторов [1], ``это было упражнение в элегантности, имевшее целью показать, насколько легко написать простую файловую систему, если использовать новый на тот момент слой VFS''. Из-за простоты и использования VFS, это дало здоровую основу для создания других in-memory файловых систем. При этом sysfs может быть смонтирована, как и любая другая файловая система из пространства пользователя. Большинство дистрибутивов делают это автоматически при старте системы, добавляя соотвутствующую строчку в /etc/fstab. Что внутри /sys? Sysfs является каналом распространения информации между ядром и пространством пользователя. Например, есть возможность смены планировщика ввода/вывода или изменения параметров Udev программы. В каталоге /sys находится несколько подкаталогов, представляющих ряд основных подсистем, которые зарегистрированы в Sysfs: /sys/ Внутри /sys/block Каталог /sys/block содержит подкаталоги для каждого блочного устройства, которое было обнаружено в системе. Там хранятся параметры, которые описывают такие свойства блочных устройств, как размер устройства, его партиции, планировщик ввода-вывода и другие. Зайдя туда, мы обнаруживаем кучу блочных устройств, среди которых можно найти рабочий винчестер, подключённые флешки и внешние жёсткие диски. Вот что автор этих строк нашёл про свой жёсткий диск, на котором установлен евонный Дебиан: notebeast:/sys/block/hda# ls -lОтсюда мы узнаём, например, что диск /dev/hda разбит на две партиции, hda1 и hda2, размеры которых хранятся в size, что можно достучаться до планировщика I/O в queue и собрать немножко статистики по работе жёсткого диска в stat. Заглянем туда в поисках приключений и чего-нибудь неизведанного. Статистика ввода-вывода Интерфейс /sys/block/sdX/stat даёт некоторые статистические данные о производительности ввода-вывода ядра. Эти данные пользователь или администратор может использовать для оптимизации производительности, если знает, что они значат. Например, если дать команду: # cat /sys/block/sda/statМы увидим что-то типа: 186908 41568 6033917 2408504 91198 509600 4882200 9406764 0 1161304 11848624 Эти сакрально-литургические знаки означают следующее: Поле 1 -- полное число запросов на чтение, выполненных успешно. Поле 2 -- число объединённых запросов на чтение. Запросы на чтение и запись, примыкающие друг к другу, могут быть объединены для повышения эффективности. Таким образом, два 4K считывания может стать одним 8K считыванием перед тем, как в конечном итоге быть переданы диску. Поэтому запрос будет считаться одним, и это поле позволяет вам узнать, как часто это было сделано. Поле 3 -- число считанных секторов, чтение которых прошло успешно. Поле 4 -- миллисекунд, потраченных на чтение. Поле 5 -- число запросов на запись, выполенных успешно. Поле 6 -- число объединённых запросов на запись. Запросы на чтение и запись, примыкающие друг к другу, могут быть объединены для повышения эффективности. Таким образом, два 4K считывания может стать одним 8K считыванием перед тем, как в конечном итоге быть переданы диску. Поэтому запрос будет считаться одним, и это поле позволяет вам узнать, как часто это было сделано. Поле 7 -- число секторов, записанных успешно. Поле 8 -- миллисекунды, потраченные на запись. Поле 9 -- число запросов ввода-вывода, активных в данный момент. Единственное поле, которое должно стремиться к нулю. Поле 10 -- миллисекунд, потраченных на выполнение запросов ввода-вывода. Поле 11 -- взвешенное количество миллисекунд, потраченных на ввод-вывод. Может использоваться как простая мера производительности ввода-вывода. Смена планировщика ввода-вывода на лету Как нам намекает документация, планировщик ввода-вывода может быть изменён в любое время на лету, хотя может быть небольшая задержка из-за того, что все запросы предыдущего планировщика должны быть обработаны прежде, чем запустится новый. Чтобы узнать, какой планировщик стоит сейчас, даём команду: cat /sys/block/sdX/queue/scheduler
Заменяя sdX на интересующее нас устройство. Текущий планировщик отмечен в квадратных скобках:
noop anticipatory deadline [cfq]То есть сейчас стоит cfq - Completely Fair Queuing, полностью честный планировщик. Планировщики для разных дисков могут быть:
Сменить планировщик можно на лету: # echo "deadline" > /sys/block/sda/queue/schedulerПосле этого планировщик для данного диска будет изменён. И другие каталоги... Содержимое других каталогов будет интереснее разработчикам, а не пользователям, и может сильно меняться от версии ядра Linux. /sys/bus Это структура шин данных в системе, которая показывает, какая шина куда подключена (например, контроллер USB может быть подключен к шине PCI), и какие устройства в каждой шине потенциально может поддерживать (наряду с соответствующими драйверами), и какие устройства существуют. Здесь есть символической ссылки, которые указывают на директории устройства в глобальном дереве устройств. Каждый тип шины данных представлен двумя подкаталогами: устройств и драйверов. /sys/class Хранит все классы устройств, зарегистрированные ядром. Используется для описания функционального типа устройств. Большинство подкаталогов содержат символические ссылки на каталоги device и driver. Например, физическое устройство типа мышь может ссылаться на объект ядра "мышь", на устройство input event и input debug. Классы могут включать в себя диски, разделы, последовательные порты, и т.д. /sys/devices Содержит глобальную иерархию устройств: каждое физическое устройство, которые было обнаружено и зарегистрировано ядром. Например, автор этих строк нашёл: /sys/devices/virtual/thermal/thermal_zonпоказания температуры на процессоре в ноутбуке. Исключений два - platform devices и system devices. Platform devices это периферия (подключаемые устройства), присущие конкретной платформе (порты ввода-вывода, legacy-устройства типа последовательного контроллера или контроллера дискет [floppy controller]). System devices это устройства, интергрированные в платформу, например аппаратные регистры для доступа к конфигурированию, которые не имеют возможностей обмениваться данными. Обычно для них нет драйверов (процессор, таймеры и другое). /sys/firmware Cодержит интерфейсы для просмотра и манипулирования firmware-специфичными объектами и их параметрами. Как правило, это платформо-зависимый код, который выполняется в системе при включении, например BIOS. /sys/module Cодержит подкаталоги для каждого загруженного модуля ядра. Имя каталога отражает имя модуля. Ядро имеет глобальное пространство имён для всех модулей. Подкаталоги содержат параметры, специфичные для каждого загруженного модуля. Эта информация используется для отладки и простым смертным не будет интересна. /sys/power Это скорее заделка на будущее. Может содержать название состояния, которое позволит процессу переходить в режим пониженного энергопотребления. Ссылки Есть любопытный документец [1] The sysfs Filesystem, OLS'05 на 14 страниц, написанная тем водянистым и пустозвонным стилем, коий так не переваривает автор этих строк. Документация к ядру тоже не особенно жаждет подробно рассказать о том, что означают все эти переменные и отгораживается вот этим: TODO: Finish this section.Понятно, что это самое туду не входит в приоритетный список дел. Но кое-что выудить всё-таки можно. Надеюсь, что этот пост несколько приподымет завесу тайны с файловой системы /sys. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Sunday, February 3rd, 2013 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 6:00 pm | Обзор редакторов для работы в ЛаТеХ: LaTeX Editors and Integrated LaTeX Environments Частый вопрос начинающих латехников: ну вот установили мы LaTeX, а как теперь со всем этим работать? Вопрос задают сравнительно часто, и подумалось мне, что неплохо бы всё это оформить в виде одного поста со скриншотами и сравнениями. Описание сред для работы с LaTeX идёт в порядке убывания возможностей программ.Так как пост сравнительно длинный, ниже приводится список редакторов LaTeX по операционным системам. Только для LinuxТолько для WindowsТолько для MacOS Только для настоящих мужЫковЕсли вы презираете графические интерфейсы, любите исследовать и программировать свой текстовый редактор, заваривать в нём кофе, и вообще следуете Unix-Way по поводу и без, вам скорее всего уже давно известно, что LaTeX документы можно редактировать в Vim (через vim-latex) и Emacs (через AUCTeX) без проблем, так что дальше можно не читать. То есть основных опций для настоящих мучачос две:
Мультиплатформенные (Windows/Linux/Mac)Kile
Основные возможности Kile
Как выглядит Kile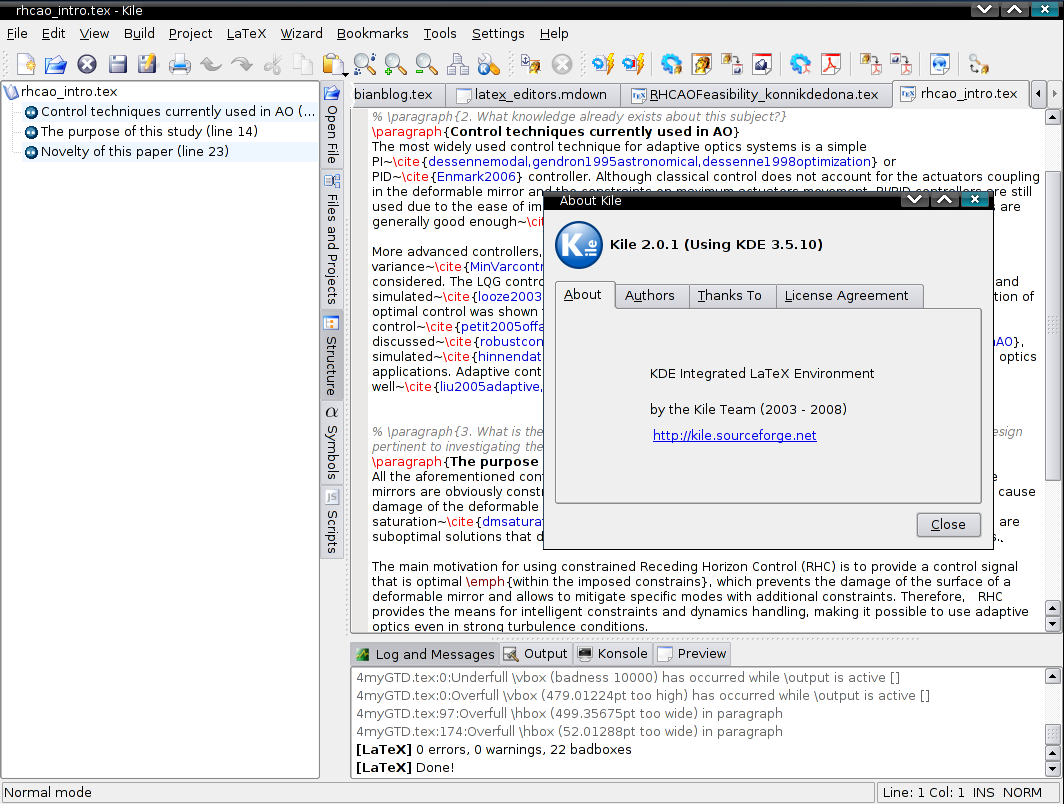 TeXstudio
Основные возможности TeXstudio
Как выглядит TeXstudio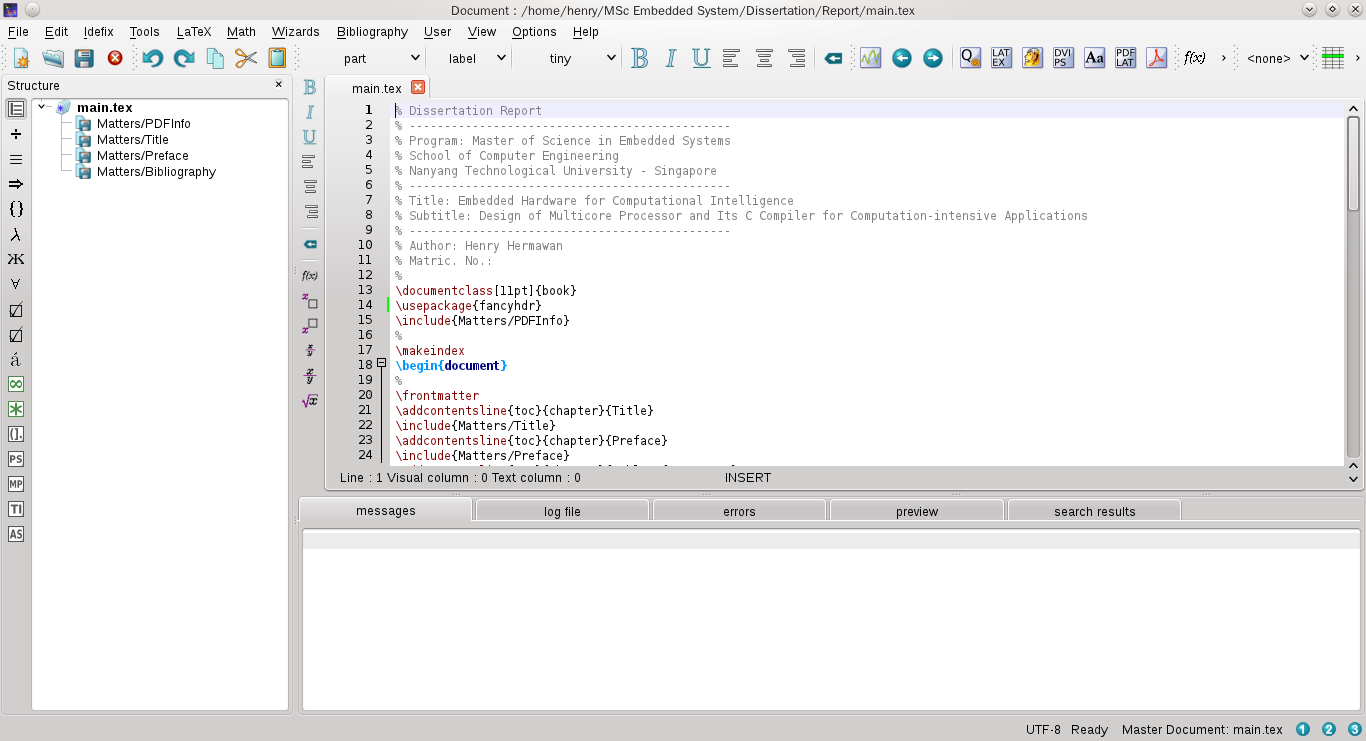 TeXworks
Основные возможности TeXworks
 Годится для пользователей, предпочитающих простоту обилию возможностей. TeXworks не поддерживает настройку раскраски синтаксиса и вообще беден возможностями на фоне конкурентов. Как выглядит TeXworks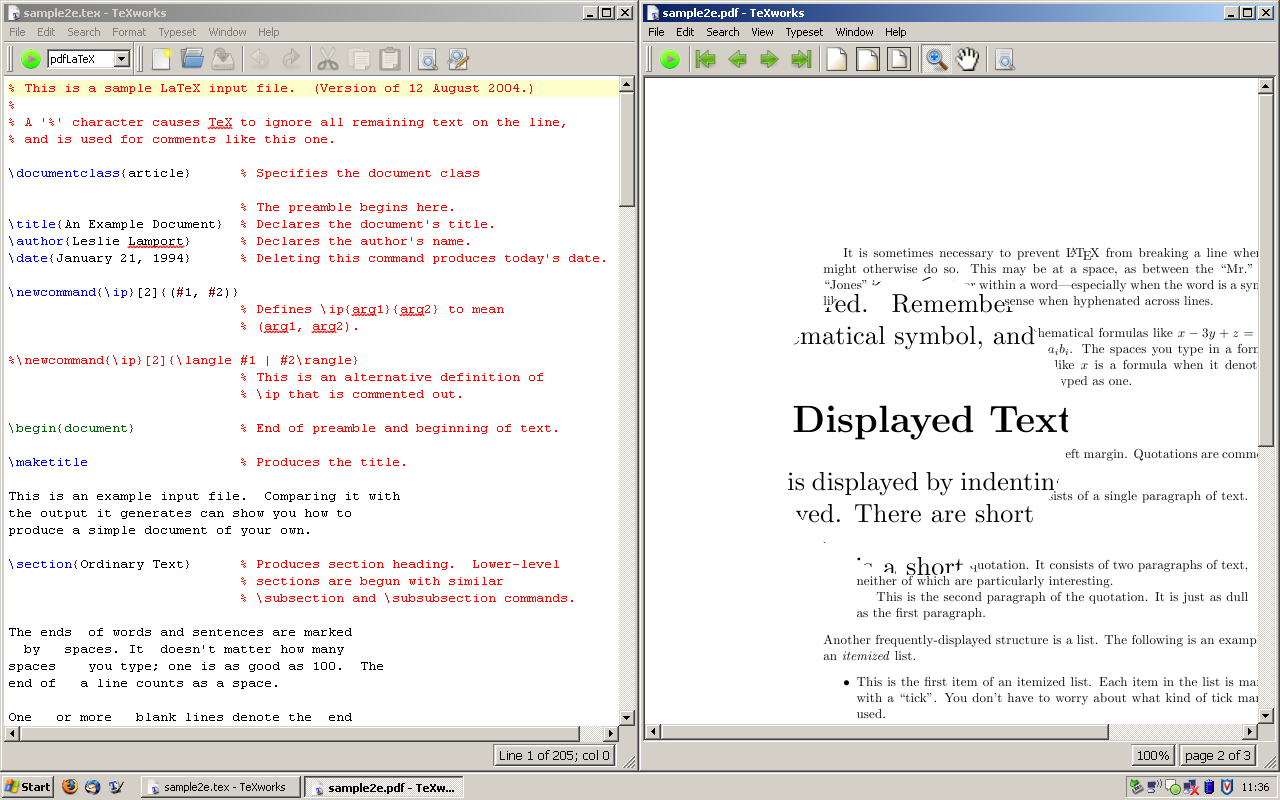 Texmaker
Основные возможности Texmaker
Как выглядит Texmaker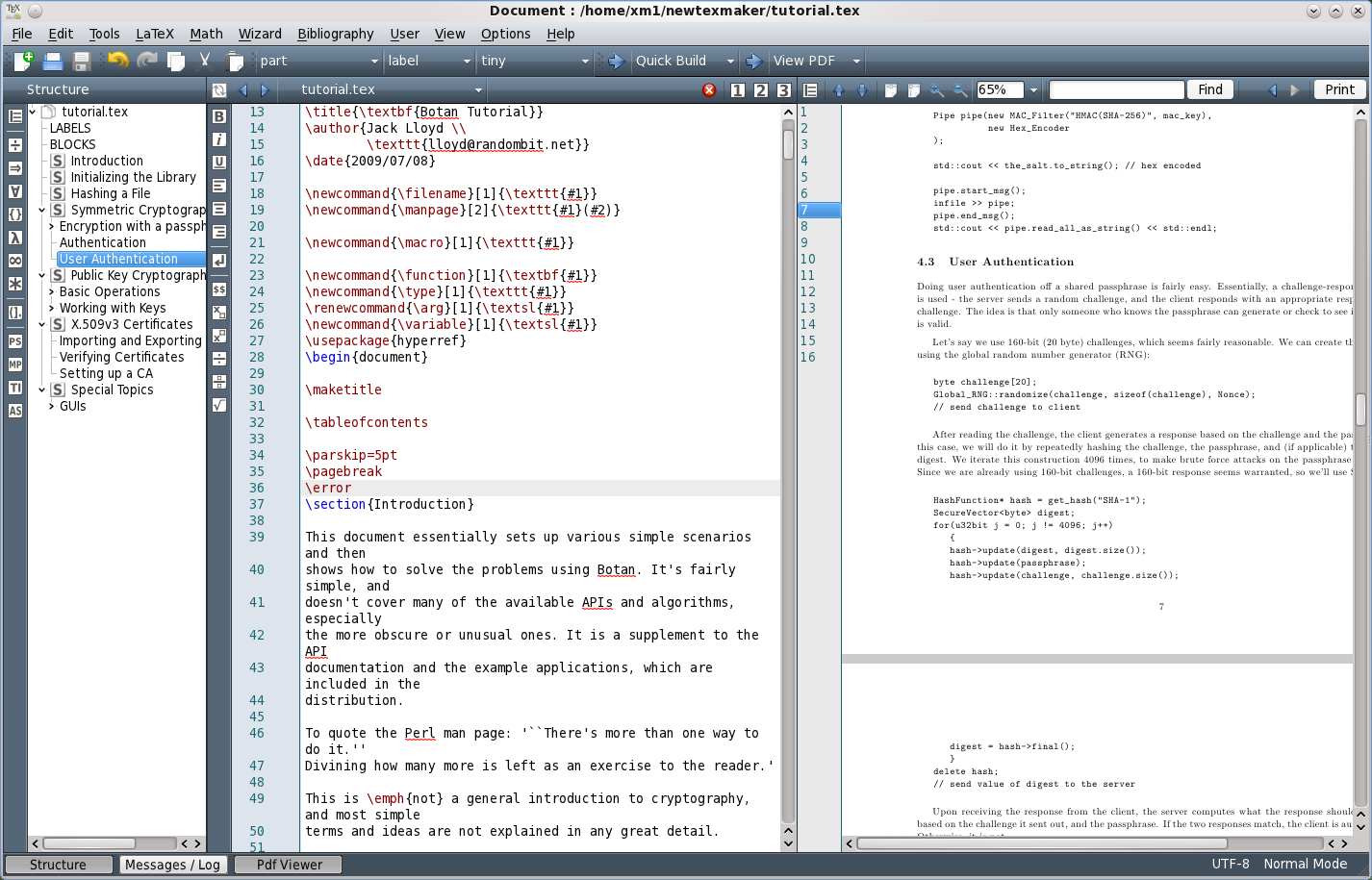 TexShop
Основные возможности TexShop
Как выглядит TexShop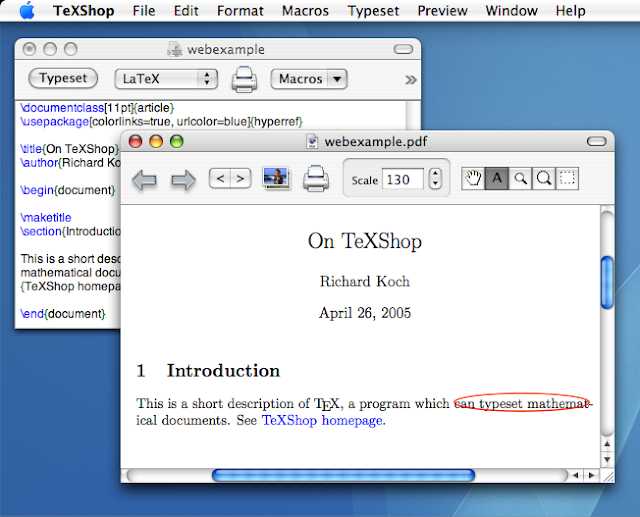 TeXnicCenter
Основные возможности TeXnicCenter
Как выглядит TeXnicCenter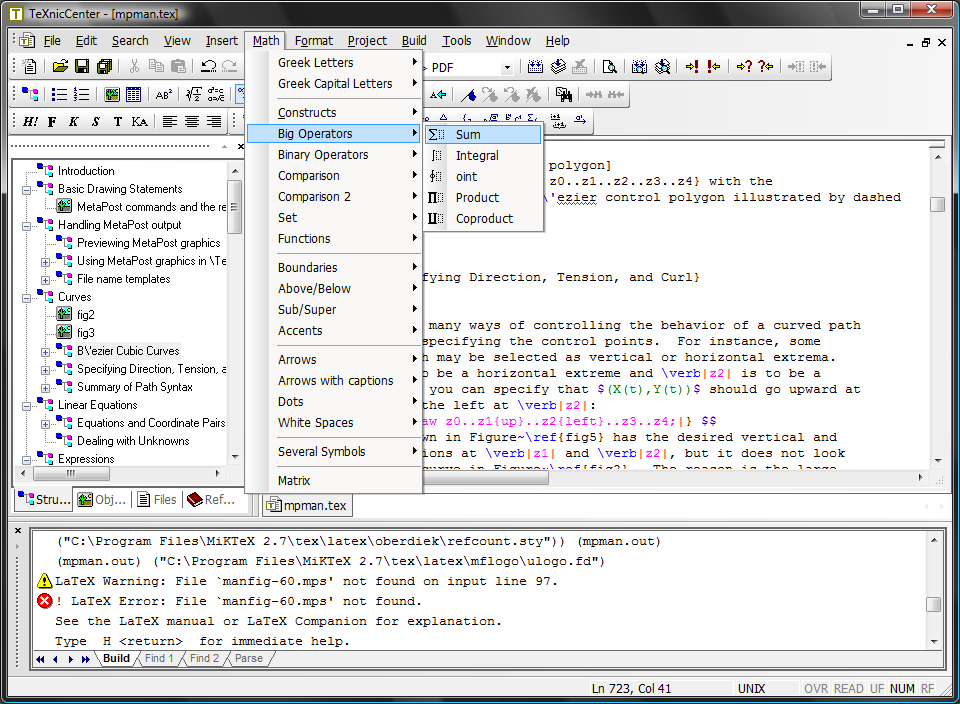 WinEdt
Основные возможности
Как выглядит WinEdt LyX
Основные возможности LyX
Как выглядит LyX TeXlipse
Основные возможности TeXlipse
Как выглядит TeXlipse TextMate
Основные возможности TextMate
Как выглядит TextMate Gummi
Основные возможности Gummi
Как выглядит Gummi Emacs вместе с AUCTeX
Основные возможности Emacs
Как выглядит Emacs | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Sunday, January 20th, 2013 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 6:03 pm | Xournal - рукописные заметки и пометки в PDF файлах Наличие у вас графического планшета или ноутбука с экраном, чувствительным к нажатию, открывает широкие возможности для творчества: можно рисовать картины (почти как на бумаге), создавать чертежи в CAD-программах (планшет сильно облегчит работу) или делать рукописные заметки. Заметки от руки в Linux
Я рисую на окне,
Я смотрю в пустые стены,
Оставляя на песке
Совершенные поэмы.
(С) Чайф
В вашем любимом дистрибутиве Linux есть все возможные, несколько
невозможных, и две невероятные программы, но для рукописных заметок есть
только одна - Xournal. К счастью, она умеет многое.Установка и настройка xournalУстановка проста и незатейлива - xournal входит в дистрибутивы и требует минимальных телодвижений:aptitude install xournalПосле этого запускаем xournal и приступаем к записи своих бесценных идей. Основные возможности xournalXournal довольно-таки богат возможностями и при этом имеет очень простой интерфейс: Верхний ряд кнопок стандартен: открыть файл заметок, сохранить, отмена и навигация по страницам. Удобно, что на верхней панели есть кнопки для страниц - нажатие на "Следующую страницу" автоматически создаст пустую страницу. Собственно, инструменты Pen и Eraser - всё, что нам нужно для рукописных заметок:  Среди возможностей стоит отметить поддержку чувствительности нажатия (линии будут толще или тоньше на рисунках) и задание толщины (Tools - Pen Options). Если нужно нарисовать какой-нибудь график, можно изменить линовку страницы в меню Journal - Paper Style.  Если при этом включить Shape Recognizer, то xournal будет пытаться из ваших загогулины выправить в круг или квадрат. Надо сказать, что у xournal весьма своеобразные представления о квадратуре круга и прямых линиях :-)  Своё нетленное творчество можно сохранить как в родном для xournal формате xoj (разновидность XML), так и в экспортировать в PDF. Пометки в PDF-файлах с помощью xournalПри чтении PDF-файлов часто хочется делать пометки на полях и в тексте, или выделять отдельные предложения с тем, чтобы при повторном просмотре к ним вернуться. Возможность делать пометки в PDF документах, разной степени кривоногости, имеет место быть в некоторых программах под Linux:
 В xournal так сделать не получится, потому как выделение делается с помощью простого прямоугольника (при этом стоит включить Shape Recognizer, иначе линии будут ещё и неровные):  Цвет и прозрачность выделения можно изменить: xournal, увы и ах, делает слой пометок поверх текста, так что если вы сделаете цвет полностью непрозрачным, прочитать его потом будет невозможно. СсылкиПометки и аннотации PDF-файлов по крайней мере имеют место быть в Linux в лице xournal, и это делает разного рода ноутбуки с тачскринами полезными и под Linux. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Sunday, January 6th, 2013 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 6:00 pm | Продвинутые таблицы в ЛаТеХе: advanced tables in LaTeX Набор таблиц в LaTeX, как уже говорилось, дело не простое, а набор сколько-нибудь продвинутых таблиц - скажем так, удовольствие ниже среднего. Тем не менее, ЛаТеХ позволяет тонко настраивать вид таблицы и добиваться, хотя и ценой некоторых умственных усилий, весьма навороченных результатов. Немного накопленных трюков и кульбитов описаны в этом посте.Этот пост является продолжением эпической серии о наборе диплома в латехе и конкретно темы набора таблиц. Чтобы не перегружать старый пост ещё больше, найденные трюки по работе с таблицами вынесены в новый пост, а старый - изрядно переработан. Объединение строк и столбцов в таблицах LaTeXСоздание навороченных таблиц часто требует объединять столбцы и строки, особенно при группировке сходных данных. Для этого можно использовать команды \multicolumn и \multirow, а так же некоторые другие трюки, о которых ниже.Напомню, что \multicolumn{2}{|c|}{Результаты измерений} означает, что мы объединяем 2 (два) столбца в таблице, получившаяся ячейка будет центрирована и нарисованы вертикальные линии. Таблицы с объединением столбцов в LaTeXДля того, чтобы несколько столбцов объединить в одну, можно воспользоваться командами \cline, \raisebox и \multicolumn одновременно. Здесь \multicolumn служит для объединения двух колонок в одну, \cline прочерчивает линию в строках, а \raisebox поднимает текст к середине объединённой строки.Вот код таблицы: \begin{table}[H] \caption{\label{tab:bolts} Нестандартные болты для левой резьбы.} \begin{center} \begin{tabular}{|c|c|c|} \hline & \multicolumn{2}{c|}{Диаметр} \\ \cline{2-3} \raisebox{1.5ex}[0cm][0cm]{Нестандартные болты} & Норма & Разброс \\ \hline Размеры & 10 мм & 1 мм \\ \hline \end{tabular} \end{center} \end{table} В документе это будет выглядеть так (обратите внимание на первую колонку):  Для этой таблицы использован трюк с \multicolumn для объединения двух ячеек в одну, \cline{2-3} для прочерчивания горизонтальной линии в таблице от второй колонки до третьей, и \raisebox для вставки надписи Нестандартные болты. Таблицы с объединением строк в LaTeXЕсли нужна таблица, в которой несколько строк объединены, можно использовать пакет multirow, добавив \usepackage{multirow} в преамбулу документа. Это позволит создать строки, простирающиеся на несколько колонок командой:\multirow{объединить Х строк}{ширина}{содержимое}Предыдущий пример можно переиначить вот так: \begin{table}[H] \caption{\label{tab:bolts} Нестандартные болты для левой резьбы.} \begin{center} \begin{tabular}{|c|c|c|} \hline \multirow{3}{*}{Размеры нестандартных болтов} & \multicolumn{2}{c|}{Диаметр} \\ \cline{2-3} & Норма & Разброс \\ \cline{2-3} & 10 мм & 1 мм \\ \hline \end{tabular} \end{center} \end{table} В документе такая таблица будет выглядеть так:  Объединение строк и столбцов вместе плюс использование hhlineПример с texexchange, который мне нравится, иллюстрирует применение описанных выше команд:\begin{table}[ph] \centering \begin{tabular}{c|c|c|c|c} \hline \multirow{2}{*}{Raaa (k)} & \multicolumn{4}{c}{C ()} \\ \hhline{~----} & 3.3 & 2.5 & 1 & 0.5 \\ \hline \multirow{2}{*}{Raaa (k)} & \multicolumn{2}{c|}{\multirow{2}{*}{this}} & 0.5 & 0.6\\ \hhline{~~~--} & \multicolumn{2}{c|}{} & 0.7 & 1.2 \\ \hline \end{tabular} \caption{R, C ripple size} \label{T:peak} \end{table} В документе выглядит так:  \hhline{~----}В данном случае будет нарисовано пять линий в таблице, первая будет пустая. В общем это аналог \cline{2-5}, только более удобный. Надеюсь, что с такими таблицами вы будете встречаться так же редко, как и с такими экзотическими болтами. Раскраска ячеек таблиц в LaTeXКто сказал, что таблицы в LaTeX унылы и безжизненны? Хотя часто раскраска таблицы не одобряется, иногда, особенно в презентациях, выделение ячеек таблицы цветом помогает быстрее понять материал.Для раскраски ячеек нам понадобятся пакеты \usepackage{color,colortbl}и в преамбуле определяем цвета, которые нам нужны: \definecolor{darkishgreen}{RGB}{39,203,22}Теперь нужно сделать отдельный тип цветных колонок для таблицы. Для этого в документе, уже после \begin{document}, создаём новые команды в виде: \newcolumntype{g}{>{\columncolor{Gray}}c}и \newcolumntype{d}{>{\columncolor{darkishgreen}}c}Это позволит нам раскрашивать колонки. Для раскраски строк воспользуемся командой \rowcolor{цвет} из пакета colortbl. Можно раскрасить отдельно ячейку с помощью команды \cellcolor{Gray} которую помещаем в раскрашиваемую ячейку. А теперь всё вместе: \newcolumntype{g}{>{\columncolor{Gray}}c} \newcolumntype{d}{>{\columncolor{darkishgreen}}c} \begin{tabular}{|c||c||g||d|d|d|} \hline Signal & \cellcolor{Gray} Device & \multicolumn{4}{|c|}{Computation time, s}\\ \cline{3-6} Strength & \cellcolor{Gray} size &Dantzig- &Branch and & Active &Projected\\ & &Wolfe &Bound &Set &Gradients\\ \rowcolor{lightRed} \hline Weak & 7x7 &400 &230 &200 &58\\ \cline{3-6} \rowcolor{lightRed} (0\% constr.) & 10x10 &1000 &840 &500 &135 \\ \cline{3-6} \hline \rowcolor{modRed} Moderate & 7x7 &640 &380 &270 &54\\ \cline{3-6} \rowcolor{modRed} (5\% constr.) & 10x10 &3120 &1200 &700 &110 \\ \cline{3-6} \hline \rowcolor{strongRed} Strong & 7x7 &1400 &290 &350 &55\\ \cline{3-6} \rowcolor{strongRed} (20\% constr.) & 10x10 &15320 &810 &960 &120 \\ \cline{3-6} \hline \hline \end{tabular}В документе такая таблица выглядит вот так:  Здесь ещё можно отметить использование || в качестве двойного разделителя колонок. Изменение размеров строк и столбцов в ЛаТеХ таблицеПеременная \arraystretch отвечает за расстояние между строками а переменная \tabcolsep соответственно за расстояние между столбцами. В примере ниже мы сделаем столбцы и строки пошире:\renewcommand{\arraystretch}{1.8} %% increase table row spacing \renewcommand{\tabcolsep}{1cm} %% increase table column spacing \begin{center} \begin{tabular}{|c|c|c|} \hline Расширение краёв: & \textbf{1,0-1,4} & размер ФРТ \\ \hline Аподизация: & \textbf{0,25-0,30} & размер ФРТ \\ \hline Сглаживания краёв: & \textbf{0,25-0,50}& размер ФРТ \\ \hline \end{tabular} \end{center} В документе это будет выглядеть так:  Изменение высоты одной строки в таблицеИногда требуется сделать одну из строк в таблице побольше, не задевая все остальные. Здесь поможет трюк с командой rule: команда вставит невидимую горизонтальную линию заданной ширины и толщины:\rule[высота подъёма линейки]{ширина}{толщина}Это не единственный манёвр, который позволяет увеличить расстояние между строками: можно в конце строки, после \\ вставить [1cm], увеличив размер строки соответственно. В данном примере мы расширим первую строку в таблице с помощью \rule{0cm}{2cm} и вторую с помощью [1cm] следующим образом: \begin{center} \begin{tabular}{|c|c|c|} \hline \rule{0cm}{2cm} Расширение краёв: & \textbf{1,0-1,4} & размер ФРТ \\ \hline Аподизация: & \textbf{0,25-0,30} & размер ФРТ \\ [1cm] \hline Сглаживания краёв: & \textbf{0,25-0,50}& размер ФРТ \\ \hline \end{tabular} \end{center}
Так выглядит таблица в документе: Ещё немного о трюках с таблицами можно почерпнуть там. Книжные таблицы в LaTeX: booktabsПо умолчанию таблицы, набранные в латехе, смотрятся неплохо, хотя им недостаёт "книжного" вида. Например, первая и последняя линия в таблице обычно жирнее, чтобы показать начало и конец таблицы.Если вам хочется набирать таблицы "как у больших дядь в книжках", можно воспользоваться пакетом booktabs. Подключив в преамбуле документа \usepackage{booktabs} мы сразу же имеем возможность набирать красивые таблицы. "Большие дяди" стараются сделать таблицы проще, с комфортным для глаз расстояниями между строками, и почти никогда не используют вертикальные разделители.Вот код для такой таблицы: \begin{tabular}{llr} \toprule %%% верхняя линейка \multicolumn{2}{c}{Постобработка} \ \cmidrule(r){1-2} Вид & Описание & Время выполнения, сек. \ \midrule %%% тонкий разделитель Расширение краёв & холодный старт & 12 \ & горячий старт & 8 \ Аподизация & симметричная & 90 \ Сглаживания краёв & по Гауссу & 33 \ \bottomrule %%% верхняя линейка \end{tabular}
Вот как выглядит такая таблица: Когда столбцов в таблице слишком много...Чтобы проще было задавать число колонок таблицы, особенно если их много, можно использовать конструкцию вида \begin{tabular}{l*{X}{l}}, где X это число колонок.Вот пример такой таблицы с 10 колонками: \begin{tabular}{l*{10}{l}} \hline Расширение краёв: & 1 & 2 & 3 & 4 & 5 & 6 & 7 & 8 & 9 \\ \hline Аподизация: & 1 & 2 & 3 & 4 & 5 & 6 & 7 & 8 & 9 \\ \hline Сглаживания краёв: & 1 & 2 & 3 & 4 & 5 & 6 & 7 & 8 & 9 \\ \hline \end{tabular} А вот как она выглядит в готовом документе:  Стоит отметить пакет siunitx, который предоставляет возможность выравнивания по десятичной точке или запятой. Также можно посмотреть на пакет array, предоставляющий расширенные версии окружений tabular и array (например, вертикально центрированные колонки и возможность определять новые типы колонок). СсылкиЭти трюки позволят создать весьма навороченные таблицы без необходимости перечитывать томик квантовой физики.Конечно, есть ещё много пакетов по работе с таблицами, например ltxtable - это longtable и tabularx, который стоит использовать для создания больших и сложных таблиц с разделением по страницам, с кучей текста в ячейках. Многостраничные таблицы так же может создавать пакет supertab. Cтоит упомянуть пакет slashbox, который позволяет создавать ячейки, разделенные по диагонали. Стоит ещё отметить хороший туториал по таблицам, который включает \multirow и \multicol. Поборники русского стиля оформления таблиц могут заинтересоваться постом по ссылке. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Sunday, December 30th, 2012 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 9:00 pm | Новый 2013 год и подведение итогов 2012 Очередной понедельничный пост, на сей раз новогодний. Решил подвести немного итогов года, оглянуться назад и почить на лаврах :-) Как оно было?В смысле постов - их было столько же, сколько и в предыдущем году. Стало больше гостевых постов, и это радостно: гостевые посты вносят свежую струю в блог, и так я узнаю много нового и интересного (и надеюсь, не только я). Запущен в тестовом режиме Лунодром "Дебианити". Это совсем мелкие заметки на манжетах, ссылки и прочие наброски, не подходящие под формат записок. Итог моих экспериментов со scriptogr.am и markdown, а так же временное решение проблемы хранения мелких набросков под рукой (ещё один блог заводить не хочется, здесь публиковать рано или ни к чему, а пригодиться могут). Теперь итоги. Посты были разные, и интересно взглянуть на то, что понравилось из написанного мне, и что - читателям. Топ5 постов, которые нравятся мнеЕсть посты, которые пишутся в формате "чтобы не забылось" - и это почти всё про LaTeX и Gnuplot, которыми я пользуюсь постоянно. Но есть и нечто особенное, что стоит много часов и дней усилий по сбору материала и выпиливанию подробностей. Итак, мой Топ-5 постов за этот год, которые мне нравятся.Странное рождение и долгая жизнь UNIXПост года, во всяком случае для меня, и самый большой перевод с английского на русский. На перевод и утрясание копирайтов с IEEE ушло почти четыре дня, но результат того стоил. Хотя переводчик с меня не очень хороший, смысл, думаю, передать удалось. Пост важен с исторической точки зрения, дабы помнить, с чего всё начиналось.Статистика: +31 Plus one, 27 Comments, 5977 Views. Markdown - гаечный ключ для забивания треугольных болтовПосле того, как я нашёл применение Markdown в качестве простого и быстрого генератора вложенных списков для LaTeX, он стал частью моего workflow. Но этому предшествовала переписка с iv_vl, которая, надо сказать, направила меня по ложному следу. Пост был написан после того, как я перепробовал массу опенсорсных сноповязалок и прочих велосипедов с квадратными колёсами :-)Статистика: +24 Plus one, 33 Comments, 2699 Views. Краткий обзор современных окружений рабочего столаНесколько неожиданный для меня экспромт Vlsu, ставший отличным постом. Прекрасные иллюстрации, структура и описания, хотя самый первый вариант был вызывающе неполиткорректным :-) Тем не менее, пост более чем стоил усилий, на него потраченных - один из лучших постов этого года, и абсолютный лидер по количеству просмотров. Браво, Vlsu, снимаю шляпу.Статистика: +25 Plus one, 72 Comments, 13020 Views. Pomodoro: тайм-менеджмент, который работаетPomodoro я использую уже больше года, и для меня это было большим прорывом в плане учёта и анализа собственной продуктивности. Позволяет делать больше без стахановских рывков и прочего ненужного героизма. Пост, один из самых подробных за этот год, писался долго и был сильно улучшен усилиями комментаторов.Статистика: +28 Plus one, 26 Comments, 3991 Views. Настольный Змей ГорынычОдин из наиболее информативных постов для меня лично - узнал много нового про multihead, хотя это стоило некоторых денег (купленные переходники, хотя и используются время от времени, но tripple-head на ноутбуке не вышел). Пост нравится своей структурированностью, которая стоила немалых усилий. Кроме того, один из немногих постов, почти полностью написанный в Markdown.Статистика: +22 Plus one, 18 Comments, 2169 Views. Топ5 постов, которые понравились читателямЗдесь я ориентировался по числу PlusOne и просмотрам. В комментариях можно отвести душу и привести свои списки, но здесь балом правит бездушная статистика.Вскрытие 9В батарейки: в поисках батареек ААААНаписанный за час и почти не стоивший усилий, пост неожиданно понравился народу на Хабре и собрал больше всех ПлюсАдынов за этот год (почти полсотни). Все деньги, потраченные на его написание, с лихвой отбились кассовыми сборами с рекламы :-)Статистика: +46 Plus one, 18 Comments, 5041 Views. Странное рождение и долгая жизнь UNIXЗдесь наши симпатии совпадают - второй пост по плюсадинам. Кривизну перевода сильно выправил тов. Minoru, за что ему большое спасибо.Статистика: +31 Plus one, 27 Comments, 5977 Views. Краткий обзор современных окружений рабочего столаСамый комментируемый и самый посещаемый пост года от Vlsu. Уже растащен на скриншоты, понаставлена куча ссылок и есть по крайней мере два репоста. Как говорится, признание к художнику приходит не тогда, когда его работы в первый раз выставят, а тогда, когда их в первый раз украдут :-)Статистика: +25 Plus one, 72 Comments, 13020 Views. Возможности настройки GRUB2 в LinuxВторой пост по числу просмотров в этом году, и не мой, а написанный Yamamaya. Очень подробный и насыщенный деталями, хотя это и было главным объектом критики ведущего. Тем не менее, пост информативный и второй по количеству просмотров за год.Статистика: +24 Plus one, 29 Comments, 10591 Views. Как редактировать в Vim без порчи и бибиканьяСнова гостевой пост, на этот раз от Pento, о текстовом редакторе, который пищит и всё портит. Несмотря на краткость и лаконичность, набрал почти 9000 просмотров и часто появляется в поисковых запросах о Vim.Статистика: +6 Plus one, 38 Comments, 8480 Views. И ещё немного статистикиОтбирать что-то лучшее всегда непросто, поэтому я приведу Топ5 самых посещаемых, самых комментируемых и собравших больше всех +1 постов, опубликованных в этом году. Ваше слово, товарищ Статистика!Самые плюсадинистые
Самые комментируемые
Самые просматриваемые
Глядя в даль...В следующем году будет... а, впрочем, кто его знает, что там будет. Много черновиков и идей, мало времени, много интересного. Приоткрывая пухлую папку черновиков, можно видеть наброски про латех, гнуплот, программирование на C и Матлаб, не очень много про железо, немного про ядро, пара забойных обзоров и ещё кое-что про Андроид. Ну и что там гостевые авторы понапишут. Кстати, ваши посты тоже тут могут засветиться - гостевые посты принимаются в любое время.Открывая шампанское...С новым годом Линукса на Десктопе! Чтоб никогда ничего не падало, чтоб фич было много, а багов - мало. Чтоб была свобода, Столлман, равенство и братство :-)Ну и уж этот-то год точно станет Годом Линукса на Десктопе :-) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Sunday, December 16th, 2012 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 6:04 pm | Декомпиляторы, или Что делать, если нужно восстановить исходники из бинарников? Проблема восстановления исходного кода из скомпилированных бинарников возникает сравнительно часто и протекает остро, с воем и рыданиями. Здесь нам, до некоторой степени, помогут замечательные программы-декомпиляторы, и в этом посте автор собрал свои скромные попытки выдрать исходники (или хотя бы намёки на них) из скомпилированных из С-шного кода бинарников.
Задача для декомпилятора бинарников, собранных из С кода:
Классический случай: один деятель на факультете написал на правильном ANSI C (и используя библиотеки BLAS и LAPACK) нужные и хорошие алгоритмы, и скомпилировал их в виде MEX-файлов для использования (это С-шный код, который можно вызывать из МАТЛАБ).Но потом он повздорил с народом, разозлился и свалил в частную контору, унеся все исходники с собой. Документации нет. Копий исходников нет. Есть обрывки личной переписки и намёки в сопровождающих файлах на тип алгоритма. Вариант физического воздействия на автора тупыми тяжёлыми предметами не рассматривается. Нужно восстановить исходники если и не до компилируемого состояния, то во всяком случае выудить оттуда алгоритмы и ключевые методы, использованные при реализации.
Кратко: суть и сложность проблемы
Декомпилятор (Decompiler) пытается перевести скомпилированный бинарный файл обратно в некое подобие исходного кода. Качество выхлопа зависит от особенностей языка исходника:
Если вы думаете, что с помощью декомпилятора вы получите обратно красивый код на С - вы будете сильно разочарованы. В лучшем случае на выходе будет общая (и довольно грубая) структура программы, в худшем - только имена функций и немного мусора. Так что ответ на вопрос заголовка поста: "Обхватить голову руками и закричать #$@@@@@!" :-)
Программы для декомпилирования (decompilers) для C/C++
Декомпиляторов для C/C++ немного, и ниже список из наиболее работоспособных. Здесь нет разделения на опенсорс или Linux-only - для такого дела, как вскрытие исходников, можно (и нужно) поступиться своими светлыми идеалами и наступить на горло собственной песне.Сразу замечу: скорее всего, ни один декомпилятор не выдаст вам сразу компилируемый код. Придётся потратить порядком времени и сил, чтобы это месиво превратить в код, который можно читать (желательно, не только компилятору). Boomerang Boomerang это C decompiler с открытыми исходами:
Качество кода, выдаваемого декомпилятором:
Программа всё ещё в состоянии бета-версии и для больших проектов не подходит. Скачать можно здесь. RecStudio Интерактивный декомпилятор RecStudio для С и (отчасти) С++, закрытая разработка:
Программа работает вполне стабильно, есть сборки под Linux. Скачать можно здесь. dcc - DOS to C decompiler Поточный декомпилятор Dcc, только ANSI C и для exe-файлов, с открытым исходным кодом под GPL:
Скачать можно отсюда (на сайте университета). Hex Rays - plugin для IDA Pro На самом деле Hex Rays не является отдельной программой - это плагин-декомпилятор для IDA Pro. Комбинация продвинутых возможностей IDA Pro (это дизассемблер) и Hex Rays в качестве декомпилятора очень впечатляет, как и аэрокосмическая цена. По причине закрытости продукта (нет даже демо-версии) и нереальной цены в этом разделе про Hex Rays больше ничего написано не будет. Ходовые испытания в реальных условиях Для начала попробуем декомпилировать что-нибудь совсем простенькое и написанное на ANSI C и с использованем библиотеки BLAS для векторых и матричных операций. Бинарный файл можно скачать здесь. 1. Простенький C-шный бинарник + BLAS Собственно, код на C для перемножения матрицы и вектора (используется CBLAS). Исходник: #include <stdio.h> #include <cblas.h> double m[] = { 3, 1, 3, 1, 5, 9, 2, 6, 5 }; double x[] = { -1, -1, 1 }; double y[] = { 0, 0, 0 }; int main(void) { int i, j; for (i=0; i<3; ++i) { for (j=0; j<3; ++j) printf("%5.1f", m[i*3+j]); putchar('\n'); } cblas_dgemv(CblasRowMajor, CblasNoTrans, 3, 3, 1.0, m, 3, x, 1, 0.0, y, 1); for (i=0; i<3; ++i) printf("%5.1f\n", y[i]); return 0; } После перемножения выдаст результат на консоль. Выхлоп Boomerang У него много ключей и параметров, часть которых не знает даже официальная, скажем так, документация. Тем не менее, для ключа -Td (Use data-flow-based type analysis) мы имеем выхлоп в стиле дзен: double y; double m = 3.; // address: 0x80484e4 int main(int argc, char **argv, char **envp) { void *local23; // r28 for(;;) { proc1(); } } Скажем так, не слишком ободряюще. Ключ -Tc (Use old constraint-based type analysis) выдаёт больше информации к размышлению: char y[24]; long long m[9] = { 0x4008000000000000LL, 0x3ff0000000000000LL, 0x4008000000000000LL, 0x3ff0000000000000LL, 0x4014000000000000LL, 0x4022000000000000LL, 0x4000000000000000LL, 0x4018000000000000LL, 0x4014000000000000LL }; // address: 0x80484e4 int main(int argc, char **argv, char **envp) { int local10; // r24 int local13; // r28 int local14; // r29 int local15; // r32 int local2; // m[r28 + 72]{60} int local3; // r28{181} int local6; // m[r28 + 72]{119} int local7; // m[r28 + 72]{149} int local8; // m[r28 + 76]{9} int local9; // m[r28 + 76]{49} *(int*)(local13 - 4) = local14; *(int*)(local13 - 12) = 0; local3 = local13 - 84; if (*(int*)(local3 + 72) > 2) { *(int*)(local3 + 52) = 1; *(int*)(local3 + 48) = 0x8049868; *(long long*)(local3 + 40) = 0.; *(int*)(local3 + 36) = 1; *(int*)(local3 + 32) = 0x8049848; *(int*)(local3 + 28) = 3; *(int*)(local3 + 24) = 0x8049800; *(long long*)(local3 + 16) = 1.; *(int*)(local3 + 12) = 3; *(int*)(local3 + 8) = 3; *(int*)(local3 + 4) = 111; *(int*)local3 = 101; cblas_dgemv(); local6 = 0; for(;;) { *(long long*)(local3 + 4) = y[0]; *(int*)local3 = 0x80486b6; proc1(); local7 = *(int*)(local3 + 72) + 1; } } local8 = 0; for(;;) { local10 = *(int*)(local3 + 72) + *(int*)(local3 + 72) + *(int*)(local3 + 72); local15 = m[local10]; *(long long*)(local3 + 4) = local15; *(int*)local3 = 0x80486b0; proc1(); local9 = *(int*)(local3 + 76) + 1; } } Подробностей тут больше, и тут выловлен самый главный ключик - cblas_dgemv(); Выхлоп RecStudio Намного более обилен и представляет собой следующий поток сознания: // Generated by Rec Studio 4 - build Oct 20 2012 _init() {// addr = 0x08048398 _unknown_ __ebx; // r1 _unknown_ __ebp; // r6 _unknown_ _t2; // _t2 __esp = __esp - 4; L1(); _pop(__ebx); if( *((intOrPtr*)(_t2 + 0x1414)) != 0) { __gmon_start__(); } frame_dummy(); __do_global_ctors_aux(); _pop(__eax); return; } L080483A4() { _unknown_ _t2; // _t2 _pop(__ebx); if( *((intOrPtr*)(_t2 + 0x1414)) != 0) { __gmon_start__(); } frame_dummy(); __do_global_ctors_aux(); _pop(__eax); _pop(__ebx); __esp = __ebp; _pop(__ebp); return; } __gmon_start__() {// addr = 0x080483D8 goto __imp____gmon_start__; } putchar() {// addr = 0x080483E8 goto __imp__putchar; } __libc_start_main() {// addr = 0x080483F8 goto __imp____libc_start_main; } cblas_dgemv() {// addr = 0x08048408 goto __imp__cblas_dgemv; } printf() {// addr = 0x08048418 goto __imp__printf; } _start( signed int __eax, // r0 _unknown_ __edx // r3 ) {// addr = 0x08048430 _unknown_ __ebx; // r1 signed int _t5; // _t5 _unknown_ _t6; // _t6 _unknown_ _t10; // _t10 __edx = __edx; _t4 = __eax; _pop(__esi); __ecx = __esp; __esp = __esp & 240; _push(__eax); _push(__esp); _push(__edx); _push(__libc_csu_fini); _push(__libc_csu_init); _push(__ecx); _push(_t10); _push(main); __libc_start_main(); asm("hlt "); 0; 0; _push(0); _push(_t6); __esp = __esp - 4; if(completed.5982 != 0) { } else { _t4 = dtor_idx.5984; _t6 = ( &__DTOR_END__ - &__DTOR_LIST__ >> 2) - 1; if(_t4 >= _t6) { } else { do { _t5 = _t4 + 1; dtor_idx.5984 = _t5; *((intOrPtr*)(_t5 * 4 + &__DTOR_LIST__))(); _t4 = dtor_idx.5984; } while(_t4 < _t6); } completed.5982 = 1; } __esp = __esp + 4; _pop(__ebx); _pop(__ebp); return; } __do_global_dtors_aux( _unknown_ __esi // r5 ) {// addr = 0x08048460 _unknown_ __ebx; // r1 _unknown_ __ebp; // r6 _unknown_ _t4; // _t4 signed int _t5; // _t5 signed int _t6; // _t6 _unknown_ _t10; // _t10 if(completed.5982 == 0) { _t5 = dtor_idx.5984; _t10 = ( &__DTOR_END__ - &__DTOR_LIST__ >> 2) - 1; if(_t5 >= _t10) { L4: completed.5982 = 1; return; } do { _t6 = _t5 + 1; dtor_idx.5984 = _t6; *((intOrPtr*)(_t6 * 4 + &__DTOR_LIST__))(); _t5 = dtor_idx.5984; } while(_t5 < _t10); goto L4; } return; } frame_dummy() {// addr = 0x080484C0 _unknown_ __ebp; // r6 __eax = __JCR_LIST__; if(__JCR_LIST__ == 0) { } else { __eax = 0; if(__eax != 0) { *__esp = &__JCR_LIST__; *__eax(); return; } } return; } main( _unknown_ __fp0 // r28 ) {// addr = 0x080484E4 signed int _v8; // _cfa_fffffff8 signed int _v12; // _cfa_fffffff4 intOrPtr _v32; // _cfa_ffffffe0 char* _v36; // _cfa_ffffffdc intOrPtr _v48; // _cfa_ffffffd0 char* _v52; // _cfa_ffffffcc intOrPtr _v56; // _cfa_ffffffc8 char* _v60; // _cfa_ffffffc4 intOrPtr _v72; // _cfa_ffffffb8 intOrPtr _v76; // _cfa_ffffffb4 intOrPtr _v80; // _cfa_ffffffb0 _unknown_ __ebp; // r6 __fp0 = __fp0; __esp = __esp & 240; __esp = __esp - 80; _v12 = 0; while(_v12 <= 2) { _v8 = 0; while(_v8 <= 2) { __fp0 ?_? *((long long*)((_v12 + __edx + __edx + _v8) * 8 + &m)); asm("fstp qword [esp+0x4]"); *__esp = 134514352; printf(); _v8 = _v8 + 1; } *__esp = 10; putchar(); _v12 = _v12 + 1; } _v32 = 1; _v36 = &y; asm("fldz "); asm("fstp qword [esp+0x28]"); _v48 = 1; _v52 = &x; _v56 = 3; _v60 = &m; asm("fld1 "); asm("fstp qword [esp+0x10]"); _v72 = 3; _v76 = 3; _v80 = 111; *__esp = 101; cblas_dgemv(); _v12 = 0; while(_v12 <= 2) { __fp0 ?_? *((long long*)(_v12 * 8 + &y)); asm("fstp qword [esp+0x4]"); *__esp = "%5.1f\n"; printf(); _v12 = _v12 + 1; } return 0; } __libc_csu_fini() {// addr = 0x080485F0 _unknown_ __ebp; // r6 return; } __libc_csu_init( intOrPtr _a4, // _cfa_4 intOrPtr _a8, // _cfa_8 intOrPtr _a12 // _cfa_c ) {// addr = 0x08048600 intOrPtr _v36; // _cfa_ffffffdc intOrPtr _v40; // _cfa_ffffffd8 _unknown_ __ebx; // r1 _unknown_ __edi; // r4 signed int __esi; // r5 _unknown_ __ebp; // r6 _unknown_ _t14; // _t14 _unknown_ _t15; // _t15 signed int _t18; // _t18 __i686.get_pc_thunk.bx(); _t15 = _t14 + 4529; __esp = __esp - 28; _init(); _t18 = _t15 + -248 - _t15 + -248 >> 2; if(_t18 == 0) { } else { __esi = 0; do { _v36 = _a12; _v40 = _a8; *__esp = _a4; *((intOrPtr*)(_t15 + -248 + __esi * 4))(); __esi = __esi + 1; } while(__esi < _t18); } __esp = __esp + 28; return; } __i686.get_pc_thunk.bx() {// addr = 0x0804865A return; } __do_global_ctors_aux() {// addr = 0x08048660 intOrPtr* __ebx; // r1 _unknown_ __ebp; // r6 __eax = __CTOR_LIST__; if(__eax == 255) { } else { __ebx = &__CTOR_LIST__; asm("o16 nop "); do { __ebx = __ebx - 4; *__eax(); __eax = *__ebx; } while(__eax != 255); } return; } _fini() {// addr = 0x0804868C _unknown_ __ebx; // r1 _unknown_ __ebp; // r6 _unknown_ _t1; // _t1 __esp = __esp - 4; L1(); _pop(__ebx); __do_global_dtors_aux(__esi); _pop(__ecx); return; } L08048698() { _unknown_ _t1; // _t1 _pop(__ebx); __do_global_dtors_aux(__esi); _pop(__ecx); _pop(__ebx); __esp = __ebp; _pop(__ebp); return; } L08048698() { _unknown_ _t1; // _t1 _pop(__ebx); @rec __do_global_dtors_aux@__do_global_dtors_aux@(__esi); _pop(__ecx); _pop(__ebx); __esp = __ebp; _pop(__ebp); return; } // Statistics: // 74 Register nodes // 35 Temporaries nodes // 5 Casts // 207 Statements // 2 Labels // 1 Gotos // 17 Blocks // 469 Nodes // 10 Assembly nodes // 27 Unknown Types Total time: 0 seconds. Структура программы (вначале) в общем несколько лучше, чем у Boomerang, и куда больше подробностей. 2. Бен, ай нид хелп: MEX-файл, | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Sunday, December 9th, 2012 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 7:30 pm | Как оформить исходный код программ в LaTeX без адских страданий Иногда в документ LaTeX нужно вставить кусок программного кода или псевдокод, поясняющий алгоритм. В зависимости от языка программирования и целей, подсветка кода в LaTeX достигается подключаемыми пакетами расширений разной степени кривизны и безумия документации. Как просто вставить программный код в LaTeX без боли и страданий? Именно такой вопрос однажды получил автор этих строк в свой ящик электропочты. Ответ: если хочется quick-and-dirty решения, можно воспользоваться пакетом verbatim, который запрещает LaTeX обрабатывать вставленный код и просто отображает код как есть. Дёшево и сердито: \begin{verbatim} Перед вставкой можно сделать так: cat -n code.c | fold -w 60Такая комбинация берёт исходный код в файле code.c и расставляет номера строк (ключ -n), перенося длинные строки (ключ -w 60 для ширины в 60 символов). Вот как это будет выглядеть в итоге:  Просто, дёшево, сердито и безболезненно. Verbatim с оформлением - alltt Ещё есть пакет под звучным названием alltt, который добавляет окружение alltt - это тот же verbatim, только в нём доступно оформление цветом, полужирным и т.д. Вот пример:  А вот для него код: \documentclass[a4paper,10pt]{article} \usepackage[T2A]{fontenc} \usepackage[koi8-r]{inputenc} \usepackage[usenames,dvipsnames]{color} \usepackage{alltt} \begin{document} \section{C code via alltt} \begin{alltt} \textit{1 int main(void)} 2 { 3 int i, j; 4 5 for (i=0; i<3; ++i) { 6 for (j=0; j<3; ++j) printf("%5.1f", m[i*3+j]); 7 putchar('\\n'); 8 } 9 10 cblas_dgemv(CblasRowMajor, CblasNoTrans, 3, 3, 1.0 , m, 3, x, 1, 0.0, y, 1); 11 12 14 15 return 0; 16 } \end{alltt} \end{document} Нюанс: в alltt eсть проблема c экранированием специальных символов типа \ и { поскольку alltt начинает воспринимать их как элементы оформления. Документация состоит из двух страниц. Как оформить псевдокод в LaTeX? Часто приводить дословно исходный код программы не требуется, но нужно пояснить общий ход алгоритма псевдокодом. Для оформления псевдокодов и алгоритмов наиболее вменяемый пакет называется algorithm2e доступный отсюда. Скачиваем стилевой файл algorithm2e.sty и прописываем его в преамбуле документа: \usepackage[linesnumbered,boxed]{algorithm2e} Здесь я включил следующие полезные параметры:
Вот как выглядит алгоритм, оформленный пакетом algorithm2e::  А вот для него код с комментариями (здесь комментарии, показанные серым цветом - для латеха и они не будут видны в алгоритме, а комментарии с двойной косой чертой - для показа в алгоритме): \begin{algorithm}[H] На алгоритм можно ссылаться, как и на другие объекты в ЛаТеХе - пакет algorithm2e поддерживает ссылки обычной командой \label{alg:generalGP} и соответственно ссылкой \ref{alg:generalGP}. Стоит отметить на удивление хорошую документацию: в справочном файле algorithm2e.pdf есть всё, что нужно настоящему
Как вставить код MATLAB в документ LaTeX
Для подсветки синтаксиса и вставки программного кода MATLAB в LaTeX есть специальный пакет расширений под незамысловатым названием mcode. Для использования этого пакета добавляем строчку в преамбулу:\usepackage[usenames,dvipsnames]{color}Обращаю внимание на то, что mcode должно идти после упоминания пакета color. Теперь, у mcode есть несколько параметров, а именно:
\begin{lstlisting}И вот что мы увидим в документе:  Самый мощный и кошмарный пакет LaTeX - listings, который может почти всё (кроме заваривания кофе), но самая большая проблема - выяснить, как и что со всем этим делать. В этом посте я просто приведу пример применения пакета listings и описание его настроек, чтобы самому не пришлось перечитывать кошмарную документацию listings.pdf Для примера вставим исходный код программы на С в документ LaTeX с помощью listings. Сразу скажу: всё нижеперечисленное приведено для английского языка, чтобы не огрести проблем ещё и с кириллицей. С языком осин и берёз listings дружит плохо, и кроме того, не переваривается latex2rtf - это важно, когда документ будет конвертироваться в ворд. Сначала правим преамбулу документа: \documentclass[a4paper,10pt]{article} \begin{document} Теперь уже внутри документа настраиваем вид оформление исходника программы на С. Здесь я привёл основные параметры с пояснениями, что они делают: \lstset{ % language=C, % выбор языка для подсветки (здесь это С) basicstyle=\small\sffamily, % размер и начертание шрифта для подсветки кода numbers=left, % где поставить нумерацию строк (слева\справа) numberstyle=\tiny, % размер шрифта для номеров строк stepnumber=1, % размер шага между двумя номерами строк numbersep=5pt, % как далеко отстоят номера строк от подсвечиваемого кода backgroundcolor=\color{white}, % цвет фона подсветки - используем \usepackage{color} showspaces=false, % показывать или нет пробелы специальными отступами showstringspaces=false, % показывать или нет пробелы в строках showtabs=false, % показывать или нет табуляцию в строках frame=single, % рисовать рамку вокруг кода tabsize=2, % размер табуляции по умолчанию равен 2 пробелам captionpos=t, % позиция заголовка вверху [t] или внизу [b] breaklines=true, % автоматически переносить строки (да\нет) breakatwhitespace=false, % переносить строки только если есть пробел escapeinside={\%*}{*)} % если нужно добавить комментарии в коде } Вставляем приведённые выше заклинания в тело документа и после этого куска кода вставляем, собственно, оформление исходника: \begin{lstlisting}[label=some-code,caption=Some Code] \end{lstlisting} Это всё должно скомпилироваться и выдать следующий результат:  Сравнительно красиво, в цвете и с кучей настроек. Остальные 1350 тумблеров, настроек и параметров вы найдёте в документации listings.pdf Замечание: Оказывается, algortithm2e очень не любит, когда вставляют разрыв строк - ругается, что пропущен параграф:
Listings и Хохруссиш...
не созданы друг для друга. Можно попробовать рецепт в виде:\lstset{language=Java,inputencoding=utf8предложенный здесь (в комментариях), но listings не работает нормально с русским текстом, состоящим более, чем из одного слова Зато listings работает с олдскульной и ортодоксальной koi8-r. Для это вставляем в преамбулу: \usepackage[T2A]{fontenc} \usepackage[koi8-r]{inputenc}%включаем свою кодировку: koi8-r или utf8 в UNIX, cp1251 в Windows \renewcommand{\lstlistingname}{Листинг} и далее меняем оформление исходника на это: \begin{lstlisting}[label=some-code,caption={Это крутой исходный код}] int main(void) // главная программа { int i, j; // инициализация счётчиков // Сей код множит матрицу величиною 3x3 for (i=0; i<3; ++i) { for (j=0; j<3; ++j) printf("%5.1f", m[i*3+j]); putchar('\n'); } // Вызов басурманской библиотеки BLAS cblas_dgemv(CblasRowMajor, CblasNoTrans, 3, 3, 1.0, m, 3, x, 1, 0.0, y, 1); // Подаём челобитную на экран for (i=0; i<3; ++i) printf("%5.1f\n", y[i]); return 0; } \end{lstlisting} В итоге мы получим кириллизованный фрагмент кода:  Нашедшие рабочий рецепт с listings и комментариями на русском в utf8 приглашаются им поделиться в комментариях. Итоги дискуссии по оформлению программного кода с русскими комментариями в listings: решение в использовании команд escapechar= или конвертацией документа в koi8/cp1251. Больше подробностей по этим ссылкам. Спасибо Роману Химову и Alexanius за ценные замечения в комментариях.Тем не менее, listings, хотя и не идеален, но представляет собой наиболее гибкое решение. Альтернативы Есть и другие способы добиться от LaTeX
highlight
Среди альтернатив выделяется во всех смыслах программа highlight, которая может быть использована для генерации LaTeX-разметки из исходника. Хорошая новость - у highlight проблем с UTF8 нет. Плохая новость в том, что highlight преобразует код таким образом, что его сложно корректировать вручную.
source-highlight
Другой вариант - использовать программу source-highlight, которая имеется в частности в репозиториях Debian. Установка не отнимет много сил и времени:apt-get install source-highlighи далее в командной строке пишем: source-highlight --input code.c --out-format latexcolor --src-lang=C --line-number > code.texТо есть раскрасить исходный код из файла и выдать в теховский файл code.tex для вставки в документ. Выхлоп source-highlight выглядит вот так: \noindent \mbox{}\texttt{\textcolor{Black}{16:}} \textcolor{Red}{\}} В общем, запасайтесь дьяволы гробами. Выглядит результат вот так:  Автор source-highlight явно покуривает что-то очень весёлое и бодрящее, на что легко может возбудиться ФСКН :-) Для работы всей этой светомузыки в преамбуле документа должна быть команда: \usepackage[usenames,dvipsnames]{color}В целом, это костыль, конечно, но он, скажем так, работает. Ссылки... ... приведены в посте выше, хотя это не предел человеческой фантазии, и имеют место быть альтернативы:
<a href="http://feeds.feedburner.com/~ff/debianletters? | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Monday, November 26th, 2012 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 2:17 am | Как содрать DVD в AVI и записать обратно: AVI to DVD write and rip in Linux
Копирование DVD в AVI и тем более запись фильмов обратно на DVD не то, что автор этих строк делает часто. А когда надо, начинается чесание затылка и судорожные попытки вспомнить, как оно делалось однажды при синей луне. Далее небольшая заметка по созданию и сдиранию (rip) фильмов из видеофайлов на DVD и обратно.
Копирование DVD-диска в AVI видеофайл Задача: имеется DVD-диск, и нужно его скопировать в AVI-видеофайл для резервного копирования или более удобного просмотра. При этом не очень хочется перечитывать
Как и чем содрать AVI файл из DVD
Для копирования DVD-дисков в Linux есть несколько программ, среди которых стоит отметить HandBrake и AcidRip.AcidRip это графическая обёртка на GTK2 для MEncoder, и у неё есть трудности с копированием зашифрованных дисков. HandBrake в этом смысле лучше, так как HandBrake копирует и зашифрованные диски. Установка HandBrake проста: нужно подключить репозитории Debian Multimedia. Для этого прописываем: deb http://www.debian-multimedia.org squeeze main non-freeв файле /etc/apt/sources.list и даём команду apt-get update и сразу же устанавливаем, собственно, HandBrake: apt-get install handbrake-gtkПосле установки можно сразу приступать к копированию DVD-видеодисков - интерфейс HandBrake прост и настройки по умолчанию дают приемлемый результат.  Можно выставить желаемое качество видеосжатия или размер конечного файла (тогда установки видеосжатия будут изменены соответствующим образом).  Создание DVD-диска из AVI видеофайла Допустим, у вас есть законно созданный видеофайл, и вам хочется создать DVD-диск, который сможет прочитать даже тупой китайский DVD-проигрыватель. Можно попробовать найти какие-нибудь графические поделки, но мы всё сделаем консольно и олдскульно (ибо оно чаще всего работает, а не просто кажет красивые кнопки). Тем более, что оно несложно.
Сестра, зажим!
Вот список того, что нам потребуется для заливания AVI файла на DVD:
# aptitude install mencoder ffmpeg dvdauthor dvd+rw-toolsТеперь всё готово к операции. Как сконвертировать AVI в DVD Если у нас есть несколько avi-файлов, например file1.avi и fille2.avi, сначала их надо слить в один: $ cat file1.avi file2.avi > ccmovie.aviТеперь нужно полученный файл прогнать через mencoder (опции -ovc и -oac просто копируют содержимое, без сжатия) $ mencoder -o out.avi -noidx -oac copy -ovc copy ccmovie.avi Выхлоп будет в файл out.avi. Теперь перегоняем видеофайл out.avi в другой, out.mpg, с соотношением сторон 16:9, чтобы было приятно смотреть на широком экране: $ ffmpeg -i out.avi -y -target ntsc-dvd -sameq -aspect 16:9 out.mpgСчастливым владельцам многоядерных процессоров можно присоветовать опцию -threads <count> , где <count> подставить число ядер (или по вкусу). Пережатие видео пойдёт значительно веселее:
$ ffmpeg -i out.avi
Здесь мы используем видеостандарт NTSC, популярный на диком и загнивающем Западе :-) Надо сказать, что DVD диск, помимо собственно фильма и звуковой дорожки, имеет всякие бубенчики и свистульки в виде меню и разного рода кнопок. Мы не Warner Brothers, чтобы заморачиваться с этим: $ dvdauthor --title -o dvd -f out.mpgМожно ещё сделать оглавление: $ dvdauthor -o dvd -TПочти всё готово, и в текущем каталоге должен появиться подкаталог dvd/ со следующим содержимым: AUDIO_TS VIDEO_TSОтлично, теперь нужно проверить правильность конвертации. Самое простое - натравить ваш любимый видеоплеер на этот каталог, например xine dvd:/full/path/to/DVD/VIDEO_TS/Должно начать играть видео, и если это случилось - пора залить всё на DVD-диск: growisofs -dvd-compat -dvd-video -speed=4 -Z /dev/dvd dvd/Всё, теперь диск готов радовать нас фильмом на большом экране.
Вместо заключения
Заметка не претендует на исчерпывающий обзор, а является тем, чем она является - запиской с рабочим рецептом. В комментариях можно привести другие рецепты и полезные замечания. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Monday, November 12th, 2012 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 5:07 am | График в Gnuplot с условиями: conditional data plotting in Gnuplot Как известно, одна картинка стоит тысячи слов. Вместо длинного и занудного изложения лучше привести график и его прокомментировать. Сложность в том, что иногда в график нужно запихнуть много данных, и дизайн графика превращается в самостоятельную задачу. Одна из таких задач - построение точек на графике в зависимости от условий (conditional data plotting). Проще говоря, при построении графика нужно, например, игнорировать точки в данных при условии, что они меньше какого-то порога. Или нужно сделать так, чтобы размер точки на графике зависел от самих данных. Это несколько экзотический случай, но иногда нужный.
Условное построение графиков и зачем это надо
Один из примеров приведён на сайте Гнуплота: в данном случае график иллюстрирует населённость городов на карте мира. То есть точка на графике становится больше или меньше в зависимости от данных в файле. Достигается это так: plot 'dataFile.dat' u 1:2:3 w points lt 1 pt 10 ps variable Весь трюк в том, чтобы размер точки (ps) сделать изменяемым (variable), причём размер теперь будет задаваться (в этом примере) колонкой номер 3 в файле данных. Это одно из проявлений гибкости gnuplot, которую можно использовать в своих корыстных целях. Условия при построении графиков Gnuplot куда более гибкий, чем кажется на первый взгляд. Помимо возможности задать переменные размеры точек, можно заставить Gnuplot строить графики с условием. Вот пример: ($1 <=3 ? $2 : 1/0)Это означает: если текущее число в первом столбце ($ 1) меньше 3, следует строить данные из второй колонки ($ 2), в противном случае ничего не строить вообще".Так можно строить сложные графики, особенно когда данных много и график нужно строить с разной подробностью. Например, вот такая конструкция: plot "./data.txt" using 4:($7>0.7 ? ($5*10**3) : 1/0):(1.2*$7) title "actuators DM" with points pt 6 ps variable lc rgb "cyan"означает, что если данные из седьмой колонки ($7) больше, чем 0.7, то строить данные из пятой колонки ($5) умноженные на 1000 (собственно, $5*10**3). Дальше идёт трюк с переменным размером точки: размер точки на графике будет меняться (ps variable) в зависимости от данных в седьмой колонке, помноженные на коэффициент 1.2, то есть (1.2*$7)
Реальный график с переменным размером точки
Всё это выглядит, конечно, очень круто, но пока не понятно, зачем всё это нужно. Тем не менее, это было продиктовано необходимостью выразить на одном графике многое. А именно:Есть оптимизационный алгоритм, и он решает ограниченную задачу квадратичной оптимизации (Constrained Convex Quadratic Programming). Хочется посмотреть, как растёт время вычисления в зависимости от того, сколько ограничений нарушено. Если ограничений не нарушено, всё решается быстро, но когда ограничения активны, время растёт - и самое неприятное то, что у этого времени вычисления появляется некий разброс. Распределение вероятности наперёд неизвестно.Кроме того, хочется на одном графике сравнить несколько наборов, для каждого набора - зависимость времени вычисления от нарушенных ограничений. При этом у времени есть некий разброс, и его хочется показать. Есть вариант построить распределение вероятности для каждого случая, и это будет выглядеть вот так:  но тогда графиков получится очень много и их задолбаешься описывать в статье. Долгие муки творчества породили следующий инфернальный график:  Как говорилось выше, здесь показан разброс времени, которое занимает расчёт некой оптимизационной задачи с ограничениями для нескольких наборов сразу (каждый набор показан своим цветом с разной формой точек). Грубо говоря, если вы посмотрите на распределение вероятности (probability density) сверху - вы как раз что-то подобное и увидите. Чем более вероятнее событие, тем крупнее для него точка. И так на одном графике можно увидеть, как растёт не только время вычисления, но и его разброс. Так что если помедитировать над графиком после всех этих объяснений, то становится в общем понятно, что автор хотел сказать и до некоторой степени эпатировать публику. По крайней мере это стало понятно аудитории, на которой это было бесчеловечно испытано. Вот gnuplot код для того ``инфернального'' графика:
Собственно, ничего в нём особо страшного нет, просто дизайн графика и организация для него данных, мягко скажем, нетривиальны. Самый смак в том, что при построении графика можно задать параметр: который управляет подробностью выдачи распределения точек:statthresh=0.6 На самом деле, в столбце $7 содержатся данные о вероятности (точнее, о частоте появления) того или иного временного интервала в данных. Чем больше порог, тем подробнее распределение точек на графике можно увидеть.using 4:($7>statthresh ? ($5*10**3) : 1/0):(1.0*$7) Если захотеть приключений, то можно вспомнить про такой тип графиков, как candlesticks (ай донт ноу хау ит из ин рашн сорри):  Код для него отсюда:
Насколько мне известно, такие графики используются для биржевых котировок и на торгах ценными бумагами. Вышеозначенную проблему отображения данных можно решить и так, но:
Пища для размышлений
Собственно в том, что с помощью Gnuplot можно отстрелить себе ногу, яйца и голову одним выстрелом, я думаю, сомнений ни у кого уже не осталось :-)Если серьёзнее, то данные по жизни имеют сложную структуру, и хотелось бы это отобразить наглядно и компактно. Иначе придётся вместо такого графика приводить 7 страниц таблиц, что ясности изложения не способствует. Рецептура для графика была почерпнута из разных источников и с миру по нитке. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Sunday, October 28th, 2012 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 9:04 pm | Настольный Змей Горыныч, или Как подключить много мониторов - Multihead in Linux В своё время автор этих строк купил себе новый ноутбук, водрузил на него Debian и воткнул внешний монитор. Казалось бы, ну и всё - что ещё надо джигиту для счастья? Одна голова — хорошо, а две — лучше, подумал автор, глядя на ещё одну электродырку в ноутбуке под названием DisplayPort. И подумалось мне: это ж можно задаром ещё и третий монитор прицепить, и будет неземное счастье. Но счастье обломилось (о чём ниже), а обзорчик от поисков решения остался ... Зачем нужно несколько мониторов?Наличие по крайней мере одного внешнего монитора гарантированно повысит продуктивность работы. Не знаю, как насчёт трёх мониторов, но два точно меняют жизнь к лучшему, и вот почему:
Программные решения: Что есть в Linux для Multihead?Программные решения это когда либо не хочется тратиться на нормальное железо, либо есть желание использовать уже имеющееся. Особенно актуально на ноутбуках: если есть выход на VGA/HDMI/DisplayPort, почему бы его не использовать?XrandRНа данный момент - самое простое и рабочее решение. XRandR позволяет изменять конфигурацию мониторов "на лету" (без перезагрузки X-server) и поддерживает аппаратное ускорение через OpenGL. Конфигурирование xrandr возможно через консольные команды, или через удобную графическую оболочку типа arandr.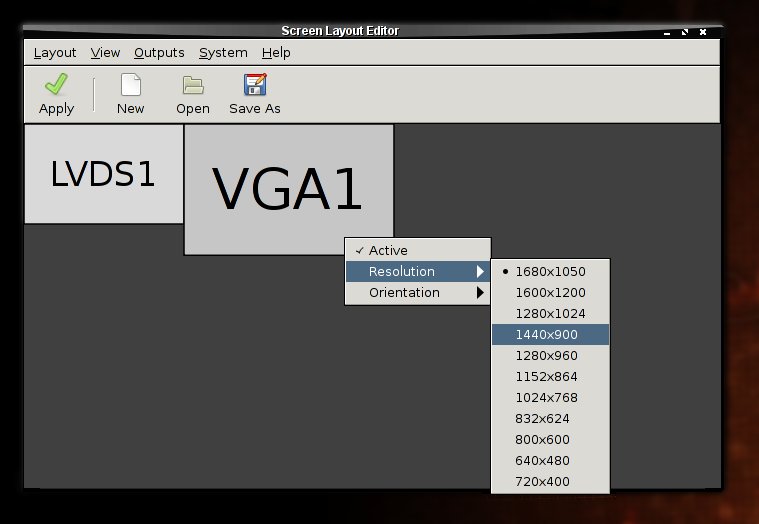 Собственно, история автора этих строк и началась с того, что был куплен адаптер DisplayPort2VGA для подключения третьего монитора к ноутбуку Lenovo T420. Всё шло очень хорошо и xrandr даже написал то, что третий монитор виден: То есть мониторы видятся оба, но при попытке задействовать все три приводит к ошибке: xrandr: cannot find crtc for output VGA1Что бы это всё значило? - спросил я себя, усиленно почёсывая затылок. А значит это вот что: CRTC это Cathode Ray Tube Controller, который аппаратно считывает кадры из framebuffer из видеопамяти и выводит изображение на экран. В понимании Xrandr, для каждого внешнего монитора должен быть свой аппаратный CRTC. На ноутбуках их обычно два: 0 и 1, то есть для встроенного монитора и внешнего. Это позволяет сделать полноценный dualhead, то есть два монитора соединить в один. Если же прицепить монитор третий монитор к уже существующему CRTC, то мы получим тоже изображение (clone mode).Но не всё так грустно: есть попытки надурить видеоадаптер и сделать Virtual CRTC. Virtual CRTC (VCRTC) is a new (and experimental) mechanism for redirecting pixels from a GPU's frame buffer to some other device. This code allows virtual CRTCs to be created in the kernel drivers so that they can be used for a variety of tasks. A virtual CRTC with this code is treated just like a real hardware CRTC. This experimental code allows these virtual CRTCs to be attached to "CTD devices" (Compression Transmission and Display). Then finishing off the equation is a new kernel module, the VCRTCM (Virtual CRTC Manager), that bridges the traffic between GPUs and CTDs.И хотя нынешние иксы (Xorg) поддерживают максимум 16 дисплеев, ограничения чаще всего упираются в видеокарту и наличие аппаратных CRTC не более 2. Остаётся надеяться на Virtual CRTC или отдавать кровные килодоллары за аппаратные многоголовые решения (о чём ниже). Плюсы Xrandr:
XineramaXinerama представляет собой расширение X Window System, которое позволяет приложениям и оконным менеджерам использовать два и более физических монитора как один большой. Это исторически был первый способ вообще получать объединённый монитор в иксах, и в Сети огромное количество рецептов на эту тему.Плюсы Xinerama:
Xdmx - Distributed Multihead XDMX расшифровывается как Distributed Multihead X. Обычно Xinerama или Xrandr позволяют делать multi-head, сшивая несколько мониторов в один, подключённых к одной и той же машине.С другой стороны, Xdmx это такой прокси сервер для X-ов, который позволяет объединять мониторы на разных машинах. Каждый компьютер, который вы хотите объединить с помощью Xdmx, запускает обычный X-сервер, а Xdmx сшивает эти иксы через прокси по сети Ethernet, и мы получим объединённый монитор из рядом стоящих ноутбуков через Ethernet.  Пример посложнее - объединение четырёх соединённых по сети ноутбуков в один монитор. Настройка Xdmx несколько нетривиальна, но есть отличное руководство от IBM.  Но основное применение Xdmx это создание огромных систем отображения данных для университетов и исследовательских центров. В основном это Diplay Walls с общим разрешением типа 16000x4800:  Такое есть, например, в Университете Северной Каролины и в Университете Иллинойса в Чикаго. Прочая экзотикаЕсть и другие методы получения нескольких мониторов в Linux.TwinViewПозволяет "сшивать" два монитора в один с аппаратным ускорением, при этом иксы думают, что это просто один монитор. Предназначен для карт Nvidia, и реализован только бинарными драйверами - фактически, только Nvidia карты и поддерживаются.Merged FramebufferПозволяет получать аппаратное ускорение графики на двух мониторах в режиме dualheaded для карт Radeon. Очень похоже на TwinView, но работает только с открытыми драйверами (mga, ati), в которых поддержка direct rendering часто не реализована. Кроме того, MergedFB ограничивает размер максимального экрана до 2048x2048.Аппаратные решенияКак правило, это проще в настройке и добавляет меньше головной боли. Самый правильный и лёгкий способ - Matrox TrippleHead2Go, но он стоит денег. Если начать жадничать, то можно остановиться на решении USB2VGA, но оно грузит процессор и требует драйвер.USB2VGAДа, бывает и такое. Плюс - сравнительно простой (если драйвер в ядре есть) способ получить дополнительный монитор (в зависимости от чипсета - и не один). Но всё это ложится тяжким грузом на CPU, ибо именно процессор сжимает видео и передаёт его через USB2VGA адаптер на другой монитор. Цена вопроса в районе $70: Другой пример - адаптеры от Displaylink типа DL-125, DL-165 и DL-195 которые поддерживают до шести мониторов и разрешение 1440х1050, 1920х1080 и 2048х1152 соответственно. Компания выкладывает исходники драйверов к ядру. Matrox TrippleHead2GoВот именно так и делается нормальная, честная аппаратная многоголовость (multihead). Matrox TrippleHead2Go представляет собой навороченную внешнюю видеокарту в компактном корпусе, в которую втыкается несколько мониторов (два или три). Разрешение воткнутых в TrippleHead2Go мониторов суммируется, а при работе - аппаратно разделяется на разные физические мониторы (сжатие видео не используется). При этом видеокарта вашего ноутбука или десктопа думает, что это один огромный монитор (и не подозревает, что её надурили). В результате вы получаете вожделенное Dual/Tripple Head с аппаратным ускорением и всеми плюшками без геморроя с настройкой:  Один минус - стоит это удовольствие около $400. И кроме того, не стоит подключать его через дополнительные адаптеры - в сети огромное количество полных горя отзывов персонажей, пытавшихся использовать этот TrippleHead2Go через дешёвые адаптеры. ЗаключениеЭтот пост был навеян тем, что автор внезапно обнаружил новую электрическую дырку под названием DisplayPort на борту своего ноутбука. Справедливо решив, что Ленова просто так порты не втыкает, возжелал извлечь из этого профит в виде третьего монитора. Но не получилось, и Xrandr мне выдал всю горькую правду: нет дополнительного контроллера CRTC у видеокарты - нет третьего монитора.Поиск облегчений не принёс, но в процессе гуглежа автор открыл для себя много нового, и чтоб оно не забылось, решил выложить в бложик. Всё имеет свои плюсы и минусы:
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Sunday, October 14th, 2012 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 6:45 pm | Thinkpad X201 - рабочее пони с сенсорным поворотным экраном  Мой старый-добрый ноутбук Asus M5200AE, который я купил ещё студентом в 2006, долгое время был моей основной рабочей машиной. И матлабовские скрипты на нём писал, и посты, и даже собрал в свою красноглазую молодость для него RT-ядро. Кстати, на нём до сих пор стоит Debian Etch - несколько консервативно, зато стабильно, олдскульно и ортодоксально, чего хватает этого для написания постов, электропочты, обзоров в LaTeX GTD и прочей мелочи. Но годы берут своё, и вот уже 512Mb памяти уже маловато, и жёсткий диск начал сдавать, и батарея померла, и кнопки понемногу отказывают. А тут на Ebay один мелкий австралийский магазин выложил old stock - собственно, Thinkpad X201 Tablet с поворотным экраном и за 800 долларов. Такой случай предоставляется не часто, и автор им воспользовался. Мой старый-добрый ноутбук Asus M5200AE, который я купил ещё студентом в 2006, долгое время был моей основной рабочей машиной. И матлабовские скрипты на нём писал, и посты, и даже собрал в свою красноглазую молодость для него RT-ядро. Кстати, на нём до сих пор стоит Debian Etch - несколько консервативно, зато стабильно, олдскульно и ортодоксально, чего хватает этого для написания постов, электропочты, обзоров в LaTeX GTD и прочей мелочи. Но годы берут своё, и вот уже 512Mb памяти уже маловато, и жёсткий диск начал сдавать, и батарея померла, и кнопки понемногу отказывают. А тут на Ebay один мелкий австралийский магазин выложил old stock - собственно, Thinkpad X201 Tablet с поворотным экраном и за 800 долларов. Такой случай предоставляется не часто, и автор им воспользовался.Как выглядит Thinkpad X201 TabletНоутбук очень маленький и компактный, с отличной клавиатурой и ярким поворотным экраном, чувствительным к нажатию. Замечательно, что наличие сенсорной прослойки на экране не сказывается на качестве изображения.
Экран можно повернуть, чтобы было удобнее читать длинный текст в книге. Но самое замечательное в X201 даже не экран, а неимоверное разнообразие способов взаимодействия:
 Немного критики. Автор этих строк всегда очень не любит, когда какой-нибудь балбес приходит и начинает ломать то, что всех устраивало. Так случилось с КДЕ4 и Гном3. Но хуже всего то, что в Lenovo пришли похожие ковбои и начали ломать наследие IBM. И вот эти узкоглазые выкинули легендарную, лучшую в мире ноутбучную клавиатуру с новых моделей. И хотя красный сексапильный трекпоинт всё ещё с нами, ему видимо уже недолго осталось жить. Новые клавиатуры, говорят, не так уж плохи. Но позвольте, если в обзорах каждый раз чествуют клавиатуру IBM, зачем же её выносить вперёд ногами?!
Наличие нормальной клавиатуры и было мотивацией покупки именно X201. Кроме того:
Технические характеристики
С точки зрения железа X201 представляет собой компромисс между компактностью и мощностью:
Стоит отметить, что экран очень яркий и наличие сенсорной сетки не делает картинку слегка размытой. В комплекте с ноутбуком шёл стилус и 8-cell battery, что обеспечивает до 7 часов автономной работы (kpowersave рисует страшные цифры в 10 часов, но мне в них верится с большим трудом). Сразу после включения...Сразу после включения ноутбука засветилась Windows 7 и начала меня принуждать
После перезагрузки в X201 была воткнута флешка с уже настроенной системой Debian GNU/Linux, обкатанной на вычислительном танке Thinkpad T420. Иксы сразу распознали видеокарту:
$ glxinfo
Нашёлся звук:
[ 6.883970] input: HDA Intel HDMI/DP,pcm=3 as /devices/pci0000:00/0000:00:1b.0/sound/c Беспроводная сетьСобственно, как и в случае с Thinkpad T420, за беспроводную сеть отвечает драйвер iwlwifi.[ 6.394602] iwlwifi 0000:02:00.0: loaded firmware version 9.221.4.1 build 25532Физически установлен следующий чип: Network controller: Intel Corporation Centrino Advanced-N 6200 (rev 35)Поэтому мы отправляемся за фирмварью 6000 Images for Intel Centrino Ultimate-N 6300 and Advanced-N 6200 вот сюда. Скачанный архив iwlwifi-6000-ucode-9.221.4.1.tgz распаковывается в директорию: /lib/firmwareи после перезагрузки (или включения wicd) загорится лампочка WiFi. Сенсорный экранДля поддержки стилуса и сенсорного экрана нужно установить пакет:xserver-xorg-input-wacom - X.Org X server – Wacom input driverВ моём случае в системе есть пакеты из Squeeze и Lenny, и немного Backports, установка выглядела несколько более эротично: пакет не хотел ставиться вообще, независимо от репозитория, пока я не скачал его отдельно и не воткнул с помощью dpkg.  Немного о стилусе Стилус при поднесении к экрану перемещает курсор мыши, причём экран его чувствует с 1-2 сантиметров. Кнопка на стилусе одна, но xournal её почему-то не признаёт. На другом конце есть ластик (красный), которым можно стирать изображение в GIMP и myPaint. В моём случае стилус просто работает (после установки драйверов) и сила нажатия там адекватна. Но некоторые пользователи жаловались на то, что по умолчанию нажимать на экран стилусом приходится слишком сильно. Это можно исправить традиционно опенсорсным способом, а именно вскрыв стилус и поправив чувствительность. На самом деле, всё не так сложно: для вскрытия нам потребуется тонкая плоская отвёртка или ножик. Нужно поддеть кнопку на ручке:   Забавно, но если вывернуть винт слишком далеко против часовой стрелки, то стилус станет регистрировать нажатие даже просто от наклона. Зачем нужен сенсорный экран, когда есть планшеты?Сенсорный экран добавляет много удобств при работе с ноутбуком:
Помимо управления окнами с помощью пальца и стилуса, можно использовать дополнительные возможности в виде чувствительности к нажатию в программах:
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||







LJ.Rossia.org makes no claim to the content supplied through this journal account. Articles are retrieved via a public feed supplied by the site for this purpose.