|
|
| Пишет bbb ( @ 2008-02-25 18:34:00 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Об автомобилизацию
В ходе опроса об отношении к недавнему ужесточению наказаний за нарушение правил дорожного движения (http://bd.fom.ru/report/whatsnew/d0805
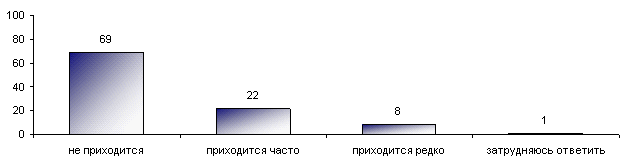
В ходе опроса об отношении к недавнему ужесточению наказаний за нарушение правил дорожного движения (http://bd.fom.ru/report/whatsnew/d0805
Лично Вам приходится или не приходится ездить за рулем автомобиля? И если приходится, то часто или редко?Ответ: