Шпаргалка Леше к экзамену по ОС.
/ - корневой каталог
/bin - содержит стандартные утилиты Linux. Или, скажем так, - этот каталог содержит основные исполняемые файлы (в Windows такие файлы имеют расширение .exe), доступные всем пользователям, а также содержит символьные ссылки на исполняемые файлы. Символьная ссылка это специальный файл в файловой системе, внутри которого есть только одна-две строки с указанием полного пути, который должен быть открыт при попытке обратиться к данной ссылке (файлу).
/boot - содержит конфигурационные файлы загрузчика GRUB, образы ядра (по умолчанию хранятся последние три), файлы Initrd. Чтобы было понятно, что это за такие мифические файлы Initrd, немного внесем ясность. Когда начинается начальная загрузка системы, сначала монтируется временный виртуальный диск, который содержит временную корневую файловую систему, с помощью которой, в свою очередь, осуществляется запуск ядра Linux. Файл Initrd - образ этой временной корневой системы, который хранится на загрузочном устройстве.
/dev - содержит файлы устройств. В Linux устройством называется оборудование, которое подключается к системе в процессе загрузки ядра или в процессе работы системы. Эти устройства представляют методы для ввода или вывода информации. Например, жесткий диск - устройство для ввода (запись) и вывода (чтение), мышь - устройство ввода. Каждое движение или нажатие на кнопки мыши отправляет символ на устройство /dev/mouse, клавиатура - тоже устройство ввода. Большинство устройств в Linux представляют из себя файлы в особой файловой системе (исключение составляют сетевые карты). И вот эти файлы хранятся в каталоге /dev, куда к ним обращается система для выполнения задач, связанных с вводом/выводом.
/etc - содержит конфигурационные файлы операционной системы и всех сетевых служб. Данный каталог можно сравнить с реестром Windows, но в Windows общесистемные настройки хранятся в одном большом бинарном файле, а в Linux - в разных конфигурационных файлах, которые можно редактировать обычным текстовым редактором.
/home - название каталога говорит само за себя. Здесь содержатся домашние каталоги всех пользователей, которые зарегистрированы в системе. В домашних каталогах пользователей хранятся пользовательские файлы, а также пользовательские настройки различных программ. Как мы уже упоминали в предыдущей статье, Linux является многопользовательской системой, и поэтому каждый пользователь имеет свой уникальный и неповторимый каталог для своих личных, персональных файлов. Этот каталог называется Домашним каталогом пользователя и обозначается, как мы уже говорили немного ранее, /home/Имя_Пользователя. Такое разделение пользовательских каталогов и файлов операционной системы упрощает сохранение данных и повышает надежность самой операционной системы.
/lib - здесь находятся различные библиотеки и модули ядра. В процессе установки различных программ в Linux (в том числе и драйверов) устанавливаются зависимости (о них мы уже говорили) для корректной работы программы. Вот эти зависимости в большинстве случаев и есть библиотеки - набор собранных особым образом файлов, которые подключаются во время установки к устанавливаемой программе.
/lost+found - этот каталог нужен для хранения испорченных файлов при проблемах с файловой системой, которые были восстановлены после, например, некорректного размонтирования файловой системы. Это очень ценный каталог, удалить его не получится (он всё равно снова появится).
/misc - может содержать все что угодно.
/mnt и /media - обычно в этих каталогах содержатся точки монтирования. В современных дистрибутивах Linux этот процесс обычно происходит автоматически. При этом в каталогах /mnt или /media создается подкаталог, имя которого совпадает с именем монтируемого тома.
/opt - здесь обычно размещаются установленные программы, имеющие большой дисковый объем, или вспомогательные пакеты, например, у меня в этом каталоге всего две программы - это Adobe Reader и Google Chrome
/proc - это не совсем обычный каталог, это каталог псевдофайловой системы procfs, которая используется для предоставления информации о процессах (по-другому это виртуальная файловая система, которая обеспечивает связь с ядром и монтируется в каталогу /proc). Да-да, в системе Linux присутствует виртуальный файловый объект, именуемый каталогом /proc. Он существует только во время работы системы в оперативной памяти компьютера. Каталог представляет интерес и с точки зрения безопасности. Многие из утилит, выводящие информацию о системе (например, команда ps), берут свои исходные данные именно из этого каталога.
/root - каталог пользователя root (кто это такой, мы упоминали в одной из предыдущих статей).
/run - это совершенно новый каталог, который появился совсем недавно. И создан он (по задумке разработчиков) для хранения данных, которые были запущены приложениями, требующимися в процессе работы (это могут быть и службы, запускаемые самой системой, и программы, которые Вы запускаете сами).
Сюда входят:
- Идентификаторы процессов PID (каждый запущенный в среде Linux процесс имеет свой уникальный идентификатор - по-другому это адрес (в числовом виде) процесса, с которым будут взаимодействовать другие запущенные процессы во время работы);
- Информация о межпроцессорном взаимодействии (проще говоря, это обмен данными между запущенными процессами);
- Заблокированные файлы (если в процессе работы приложение или не запускается, или работает нестабильно? это может означать, что некоторые файлы этого приложения заблокированы другими процессами и происходит это тогда, когда сразу несколько приложений пытаются использовать один общий ресурс); - ну и другие данные, необходимые во время работы.
/sbin - набор утилит для системного администрирования, содержит исполняемые файлы, необходимые для загрузки системы и ее восстановления в различных щекотливых ситуациях. Запускать эти утилиты имеет право только root.
/tmp - каталог, в котором хранятся временные файлы. Linux, в отличие от Windows, следит за чистотой и регулярно очищает этот каталог.
/usr - содержит пользовательские программы, документацию, исходные коды программ и ядра. По размеру это один из самых больших каталогов файловой системы. В этот каталог устанавливаются практически все программы. И его (этот каталог) с большой натяжкой можно сравнить с каталогом Program Files в Windows.
/var - содержит файлы, которые подвергаются наиболее частому изменению. Например, кэши различных программ; файлы блокировки для недопустимости одновременного использования одной программы несколькими пользователями; файлы системных журналов; временные файлы (при выключении компьютера содержимое очищается); информация о различных программах; общая информация о состоянии системы с момента последней загрузки, входа в систему и т.д.; очередь печати, факсов, а также входящие почтовые ящики пользователей и т.д.
Источник
Это репост с сайта http://tolik-punkoff.com
Оригинал: http://tolik-punkoff.com/2020/11/02/nazn
|
Page Summary
October 2030
|
Назначение стандартных каталогов Linux.
Linux. Узнать размер файла в байтах и сохранить его в переменную в скрипте.
Для дальнейшего использования удобнее всего получить размер файла с помощью утилиты du. Она входит в пакет coreutils, так что есть практически везде:du -sb ./test.txtгде: -sb - показывать размер в байтах./test.txt - путь к файлу.Вывод: 10 ./test.txtВывод команды du скармливаем awk и пишем результат в переменную:CURSIZE=`du -sb path/file|awk '{print $1}'`Можно проверить файл на минимальный размер, например для того, чтобы узнать, не произошло ли ошибок при скачивании: Это репост с сайта http://tolik-punkoff.com Оригинал: http://tolik-punkoff.com/2020/11/02/linu Получение в скрипте bash PID процесса, запущенного в фоне.
В Linux практически любой процесс можно сделать фоновым, для чего достаточно добавить & через пробел после команды. Например:openvpn --config ~/vpn/myvpn.ovpn &Да, про опцию конфига daemon писать в комментах не надо, вызов openvpn просто для примера.Но как же управлять процессом, например, остановить именно запущенный? По PID. Почему просто не воспользоваться pkill? Поясню на реальной задаче, например, на машине запускается несколько процессов openvpn, обеспечивающих коннект к нескольким провайдерам или нескольким сетям - если сделать pkill openvpn, положим сразу все процессы, а не конкретный. Значит, чтобы придушить конкретный процесс, надо получить конкретный PID.На самом деле все придумали за нас, в bash есть системная переменная $!, хранящая PID последнего запущенного в фоне процесса.Чтобы в другом скрипте остановить процесс, запущенный в первом, например, мы должны написать два скрипта для старта и остановки некоторой программы, мы должны куда-то сохранить полученный PID. Демоны в Linux обычно делают текстовый файл (т.н. PID-файл), куда записывают свой PID при запуске. В своем скрипте мы можем сделать также: openvpn --config ~/vpn/myvpn.ovpn & #запуск процессаVPNPID=$! #сохраняем PID в переменнуюНапример, для остановки процесса: VPNPID=`cat "/tmp/myvpn.pid"` # Читаем PID-файлПоскольку в системе всем процессам выдается уникальный PID, вне зависимости, например, от network namespace, в котором запущен процесс, соответственно, алгоритм сработает и для процесса, запущенного в сетевом неймспейсе: Запуск: ip netns exec <имя_неймспейса> openvpn --config ~/vpn/myvpn.ovpn &Останов: VPNPID=`cat "/tmp/myvpn.pid"` # Читаем PID-файлФАНФАРЫ! Это репост с сайта http://tolik-punkoff.com Оригинал: http://tolik-punkoff.com/2020/10/27/polu Linux dialog --tailbox
Прямая ссылка: https://youtu.be/kdOjJFtbuI4 Если переданный программе лог не дополняется, то tailbox просто отображает последние строки из файла (насколько хватает заданных размеров виджета)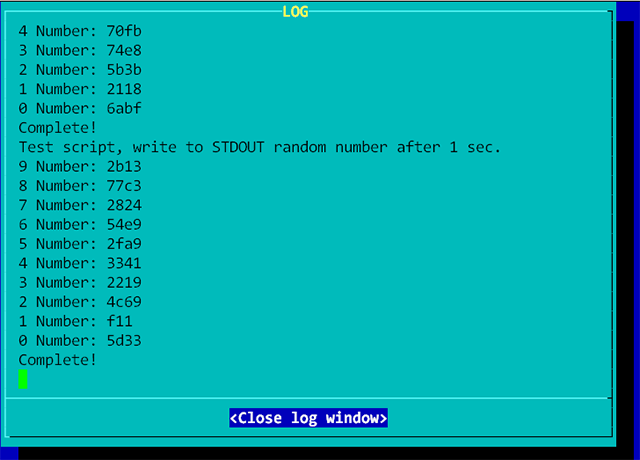 Вызов виджета: Например: Для демонстрации написал простой log viewer. Использование: logview путь_к_файлу( logview ) Скрипт на GitHub Вроде бы виджет простой, но при некоторой смекалке можно делать интересные вещи, например, вести лог сразу в трех местах - отображая его в --tailbox'е, одновременно отправляя изменения, происходящие в реальном времени на отдельный терминал, и сохраняя лог в файл (с перезаписью или дозаписью)Прямая ссылка https://youtu.be/AARNx4SbYJg Добиться этого можно, совместив dialog tailbox с командой tee (копия).Написал демонстрационный скрипт: ( Демонстрационный скрипт ) В качестве источника логов, демо-скрипт вызывает в фоновом режиме другой скрипт tscript, который выводит 10 случайных чисел на консоль и завершает работу:Настройки скрипта для поиграться можно провести через внутренние переменные: LOG_FILE="./test.log" - если значение не задано, создается временный файл, который по завершению скрипта удаляется.LOG_TTY="/dev/tty4" - если значение не задано, лог в реалтайме не отправляется на дополнительный терминалRMLOG=0 - 0 - по завершению скрипта лог не удаляется, 1 - удаляется.LOG_APPEND=1 - 0 - при каждом запуске создается новый файл. 1 - добавление данных в лог, если он существует.Скрипты на GitHub Это репост с сайта http://tolik-punkoff.com Оригинал: http://tolik-punkoff.com/2020/10/25/linu Генерация самоподписанных ключей для Dovecot
Пригодится для локального сервера почты или для тестирования проекта, где нужен свой почтовый сервер. Буду эту тему дальше развивать, следите по тегу mailserver (копия). 1. Создаем приватный ключ для корневого сертификата. 2. Создаем самоподписанный корневой сертификат. 3. Создаем приватный ключ для простого (не корневого) сертификата. 4. Создаем запрос на подпись простого сертификата. 5. Создаем простой сертификат, подписанный с помощью корневого. 6. Копируем приватный ключ для простого сертификата и сам сертификат в /etc/dovecot/private/7. Устанавливаем файлам права в 400. Т.е. разрешаем чтение только для владельца, остальное запрещаем.8. Если dovecot будет запускаться под отдельным пользователем, а так и надо, не забываем сменить файлам владельца.Поскольку, с первого раза настройка почтового сервера может не получиться [ВОРЧАНИЕ ON] куча инструкций, противоречащих друг другу или неполных, но одной хорошей и конкретной нет [/ВОРЧАНИЕ OFF] Вот скрипт: #!/bin/bashecho "Set permissions..."Скрипт на GitHub Это репост с сайта http://tolik-punkoff.com Оригинал: http://tolik-punkoff.com/2020/10/08/gene Добавление дополнительных network namespaces к уже настроенным.
Когда-то давно поднимал тему network namespaces (копия), механизма Linux, позволяющего на машине с одним физическим сетевым интерфейсом организовать несколько независимых сетевых стеков, т.е. виртуальных сетевых интерфейсов с разными настройками (IP-адресом, маршрутизацией, правилами IPTABLES и т.д.). Возник вопрос, как к уже настроенным сетевым неймспейсам добавить еще один. Это не просто, а очень просто. Итак, имеется система такой вот конфигурации:  А требуется нечто такое:  1. Создаем новый netspace с именем, например, linkns:ip netns add linkns2. Создаем два связанных между собой виртуальных сетевых интерфейса veth2 и veth3:ip link add veth2 type veth peer name veth33. Поднимаем интерфейс veth2, который останется в основном неймспейсе:ifconfig veth2 0.0.0.0 up4. Подождали, интерфейс поднялся (для проверки вызываем ifconfig без параметров):5. Ассоциируем veth3 с новым неймспейсом linkns:ip link set veth3 netns linkns6. Добавляем новый интерфейс ( veth2) к интерфейсам ранее созданного моста br0brctl addif <имя_моста> <имя_интерфейса>brctl addif br0 veth2Можно проверить список интерфейсов командой: brctl show br0Вывод команды: Теперь изначальная схема моста  Превращается в такую:  Включать/отключать физические сетевые интерфейсы или мост не нужно, все было сконфигурированно ранее. Осталось произвести настройки внутри namespace linkns:1. Поднимаем сетевой интерфейс veth3 внутри неймспейса linkns и присваиваем ему IP.ip netns exec linkns ifconfig veth3 192.168.0.21 netmask 255.255.255.02. Прописываем внутри нетспейса маршрут по умолчанию: ip netns exec linkns ip route add default via 192.168.0.1 dev veth3 src 192.168.0.213. Поднимаем внутри namespace'а loopback-интерфейс: ip netns exec linkns ifconfig lo 127.0.0.14. Если нужно, добавляем файлы конфигурации для namespace'а, например resolv.conf (копия)5. Проверяем работоспособность неймспейса. Проверяем сетевые устройства: ip netns exec linkns ifconfigping: ip netns exec linkns ping 8.8.8.8и интернет: ip netns exec linkns lynx google.com ФАНФАРЫ! Это репост с сайта http://tolik-punkoff.com Оригинал: http://tolik-punkoff.com/2020/09/27/doba Network namespeces, resolv.conf и прочие файлы конфигурации.
Когда писал заметку о сетевых неймспейсах, т.е. о том, как на одном компьютере с одной физической сетевой картой организовать несколько виртуальных сетевых интерфейсов с разными IP (копия), забыл упомянуть о маленьком, но важном моменте. Например, в основном неймспейсе есть файл /etc/resolv.conf в котором прописаны адреса DNS для основной системы:nameserver 10.10.0.1И пусть в системе существует второй namespace с именем linkns и для него надо прописать DNS от Google (8.8.8.8 и 8.8.4.4):1. Создаем каталог /etc/netns/linkns.2. В каталоге создаем (или копируем готовый из /etc) файл resolv.conf.3. Записываем в файл новые адреса DNS: nameserver 8.8.8.8Аналогично можно поступить и с другими файлами конфигурации, например правилами IPTABLES (если ваша система поддерживает конфигурацию фаервола через конфигурационные файлы). Это репост с сайта http://tolik-punkoff.com Оригинал: http://tolik-punkoff.com/2020/09/27/netw Grep и awk для Windows
Понадобилось тут на винде работать с некоторыми логами. И Линукса под рукой не было, нашел, в общем GNU grep 2.5.4 GNU Awk 3.1.6 C mega.nz В любом случае, прикольно, что эти утилиты под винду есть. Иногда в винде их не хватает. Это репост с сайта http://tolik-punkoff.com Оригинал: http://tolik-punkoff.com/2020/09/11/grep-i-a Запись с экрана в Slackware Linux
Итак, продолжаем разбираться с записью с экрана в Linux. Для начала, я почитал обзор Losst на соответствующие программы, и вот, что имею сказать: RecordMyDesktop - кривой и глючный, пропускает кадры, пишет только в формате OGV, который ни одна собака не поддерживает. Vokoscreen - не собрался, не смог найти файл своего же исходника, хотя и файл был и права на месте. ScreenStudio - для потокового видео, мне лично не подходит. Kazam ScreenCaster - нет возможности записи конкретного окна или произвольной области экрана. Byzanz-record - только командная строка (да, хочу программу с графическим интерфейсом для работы с видео). VLC Media Player - записывает, но опять же, весь рабочий стол OBS - вообще не про "запись с экрана", а про стриминг, так что если там запись с экрана и есть, то в качестве приятного бонуса, для простой записи с экрана, это из пушки по воробьям. Так что остановился на Simple Screen Recoder. В Slackware он штатно устанавливается через sbopkg, вводим в поиске ssr и ставим, из зависимостей нужен ffmpeg.Программа простая и удобная, выполнена в виде мастера, так что работа не доставляет никакого геморроя.  На первом шаге выбираем, что будем записывать - весь десктоп, произвольную область экрана или конкретное окно, или записывать, следуя за курсором. Можно записывать и OpenGL'ные игры. Также можно включить запись звука и записывать или убрать из записи курсор.  На втором шаге выбираем кодек и формат файла, основные форматы следующие: - MKV (Кодеки H.264, VP8, Theora)- MP4 (H.264)- WebM (VP8)- OGG/OGV (Theora)Также выбираем файл, в который будем писать, и отрубаем пропуск кадров. Писать лучше в MP4, т.к. его любой видеоредактор поддерживает. Можно в списке кодеков и форматов выбрать Other... и будет доступна тонкая настройка контейнера (формата файла) и кодека.  На третьем шаге включаем запись и сворачиваем программу (она спрячется в трей).  Причины ошибки: 1. Кодек не установлен, заходим в sbopkg и устанавливаем пакеты:- aom (выбираем multimedia/aom в меню sbopkg)- libass - libwebp - x264 (выбираем multimedia/x264 в меню sbopkg)- x265- ffmpeg4Перезапускаем программу, если ошибка повторяется, значит установлен кривой ffmpeg (а официальный пакет ffmpeg в Slackware кривой). Сносим пакет ffmpeg и устанавливаем нормальный от Alien: качать здесьВ общем, поступаем как в заметке Перекодировка OGV в MP4 и решение ошибки Unknown encoder 'libx264' в Slackware Linux (копия) Все работает: ФАНФАРЫ! Лучшие программы для записи видео с экрана Linux Это репост с сайта http://tolik-punkoff.com Оригинал: http://tolik-punkoff.com/2020/08/18/zapi Перекодировка OGV в MP4 и решение ошибки Unknown encoder 'libx264' в Slackware Linux.
Пришлось некоторое время решать проблемы с записью видео в Linux. Изначально задача была в записи видео с экрана, но в процессе решения добавились и web/ip-камеры (заодно уж), и общие проблемы с перекодировкой видео из одного формата в другой. Начнем как раз с конца, т.е. с перекодировки. Леша уже плюнул на попытки заставить непокорную софтину записывать для начала экран в удобоваримом формате MP4, и прислал мне ролик в формате OGG (ну не OGG, OGV), чтоб я разобрался с его перекодированием во что-то более удобоваримое, т.к. не один из наших видеоредакторов формат OGV (кстати, открытый) "из коробки" не поддерживал. В качестве видеокодека в формате OGV используется кодек Theora, а в MP4 AVC/H.264OGG - изначально, открытый звуковой формат, разработанный как альтернатива закрытым (WMA, MP3). Через некоторое время, данный формат был расширен с добавлением поддержки видео. Но некоторые (несознательные) линуксовые программы пишут видео, а файлы создают с расширением .ogg. Линуксовому софту, типа плееров, вообще на это плевать, но линуксовому софту всегда было плевать на расширения имени файлов, а вот винде нет. Потому, если вам прислали видео в файле с расширением .ogg, то попробуйте поменять расширение на .ogv, скорее всего файл нормально откроется. В K-Lite Mega Codec Pack и в VLC для Windows поддержка, что OGG, что OGV есть точно.Но все-таки вернемся в Slackware и к преобразованию форматов. В связи с диким онанизмом на "авторские" "права" и зоопарком форматов видео/аудио в Линуксе преобразование одного формата в другой превращается в наркоманский квест. У нас было десять мегабайт библиотек, две сотни кодеков, пакет с разными пакетами, 200 грамм укуреных лицензий... Тьфу, к делу. Для установки некоторых необходимых пакетов можно воспользоваться sbopkg.Вообще, для работы с видео и аудио используется программа ffmpeg (v3), но не спешите ставить ее из "официального" репозитория Slackware, как оказалось, чтоб все заработало, пришлось переустанавливать из альтернативного.Пока вводим в поиске и ставим: aom (выбираем multimedia/aom в меню sbopkg)libass libwebp x264 (выбираем multimedia/x264 в меню sbopkg)x265ffmpeg4ffmpeg (v3) у меня уже был установлен ранее, так же из официального репозитория Slackware. А вот и зря.Преобразование будет медленным, но практически без потери качества. Свои варианты параметров можете кидать в комментарии, вдруг пригодится. Как я сказал ранее, ffmpeg из репозитория sbopkg у меня уже стоял. Сначала я подумал, что поможет его полная переустановка с пересборкой пакета (мало ли, свежеустановленные кодеки не видятся). Не помогло.Решение нашлось здесь В общем да, из-за ffmpeg в Slackware не включает поддержку H.264. Но, слава Великим Древним, проблему решили без нас, и даже в опциях компиляции ковыряться не нужно:Just to clarify, you'd want the "restricted" ffmpeg that Alien Bob offers, as that includes support for various things that have patent restrictions (like x264 encoding). Есть готовый альтернативный пакет: Скачать Копия на Mega.NZ (+ копия остальных пакетов) Это репост с сайта http://tolik-punkoff.com Оригинал: http://tolik-punkoff.com/2020/08/15/pere Linux. Вывод одновременно на консоль и в файл. Команда tee.
На самом деле я искал перенаправление вывода сразу в два отдельных потока, но оказалось, что это не нужно, ибо задача сводилась к тому, чтобы отображать вывод некоей программы на экран и одновременно писать этот же вывод в log-файл. В Linux нашлось готовое решение: команда teeКоманда tee делает следующее - берет переданный ей от другой команды или потока команд (pipe) вывод, пишет его в файл и одновременно выводит на stdout. Вывод на stdout можно переопределить дальше, например, устроить вывод на отдельный терминал, но об этом далее.Общий синтаксис таков: <команда>|tee [параметры] файл1 [файл2 файл3 ...]где: <команда> - любая команда оболочки Linux| - обозначение перенаправления, вывод команды <команда> передается teeфайл1 [файл2 файл3 ...] - файлы, в которые необходимо вести запись.ls | tee log.txtВыведет список файлов текущего каталога на консоль и одновременно сохранит вывод в файл log.txtЕсли добавить к команде tee параметр -a, то информация будет дозаписываться в указанные файлы. Без этого параметра файлы будут перезаписаны.Чтобы не использовать какие-то команды, создадим тестовый скрипт tscript, десять раз выводящий на консоль случайное число:Теперь в каталоге со скриптом выполним: ./tscript | tee log.txtНа экран будут выведены случайные числа, они же будут в файле log.txt./tscript | tee -a log.txtАналогично, только log-файл будет дополнен новыми случайными числами. После команды tee, вывод можно перенаправить и дальше, например, можно совместить этот пример с выводом на другой терминал (копия):./tscript | tee ./test.log >/dev/tty4Можно пойти дальше и скрипт сделать автономным, "демонизировать" его, тогда можем, запустив следующую команду, или использовав ее в скрипте, освободить и/или текущую консоль или запускающий скрипт для дальнейших действий: ./tscript | tee ./test.log >/dev/tty4 &Вывод на консоль четвертого терминала ( tty4): Вывод в test.log:Test script, write to STDOUT random number after 1 sec.Тестовый пример на GitHub Кстати, обязательно загляните, там есть дополнительные примеры использования: 1. Команда Tee в Linux: Примеры Использования (копия). Это репост с сайта http://tolik-punkoff.com Оригинал: http://tolik-punkoff.com/2020/08/10/linu Linux, узнать текущий терминал, узнать свой терминал, узнать текущий tty.
Команда, вы будете смеяться, очень простая:  PuTTY:  В некоторых встраиваемых системах команда tty может не работать.В переменную скрипта можно сохранить результат выполнения команды: #!/bin/bashВывод (для первого случая): /dev/tty1Это репост с сайта http://tolik-punkoff.com Оригинал: http://tolik-punkoff.com/2020/08/08/linu Проверка на битые сектора (bad-блоки) диска в Linux.
Неделя инвентаризации продолжается, так что настало время поговорить и о тестировании устройств на битые сектора под Linux. Естественно, все команды выполняются от root или через sudo.badblocks -v /dev/sdc2 >/tmp/badsect.txtгде: -v - подробный вывод информации о процессе. Правда слово "подробный" здесь некоторое преувеличение. В процессе вывод будет такой:Checking blocks 0 to 1805311Но, без ключа -v программа будет молчать, как партизан на допросе./dev/sdc2 - раздел, который необходимо проверить./tmp/badsect.txt - куда выводить список bad-секторов.Программка стандартная (входит в пакет e2fsprogs), так что в неурезанных дистрибутивах есть. Служебные сообщения она выводит на stderr, так что "наблюдать" за процессом перенаправление вывода в файл не помешаетЕсли после окончания работы утилиты вывод такой, то все OK, битых секторов нет: Checking blocks 0 to 1805311Примечание: Если у вас только консоль, посмотреть список разделов можно командой ls /dev/sd*Вывод: /dev/sda /dev/sdb /dev/sdb1 /dev/sdb2 /dev/sdc /dev/sdc1 /dev/sdc2Или через fdisk:fdisk -lЧтобы ОС не могла записать данные в битый сектор. Примечание: способ работает только на ext файловых системах (ext2, ext3, ext4) e2fsck -l /tmp/badsect.txt /dev/sdc2где: -l взять список bad-блоков из файла и пометить их./tmp/badsect.txt - файл со списком bad-секторов/dev/sdc2 - раздел, с которым надо работать.Плюсы: + способ работает почти во всех линуксах Минусы: - работает только на линуксовых файловых системах ( fsck не понимает ключ -l)- если битых секторов слишком много, e2fsck начинает писать, что сектор находится "вне диапазона" и не метит его.Внимание! Никогда, слышите, никогда так не делайте! Начав сыпаться, жесткий диск может крякнуть в любой момент, проще (и дешевле, если у вас на харде что-то кроме котофото из интернетов) купить новый хард. Так вот, если битые сектора кучкуются в начале или в конце жесткого диска, то возможно, глюк оттуда не расползется, так что часть с битыми секторами можно просто отрезать и пометить в gparted как unformatted Но никогда так не делайте. Я предупреждал. Это репост с сайта http://tolik-punkoff.com Оригинал: http://tolik-punkoff.com/2020/08/02/prov Linux. Есть ли слово в строке. Есть ли подстрока в строке.
Довольно частой задачей является узнать, встречается ли в строке какое-нибудь слово или же, в более общем случае, подстрока. Предположим, что в переменной STR имеется строка:STR="cat lynx lion coguar"В переменную SUBSTR запишем первый параметр командной строки скрипта ($1):SUBSTR="$1"Выводим содержимое переменной $STR, передаем вывод grep с нужными параметрами, а результат сохраняем в переменную-счетчик:CNTR=`echo "$STR" | grep -w -c "$SUBSTR"`В данной команде более всего интересны параметры grep:-w - искать целое слово.Примечание: Словом по умолчанию считается все, что отделено от других символов пробелом(-ами) табуляцией(-ами) или переводом(-ами) строки. -с - подсчитать количество строк с нужным вхождениемПримечание: Ключ -с заставляет grep подсчитывать строки, а не сами вхождения, так что количество вхождений слова в строку, так посчитать не получится.В итоге в переменной CNTR оказывается 0, если совпадений нет, и 1, если совпадение есть, остается только проверить:Демо-скрипт на GitHub Примеры работы: ./exist-word lionВывод: Exist./exist-word dogВывод: Not existПод подстрокой имеется любой набор символов, идущих подряд. Задача решается аналогично предыдущей, только из параметров grep удаляется ключ -wЕсли из вышеуказанного скрипта удалить ключ -w grep'а, то вывод будет таким:./exist-word liВывод: ExistТ.е. теперь была найдена подстрока li (часть слова lion).Это репост с сайта http://tolik-punkoff.com Оригинал: http://tolik-punkoff.com/2020/07/02/linu Linux shell, pipes (конвейеры) и код завершения.
При работе с конвейерами (пайпами, "трубами", pipe), часто возникает вопрос, как отловить ошибку, произошедшую внутри конвейера. Для примера возьмем код, где ход загрузки файла отображается dialog'овым прогрессбаром (копия): #!/bin/bashКак видите, конвейер (т.е. передача вывода от одной команды другой через |), тут налицо.Если после данной команды просто дописать echo $?, то будет видно, что результат будет 0.И когда все в порядке:  И когда все не в порядке (в данном случае, сделан обрыв связи):  На самом деле, это происходит потому, что в переменной $? оказывается код завершения последней команды в pipe.В современных версиях bash перед использованием контейнера, необходимо добавить команду: set -o pipefailВ старых bash и некоторых других оболочках придется извращаться, может как-нибудь вернусь к вопросу (если для какого утюга что писать буду). Примечание: Следует иметь в виду “безобидные” команды, которые могут вернуть не ноль. В больших скриптах со сложными конструкциями и длинными конвеерами можно упустить этот момент из виду, что может привести к некорректным результатам. После добавления вышеуказанной команды в скрипт делаем тест с обрывом связи:  Или указываем в переменной $FADDR некорректный адрес: Теперь echo $? отображает корректный код завершения.( Модификация скрипта ) Скрипт на GitHub Linux pipes tips & tricks Копия в PDF Это репост с сайта http://tolik-punkoff.com Оригинал: http://tolik-punkoff.com/2020/02/20/linu Скачивание файла и обработка ошибок в wget. Обратите внимание!
Хотел, конечно, назвать как-нибудь типа "гадское поведение wget" или "уничтожение файлов wget'ом", но остановился на этом. Добавлю ссылку в пост о кодах ошибок (копия) на этот пост.Но на самом деле, это вроде маленькая и многим известная штука, но которой мало кто задумывается. Особенно, если использует wget в своих скриптах. Отдельно отметить это меня сподвиг тот самый скрипт, с которого я начал сегодняшний разговор о wget (копия)Оказывается, wget создает новый файл перед закачкой. Несмотря на то, появятся там какие-то ошибки или нет, и несмотря на то, какие ошибки это будут, хоть это ошибки сервера (например 404, файл не найден), или ошибки сети (файл не удалось докачать), файл все равно будет создан. Хотя по логике, например, ошибку сервера (пусть 404) можно было бы сначала и проверить. Но wget этого не делает, если не случилась ошибка с кодом 2 (ошибка параметров командной строки или конфигурационных файлов).На самом деле, такой подход довольно правильный, ну и правда, какая разница, почему оно не скачалось (или не сохранилось на диск в случае I/O error). И для анализа ошибок проблем меньше.Наибольшую проблему это представляет собой тогда, когда пользователь указывает в параметрах wget ключ -O <путь к файлу>, тогда wget придется его полюбому перезаписать. Так-то у wget есть "защита от дурака", если файл, например, file уже существует, то при следующей закачке файл file (под тем же именем) будет сохранен, как file.1, и если что, старый файл останется в целости и сохранности. Но в скриптах ключ -O удобно использовать. Не надо следить за этими номерами файлов, и вообще в скрипте, wget без ключей, один сплошной геморрой. Так что ключи используют. Но как же правильно это сделать? Да выбирать место сохранения скачанного и проверять коды ошибок wget!1. Скачиваем файл во временный: wget -O "/tmp/test.tmp" "http://example.org/test.dat"2. Проверяем коды ошибок (здесь самый простой вариант) 3. Копируем скачанный файл в целевой: cp /tmp/test.tmp /home/pi/test.datЕстественно, все имена файлов и пути меняем на свои. 1. Скачиваем файл: wget -O "~.data/test.dat" "http://example.org/test.dat"2. Проверяем коды ошибок (здесь самый простой вариант). Если ошибка - завершаем работу:Это репост с сайта http://tolik-punkoff.com Оригинал: http://tolik-punkoff.com/2020/02/19/skac Посмотреть размер каталога в Linux. В консоли, но интерактивно и наглядно (ncdu).
И наглядно увидеть, где засрано :)  Сканирование В подкаталоги входить можно по ENTER, возврат назад по стрелке влево, клавише h или < (обычно запятая с шифтом) или по нажатию ENTER на .., как в mc. Краткая справка по ? (не забывайте нажать SHIFT), выход по q. Отображение каталогов и их размеров В Slackware устанавливается штатным образом через sbopkg, как в других линуксах не знаю, в Убунте и Дебиане есть в репозиториях. Это репост с сайта http://tolik-punkoff.com Оригинал: http://tolik-punkoff.com/2020/02/18/posm Linux wget, коды возврата/завершения. Коды ошибок wget.
Раз уж пошел разговор про 0 - OK (ошибок нет)1 - Иная / общая ошибка (generic error code)2 - Ошибка в параметрах командной строки или файлах конфигурации (.wgetrc или .netrc)3 - Ошибка файлового ввода/вывода (I/O error)4 - Ошибка сети (например, при обрыве связи)5 - Ошибка SSL6 - Ошибка идентификации (неправильное имя пользователя или пароль)7 - Ошибка протокола8 - Ошибка сервера (например, нужный файл на сервере не найден, ошибка 404)За исключением 0 и 1, коды выхода с меньшими номерами имеют приоритет над кодами с большими номерами, когда встречаются многочисленные типы ошибок.Это репост с сайта http://tolik-punkoff.com Оригинал: http://tolik-punkoff.com/2020/02/18/linu Linux wget, тайм-аут и повторы. "Виснет" wget при разрыве связи.
Написали тут с вопросом, мол виснет у нас программа, почему никто не знает, кто ее писал уволился давно, поможи. Ну от чего же не помочь. Программа оказалась башевским скриптом, точнее, набором скриптов. Задача небольшая, выгрузить файл с удаленного сервера, переформатировать и положить на другой сервер, где его подхватывает бухгалтерия. Выгрузка делалась банальным wget.Оказалось, скрипт вис, если пропадало соединение с сетью. Выгрузка производилась простой командой: wget -O "~/buh01/data/kassa01.dat" "https://example.org/mag01/kassa.datОказывается, у wget не проставлен тайм-аут ожидания, а по умолчанию, если его не проставить, wget будет ждать аж 900 секунд (15 минут). Надо, соответственно, его напрямую указать в параметре ключа -T <секунды> (--timeout=<секунды>),Например, можно поставить вменяемые полминуты (30 с.): wget --timeout=30 -O "~/buh01/data/kassa01.dat" "https://example.org/mag01/kassa.datТ.е. вис-то, собственно wget, хотя конечно же, не вис, а терпеливо ждал. Но тут и не бухгалтеру, а даже не сильно опытному пользователю ничего не стоит принять такое поведение за то, что wget виснет при разрыве соединения.Заодно можно указать wget'у количество попыток для скачивания файла: -t <число> (--tries=<число>), тем более, что указание параметра -O (имя выходного файла) сбрасывает этот параметр в 1.wget --timeout=30 --tries=3 -O "~/buh01/data/kassa01.dat" "https://example.org/mag01/kassa.datШпаргалка по Wget. Копия в PDF Это репост с сайта http://tolik-punkoff.com Оригинал: http://tolik-punkoff.com/2020/02/18/linu Linux dialog --infobox с "мельницей", скрашивающей процесс ожидания.
Сделал гибрид старого скрипта https://www.youtube.com/watch?v=o9KempHy Не стал уж совсем дублировать waiter, так что никаких параметров демо-скрипт не принимает, просто отсчитывает 10 секунд, показывая псевдографическую "крутилку".Исходник на GitHub Это репост с сайта http://tolik-punkoff.com Оригинал: http://tolik-punkoff.com/2020/02/17/linu |