|
|
| Пишет Misha Verbitsky ( @ 2020-05-28 23:02:00 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| Настроение: | |
| Музыка: | Kraftwerk - Das Model Live 1982 |
| Entry tags: | covid |
as buggy as Kenya
Офигенно
https://github.com/mrc-ide/covid-si
https://streetwiseprofessor.com/code-vi
https://lockdownsceptics.org/code-revie
Математический биолог Нил Фергюсон из Империала больше
всего прославился тем, что на каждую эпидемию
выдавал прогнозы, которые были преувеличены,
самое малое, в 20 раз. Так, например, он предсказал
массовый мор от свиного гриппа в 2009-м, с 60,000
жертвами, и требовал карантина. В реальности
от свиного гриппа погибло 457 человек.
В феврале-марте этого профессора выдвинули
главным экспертом по ковиду от людей с хорошими твиттерами
из The Guardian и Financial Times. Британскому правительству
пришлось через нехочу последовать его указаниям,
то есть тотальному локдауну, с потешными
полицейскими гонками за одинокими прохожими.
О качестве его модели по ковиду легко судить, потому
что Фергюсон предсказал 40,000 смертей от ковида
в Швеции к 1 маю, и 100,000 к июню; реальный
график шведской смертности от ковида выглядит так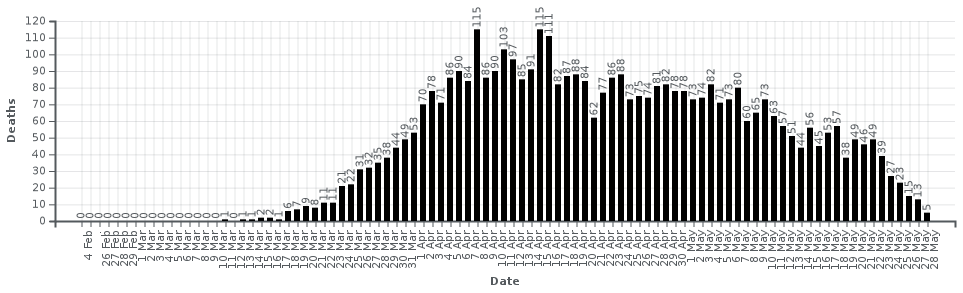
и суммарно там будет, видимо, не больше 7000
человек (сейчас 4266).
Что самое смешное, до недавнего времени
сама модель была не опубликована, то есть
исходники программы оставались секретными.
Месяца 2 или 3 Фергюсону выкручивали руки,
требуя публикации, а он отплевывался, но
недавно таки нанял каких-то программеров
из Микрософта, они почистили, улучшили и
выложили его поделие на гитхаб:
https://github.com/mrc-ide/covid-si
Немедленно оказалось, что в программе
ошибка на ошибке сидит и погоняет ошибкой же.
Борцы с ковидобесием сей код разобрали,
тыкают в него пальцем и смеются:
https://streetwiseprofessor.com/code-vi
https://lockdownsceptics.org/code-revie
https://lockdownsceptics.org/second-ana
https://lockdownsceptics.org/how-convin
https://twitter.com/SteveBakerHW/st
https://www.whatdotheyknow.com/requ
https://www.reddit.com/r/LockdownSkepti
The code that was reviewed in the first-linked article
. . . had been cleaned up! It's not the actual code used
to make the original predictions. Instead, people from
Microsoft spent a month trying to fix it-and it was still
as buggy as Kenya.
The code was originally in C, and then upgraded to
C++. Well, it could be worse. It could have been Cobol or
Fortran-though one of those reviewing the code suggested:
"Much of the code consists of formulas for which no
purpose is given. John Carmack (a legendary video-game
programmer) surmised that some of the code might have been
automatically translated from FORTRAN some years ago."
All in all, this appears to be the epitome of bad modeling
and coding practice. Code that grew like weeds over
years. Code lacking adequate documentation and version
control. Code based on overcomplicated and essentially
untestable models.
But it gets even better! The leader of the Imperial team,
the aforementioned Ferguson, was caught with his pants
down-literally-canoodling with his (married) girlfriend in
violation of the lockdown rules for which HE was largely
responsible.
The model. What it's doing is best described as "SimCity
without the graphics". It attempts to simulate households,
schools, offices, people and their movements, etc. I won't
go further into the underlying assumptions, since that's
well explored elsewhere.
Non-deterministic outputs. Due to bugs, the code can
produce very different results given identical
inputs. They routinely act as if this is unimportant.
The documentation says:
The model is stochastic. Multiple runs with different
seeds should be undertaken to see average behaviour.
"Stochastic" is just a scientific-sounding word for
"random". That's not a problem if the randomness is
intentional pseudo-randomness, i.e. the randomness is
derived from a starting "seed" which is iterated to
produce the random numbers. Such randomness is often used
in Monte Carlo techniques. It's safe because the seed can
be recorded and the same (pseudo-)random numbers produced
from it in future.
Investigation reveals the truth: the code produces
critically different results, even for identical starting
seeds and parameters.
I'll illustrate with a few bugs. In issue 116 a UK "red
team" at Edinburgh University reports that they tried to
use a mode that stores data tables in a more efficient
format for faster loading, and discovered - to their
surprise - that the resulting predictions varied by around
80,000 deaths after 80 days
That mode doesn't change anything about the world being
simulated, so this was obviously a bug.
Imperial advised Edinburgh that the problem goes away if
you run the model in single-threaded mode, like they
do. This means they suggest using only a single CPU core
rather than the many cores that any video game would
successfully use. For a simulation of a country, using
only a single CPU core is obviously a dire problem - as
far from supercomputing as you can get. Nonetheless,
that's how Imperial use the code: they know it breaks when
they try to run it faster. It's clear from reading the
code that in 2014 Imperial tried to make the code use
multiple CPUs to speed it up, but never made it work
reliably. Results that randomly change from run to run are
a common consequence of thread-safety bugs. More
colloquially, these are known as "Heisenbugs".
But Edinburgh came back and reported that - even in
single-threaded mode - they still see the problem. So
Imperial's understanding of the issue is wrong. Finally,
Imperial admit there's a bug by referencing a code change
they've made that fixes it. The explanation given is "It
looks like historically the second pair of seeds had been
used at this point, to make the runs identical regardless
of how the network was made, but that this had been
changed when seed-resetting was implemented". In other
words, in the process of changing the model they made it
non-replicable and never noticed.
Why didn't they notice? Because their code is so deeply
riddled with similar bugs and they struggled so much to
fix them that they got into the habit of simply averaging
the results of multiple runs to cover it up... and
eventually this behaviour became normalised within the
team.
In issue #30, someone reports that the model produces
different outputs depending on what kind of computer it's
run on (regardless of the number of CPUs). Again, the
explanation is that although this new problem "will just
add to the issues" ... "This isn't a problem running the
model in full as it is stochastic anyway".
Undocumented equations. Much of the code consists of
formulas for which no purpose is given. John Carmack (a
legendary video-game programmer) surmised that some of the
code might have been automatically translated from FORTRAN
some years ago.
For example, on line 510 of SetupModel.cpp there is a loop
over all the "places" the simulation knows about. This
code appears to be trying to calculate R0 for
"places". Hotels are excluded during this pass, without
explanation.
Continuing development. Despite being aware of the severe
problems in their code that they "haven't had time" to
fix, the Imperial team continue to add new features; for
instance, the model attempts to simulate the impact of
digital contact tracing apps.
Adding new features to a codebase with this many quality
problems will just compound them and make them worse. If I
saw this in a company I was consulting for I'd immediately
advise them to halt new feature development until thorough
regression testing was in place and code quality had been
improved.
Conclusions. All papers based on this code should be
retracted immediately. Imperial's modelling efforts should
be reset with a new team that isn't under Professor
Ferguson, and which has a commitment to replicable results
with published code from day one.
* * *
Вообще полезный сайт
https://lockdownsceptics.org
Гугл, к сожалению, деиндексирует либо зануляет
пейджранк любому сайту, где высказываются против
коронабесия, поэтому сходу подобные
страницы не найти, надо копаться.
Такие дела
Миша