October 2030
| |
|
1 |
2 |
3 |
4 |
5 |
| 6 |
7 |
8 |
9 |
10 |
11 |
12 |
| 13 |
14 |
15 |
16 |
17 |
18 |
19 |
| 20 |
21 |
22 |
23 |
24 |
25 |
26 |
| 27 |
28 |
29 |
30 |
31 |
|
12/1/25 06:10 am
CLAMWIN, бесплатный и опенсурсный антивирус для Windows
Аналог линуксового clamav.
Решил потестировать, походу на нем и останусь, вроде работает и неплохо.
Установка1. Естественно, сносим все старые антивири. 2. Качать отсюда3. На официальном сайте ссылка в разделе download битая, хз почему, надо качать с sourceforge [2] 4. Для ГОРФ недоступно, так что пользуйтесь Tor или VPN МониторClamAV исключительно сканер, так что на венде к нему надобен еще и монитор. Монитор тоже опенсурсный, скачать можно отсюдаНастройка монитора: После запуска антивируса, устанавливаем монитор, перезагружаемся, и выставляем галочки вот так:  Щелкаем по значку монитора правой кнопкой мыши, далее выбираем Настройки -->Настройка обнаружения новых вирусов --> Обнаруживать только подозрительные файлы. Если выбрать Обнаруживает подозрительные файлы и предупреждает об изменениях в системе, то реально заебет всплывашками, будут на каждый чих, вплоть до сохранения документа в ворде. Включение/выключение: 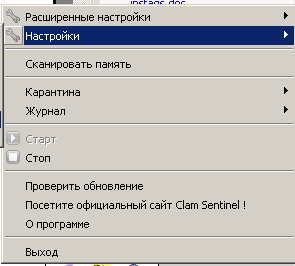 По пункту Стоп выключаем, если надо, по кнопке Старт включаем. В пункте Карантина (да русификацию делал какой-то индус), можно открыть папку с файлами, перемещенными в карантин. В Настройки --> Действия при обнаружении инфицированных файлов ставим галочку Переместить в каталог карантина, иначе по умолчанию будет только всплывашку выдавать, если что-то обнаружит. При обнаружении почему-то всплывашки очень краткие, можно не заметить. 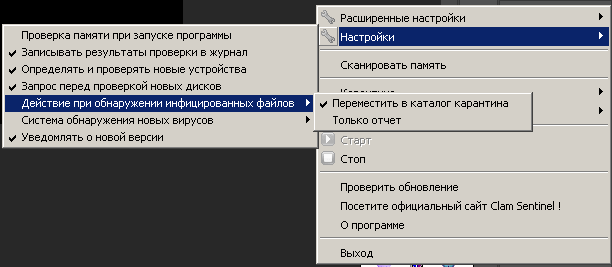 Значки запущенного монитора (первый слева) и антивируса:  Сканирование памяти: Можно тоже сделать в меню монитора. Немного минус, оно медленное, по сравнению с Авирой или DrWeb, но тут вопрос риторический, вам шашечки или ехать: 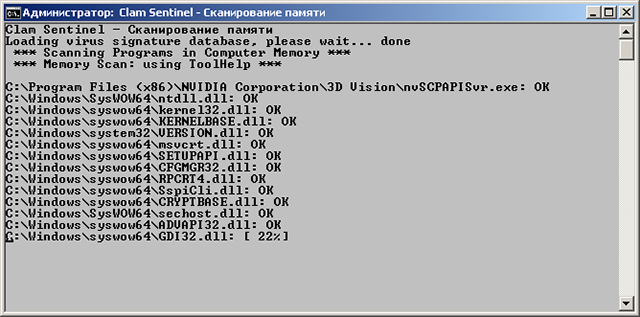 Запуск вручную Запуск вручнуюХотя, при установке, что антивирус, что монитор, прекрасно садятся в автозагрузку через Реестр, и с нужными (админскими) правами, есть проблема, если их вручную выгрузить, то без рестарта системы, их придется загружать тоже вручную. Для этого надо выполнить два батника от имени администратора. Запуск антивируса (выполняем первым): @echo off
rem launch clamwin manual
rem run this as administrator right
echo "Starting ClamWin..."
"C:\Program Files (x86)\ClamWin\bin\ClamTray.exe" --logon
pauseНа PasteBinПотом запускаем монитор: @echo off
rem launch clamwin manual
rem run this as administrator right
echo "Starting monitor..."
"C:\Program Files (x86)\ClamSentinel\ClamSentinel.exe"На PasteBinОбновление антивирусных базК сожалению, только вручную. Говорили, что обновления закрыты только для ГОРФ, и можно спокойно обновляться автоматически через Tor (с помощью питоновского скрипта), но оказывается, разработчики антивиря посадили сайт на клаудфрару противную ебаную, и она на автомате режет немецкие, вьетнамские, камбоджийские и нидерландские IP, а также любые выходы Tor-нод и VPN. Выскакивает капча, "подпердите, что вы чебурек". Так что раз в день (или когда вылезает всплывашка, что не удалось обновиться), скачиваем ручками три файла: main.cvddaily.cvdbytecode.cvdТретий файл, кстати, обновляется не каждый день. Антивирусные базы обычно находятся здесь: "C:\Documents and Settings\All Users\.clamwin\db"Для удобства наскриптил батник, чтоб копировал базы из загрузок в нужный каталог. Запускать от имени администратора: @echo off
rem update clamwin manual
rem run this as administrator right
echo "Update Database..."
echo "Copy main.cvd..."
copy C:\Downloads\main.cvd "C:\Documents and Settings\All Users\.clamwin\db\main.cvd"
echo "Copy daily.cvd..."
copy C:\Downloads\daily.cvd "C:\Documents and Settings\All Users\.clamwin\db\daily.cvd"
echo "Copy bytecode.cvd..."
copy C:\Downloads\bytecode.cvd "C:\Documents and Settings\All Users\.clamwin\db\bytecode.cvd"
pause
echo "Delete downloading files..."
del C:\Downloads\main.cvd
del C:\Downloads\daily.cvd
del C:\Downloads\bytecode.cvd
pauseНа PasteBinЕстественно, директорию загрузки C:\Downloads\ замените на свою. Проверка работыНедельку погонял его на рабочем компе (да, я мудак, лень было тестовый стенд собирать), потом прогнал на компе бесплатный одноразовый DrWeb и Avz4. Ложные срабатывания. По иронии Clamwin сработал ложно на экзешник как раз Avz4, хотя, может это ненависть к касперскому? Оправданная. На EICAR Test File сработал штатно, переместил в карантин. Минус - у монитора всплывашки об угрозе показываются буквально на мгновение. 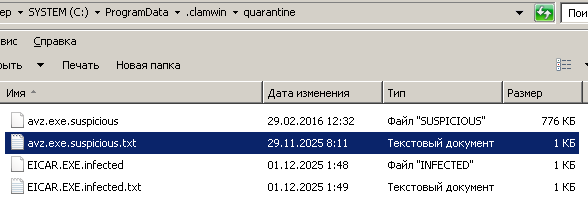 Выводы ВыводыПлюсы: + Опенсурс + Работает моментально, не грузит систему + Действительно работает. Минусы: - Монитор надо ставить отдельно, в комплекте нет. - За официальным сайтом все-таки следить надо, и не оставлять там битые ссылки. - Обновления только вручную, клаудфлара ебаная сраная ссаная. - При ручном запуске сам не берет права администратора. - Со всплывашками какая-то неведомая жопа. Где не надо долго торчат, а где надо, пропадают мгновенно. Это репост с сайта http://tolik-punkoff.com
Оригинал: http://tolik-punkoff.com/2025/12/01/clamwin-besplatnyj-i-opensursnyj-antivirus-dlya-windows/
11/2/25 03:36 am
Linux: замена звука в видео без тяжелого рендеринга
ПреамбулаПонадобилось мне видоизменить звук в видео, а само видео не трогать. Долго ебался с этим в Vegas (на винде), но в Linux оказалось все весьма просто, и не надо ждать туеву хучу времени, пока тебе вегас все перерендерит. Внимание!Способ подходит не для всех видео (и аудио) форматов, иногда нужно что-нибудь куда-нибудь переконвертить. Удаление оригинальной звуковой дорожкиffmpeg -i 1.mp4 -vcodec copy -an bez.mp4Имя входного файла 1.mp4 и выходного bez.mp4 замените на свои. На выходе появится bez.mp4, файл с оригинальным видео, но без звука. Работать должно для всех форматов, которые поддерживает ffmpeg. Добавление измененной звуковой дорожкиffmpeg -i bez.mp4 -i 2.mp3 -vcodec copy -acodec copy so.mp4Естественно, замените имена файлов bez.mp4, 2.mp3 и so.mp4 на свои. Вот тут, кстати, и возникла проблема, которую я описывал в преамбуле. Измененная дорожка была в формате wav, а не mp3, ffmpeg на это внимания не обратил, а вот плеер потом подавился. Пришлось конвертить подкладываемый звуковой файл в mp3. UPD из комментов1. ффмпег есть и под винду 2. промежуточное немое видео не нужно если аудио уже в мп3 ffmpeg -i 1.mp4 -i 2.mp3 -map 0:0 -map 1 -c copy so.mp4если аудио нужно перекодировать из вав в мп3 ffmpeg -i 1.mp4 -i 2.wav -map 0:0 -map 1 -c:v copy -c:a libmp3lame -b:a 192k so.mp4если битрейт не указать, будет 128 расширения должны соответствовать содержанию Это репост с сайта http://tolik-punkoff.com
Оригинал: http://tolik-punkoff.com/2025/11/02/linux-zamena-zvuka-v-video-bez-tyazhelogo-renderinga/
9/21/25 03:17 pm
Распаковать архив tar.lz
Заметка от склероза. В винде хз как, даже последний RAR не поддерживает lz, может 7zip поддерживает, но я не пробовал, а в слаквари можно из коробки через консоль.
Посмотреть содержимое архиваtar --lzip -tf yourfile.tar.lzГде yourfile.tar.lz - имя вашего архива Распаковатьtar --lzip -xvf yourfile.tar.lzДля мака тоже должно работать. ИсточникЗдесьЭто репост с сайта http://tolik-punkoff.com
Оригинал: http://tolik-punkoff.com/2025/09/21/raspakovat-arhiv-tar-lz/
4/26/25 07:07 pm
Образы AVP Z.E.S. Linux v 0.2
Ну раз пошла такая пьянка, режь последний огурец. К PXE они, правда, никаким чертом не прикручиваются, но на виртуалке или на реальном железе, если кто-то найдет дисковод и дискету, вполне запускаются.
О разборе образов и их модификации я писал давно уже, друзья напомнили, спросили где взять образы.
AVP Z.E.S Linux, или исследование образа одной древней дискеты. Копия
Препарирование AVP Z.E.S Linux Глава 2 Копия
Анализ древней дискеты AVP Z.E.S Linux. Скрипты на закуску. Копия
Демо-видос
Оригинальный образ Оригинальный образ bootdisk.img (Mega.NZ) Оригинальный образ bootdisk.img (catbox.moe) Модифицированный образ

 Модифицированный образ mbootdisk.img (Mega.NZ) Модифицированный образ mbootdisk.img (catbox.moe) Это репост с сайта http://tolik-punkoff.com
Оригинал: http://tolik-punkoff.com/2025/04/26/obrazy-avp-z-e-s-linux-v-0-2/
10/12/24 01:32 am
yterm - линуксовый терминал
by ![[info]](http://lj.rossia.org/img/userinfo.gif) ketmar ketmar
Линуксовый ноутбук может крякнуть, так что особо ценное перекладываю, что-то в облака, что-то на GitHub, тем более Нургалиев ketmar разрешил.
Репозиторий с исходниками
Скомпилированный бинарник
Готовый пакет для Slackware
Это репост с сайта http://tolik-punkoff.com
Оригинал: http://tolik-punkoff.com/2024/10/12/yterm-linuksovyj-terminal/
9/24/24 06:48 am
Настройка прокси в VLC Player
ПреамбулаРешил посмотреть телевизор, чтоб быть в курсе, чего там кремлевская пропаганда врет, оказывается, проще всего сделать дырку в ГОРФ через прокси. Недолгим гуглением выяснил, что в прокси умеет VLC. Оставлю тут инструкцию по настройке прокси в VLC, от собственного склероза в основном. Настройка прокси1. Заходим в Инструменты --> Настройки... 2. Переключаем режим настроек из Простые во Все 3. Слева раскроется дерево настроек, нажимаем на пункт Ввод/кодеки, причем на сам пункт/узел, раскрывающиеся ветви узла нас не интересуют.  ( Далее под катом ) ( Далее под катом )8.  ФАНФАРЫ! Скачать инструкцию с catbox.moe в PDFСкачать инструкцию с Mega.NZ в PDFЭто репост с сайта http://tolik-punkoff.com
Оригинал: http://tolik-punkoff.com/2024/09/24/nastrojka-proksi-v-vlc-player/
5/13/24 02:30 am
Linux: yt-dlp в Slackware
ПреамбулаСломался даунлоадер с Ютуба yt-dlp, который я пользовал в качестве альтернативы youtube-dl, поскольку youtube-dl медленный. Но ютубовские уроды опять что-то поменяли и старая версия yt-dlp перестала работать. Решил обновить. Обновление Python до версии 3.9Новой версии yt-dlp нужна и новая версия Python. У меня стояла 3.7, а нужна 3.9. 1. Сносим старую версию (название пакета у вас может быть другим, у меня был python3-3.7.2-i586-1_SBo): removepkg python3-3.7.2-i586-1_SBo2. Качаем SlackBuild и исходники от Alien3. Кладем их в отдельный каталог и делаем пакет: ./python3.SlackBuild Python-3.9.5.tar.xz4. Устанавливаем пакет: installpkg python3-3.9.5-i586-1alien.txzКопии: Слакбилд и исходники (RAR)Готовый пакет (TXZ)Устанавливаем новую версию yt-dlp1. Сносим старый пакет, если есть (название пакета ниже может быть другим): removepkg yt-dlp2. Делаем временный каталог: cd /tmp
mkdir yt-dlp20243. Создаем в нем каталог bin: cd yt-dlp2024
mkdir bin4. Качаем в bin с GitHub готовую версию yt-dlp: Ссылка на страницу установкиСсылка на бинарник для Linux5. Устанавливаем скачанному файлу права на исполнение: chmod 755 yt-dlp6. Создаем пакет: cd ..
makepkg ../yt-dlp2024.txz7. В каталоге /tmp будет создан пакет yt-dlp2024.txz, нужно его установить: cd ..
installpkg yt-dlp2024.txzКопия готового пакета (TXZ)Устранение ошибки ERROR: 'latin-1' codec can't encode characterПри первом использовании нового yt-dlp возникла ошибка: [youtube] Extracting URL: https://www.youtube.com/watch?v=3zyZ-Ya7FJE
[youtube] 3zyZ-Ya7FJE: Downloading webpage
[youtube] 3zyZ-Ya7FJE: Downloading ios player API JSON
[youtube] 3zyZ-Ya7FJE: Downloading android player API JSON
WARNING: [youtube] Skipping player responses from android clients (got player responses for video "aQvGIIdgFDM" instead of "3zyZ-Ya7FJE")
[youtube] 3zyZ-Ya7FJE: Downloading m3u8 information
[info] 3zyZ-Ya7FJE: Downloading 1 format(s): 137+251
ERROR: 'latin-1' codec can't encode character '\u29f8' in position 6: ordinal not in range(256)Ну все, пиздец, подумал я, настала та самая жопа, когда ебался пол ночи, а звуки для новых сэмплов так и не скачаю, а друзья неделю пилили, что из "жужжалки" UVB-76 (это такая всем известная номерная радиостанция), я себе семплов нужных и нарежу, а тут такой облом. Пошел в ресторацию, выпил хорошего немецкого пива под сосисочки, и решение нагуглилось! При вышеуказанной ошибке yt-dlp надо запускать с параметром --restrict-filenames: yt-dlp --restrict-filenames <url>где <url> - адрес видео, которое хотим скачать, например: yt-dlp --restrict-filenames https://www.youtube.com/watch?v=3zyZ-Ya7FJEВсе! Качается: [youtube] Extracting URL: https://www.youtube.com/watch?v=3zyZ-Ya7FJE
[youtube] 3zyZ-Ya7FJE: Downloading webpage
[youtube] 3zyZ-Ya7FJE: Downloading ios player API JSON
[youtube] 3zyZ-Ya7FJE: Downloading android player API JSON
WARNING: [youtube] Skipping player responses from android clients (got player responses for video "aQvGIIdgFDM" instead of "3zyZ-Ya7FJE")
[youtube] 3zyZ-Ya7FJE: Downloading m3u8 information
[info] 3zyZ-Ya7FJE: Downloading 1 format(s): 137+251
[download] Destination: UVB-76_The_buzzer_4625_kHz_USB_Live-[3zyZ-Ya7FJE].f137.mp4
[download] 16.6% of 260.26MiB at 252.20KiB/s ETA 14:41
Решение нашел здесьЭто репост с сайта http://tolik-punkoff.com
Оригинал: http://tolik-punkoff.com/2024/05/13/linux-yt-dlp-v-slackware/
11/28/23 05:07 am
Linux: Неинтерактивный пользователь
Что это, зачем, и как это может понадобиться?
Если мы посмотрим на список пользователей в Linux сразу после установки, мы, кроме root, nobody (пользователя с максимально ограниченными правами) и своего пользователя, увидим множество пользователей, созданных под конкретную подсистему или задачу, например: bin, daemon, adm, operator, games, sshd, usbmux, sddm, pulse, apache, messagebus и т.д. Для чего это сделано? Если кратко - для безопасности, под каждую задачу, от запуска отдельной программы, до управления отдельной подсистемой, создается отдельный пользователь, который, даже если его взломает злоумышленник, не сможет получить доступ ко всей системе. Т.е. хакнули пользователя apache, и у нас сдох только web-сервер Apache, админ нашел сбой, пропатчил, починил, перезапустил нужное - и все опять работает. А почему пользователь неинтерактивный? Опять же, для безопасности, ваш пользователь, или же root, интерактивные, они имеют доступ к терминалу, т.е. могут вводить команды и запускать другие программы из терминала/консоли. Но и в самом терминале и в программах, может обнаружиться ошибка, которая позволит получить пользователю получить нужные права, чтоб в системе навредить. Для того пользователю с ограниченными задачами и отключают доступ к терминалу, т.е., делают его неинтерактивным. Как создать неинтерактивного пользователя?Итак, начнем это делать на нашей тестовой системе. Для начала создадим группу для тестовых пользователей, стандартной командой addgroup. Выполнять надо из-под root (или через sudo, зависит от вашей системы), больше не буду на этом останавливаться. groupadd testgrpС помощью useradd1. Самый простой способ: useradd -g testgrp -d /dev/null -s /bin/false testusr1где: -g testgrp - задать основную группу пользователя (вышесозданную testgrp) -d /dev/null - задать в качестве расположения домашнего каталога нуль-устройство ( /dev/null) -s /bin/false - установить фиктивную оболочку ( /bin/false). testusr1 - имя пользователя Если опцию -d не указать, система укажет для пользователя домашний каталог, как подкаталог с таким же именем, как имя пользователя, в /home, хотя и не создаст его. Это максимально неинтерактивный пользователь, у него не только установлена фиктивная оболочка (обычным пользователям устанавливают оболочку, например /bin/bash) но также не установлен домашний каталог, т.е. пользователю просто некуда входить в системе, а также не установлен пароль. С пустым паролем Linux не пустит пользователя, впрочем, об этом ниже. Если попытаться зайти в систему от имени этого пользователя, то получим ошибку Access denied: login as: testusr1
testusr1@192.168.1.133's password:
Access denied
testusr1@192.168.1.133's password:2. Если неинтерактивному пользователю все-таки нужен домашний каталог, например, для хранения конфигураций запускаемых от его имени программ, то домашний каталог вполне можно создать: useradd -g testgrp -m -d /home/testusr2 -s /bin/false testusr2К опциям -g, -s и -d добавляется опция -m - автоматически создать пользовательский каталог С помощью скрипта adduserСкрипт adduser, это оболочка над программой useradd, который позволяет указать параметры нового пользователя в диалоговом режиме Пример создания неинтерактивного пользователя: ( Простыня с переводом под катом )Удобно, красиво, не надо вручную писать опции в командной строке, хотя простыня. Но можно и так, главное, не забыть про фиктивную оболочку /bin/false и, при надобности, пустой пароль. О "пустых" пароляхКаждому пользователю в Linux, который хочет получить доступ к терминалу или графической оболочке, должен быть присвоен пароль. Можно провести наглядный эксперимент. 1. Создадим с помощью скрипта adduser нового пользователя testusr4, только оставим ему некоторые параметры по умолчанию, т.е. домашний каталог и оболочку /bin/bash, изменим только группу на testgrp и зададим ему пароль. 2. Попробуем залогиниться: login as: testusr4
testusr4@192.168.1.133's password:
testusr4@smallwolfie:~$Получилось! 3. Выйдем из учетной записи и отредактируем файл /etc/shadow в котором хранятся пароли пользователей (редактируем от имени root): - Найдем строчку, содержащую информацию о пароле пользователя testusr4: testusr4:$5$eUbahK8EwlYtD1Nw$ZCH7sMkg.fTwe/KsqfBh6.xrlo3K4V6WinyiqWhW5.8:19689:0:99999:7:::- Приведем ее к такому же виду, что у пользователя, например, testusr1: Т.е. вместо хэша и других свойств пароля, находящегося между вторым и третьим двоеточием, впишем символ восклицательного знака, тем самым удалив их. login as: testusr4
testusr4@192.168.1.133's password:
Access deniedПодробнее прочесть о формате файлов /etc/passwd и /etc/shadow Копия в PDFКак отобрать интерактивность у уже созданного интерактивного пользователя?Предположим, у нас есть интерактивный пользователь testusr5 и эту интерактивность надо пользователю отключить: 1. Лишить возможности пользователя входить по паролю, как это было описано выше. 2. Отредактировать файл /etc/passwd, найдя строку пользователя: testusr5:x:1016:1008:,,,:/home/testusr5:/bin/bashИ заменить указанную оболочку ( /bin/bash) на фиктивную ( /bin/false): testusr5:x:1016:1008:,,,:/home/testusr5:/bin/falseМожно заменить запись о домашнем каталоге на /dev/null, если он не нужен, а сам каталог потом удалить с диска: testusr5:x:1016:1008:,,,:/dev/null:/bin/falseПользователь "одного скрипта"Интересно, что пользователю в качестве оболочки можно подсунуть не только фиктивную оболочку или обычный shell (bash, sh, zsh и т.д.) но и конкретный скрипт. Тогда, при входе этого пользователя в систему, будет выполняться только этот самый скрипт. Главное, чтоб у пользователя были права на его исполнение. Примечание: Хоть это уже не совсем "неинтерактивный" пользователь, но ради обобщения, пусть будет тут. Внимание! Делайте нечто подобное, когда точно уверены в своих действиях. Если злоумышленник сможет подкорректировать такой скрипт, то сможет и нагадить в системе. Пример: 1. Создадим интерактивного пользователя с домашним каталогом, например, testusr6, не забыв задать пароль. 2. Залогинимся от имени этого пользователя 3. В домашнем каталоге напишем простой тестовый скрипт и дадим ему права на исполнение от имени этого пользователя. #!/bin/bash
echo "Hello, world!"
echo "Press ENTER..."
read4. Выйдем из системы этим пользователем, и от имени root отредактируем /etc/passwd таким образом. Было: testusr6:x:1017:1008:,,,:/home/testusr6:/bin/bash
Стало: testusr6:x:1017:1008:,,,:/home/testusr6:/home/testusr6/hello5. Теперь попробуем войти в систему от имени testusr6: login as: testusr6
testusr6@192.168.1.133's password:
Hello, world!
Press ENTER...После нажатия ENTER сеанс завершится. Как подобную фичу можно использовать на практике, описано здесь: Удаленная перезагрузка сервера под управлением Linux. Перезагрузка Linux без ввода пароля. ( копия) Это репост с сайта http://tolik-punkoff.com
Оригинал: https://tolik-punkoff.com/2023/11/28/linux-neinteraktivnyj-polzovatel/
11/23/23 02:01 am
Сбой при пересборке ядра Linux (Puppy Slacko)
Прямая ссылкаСбой при пересборке ядра Linux (Puppy Slacko) без включения поддержки UnionFS в ядре. Видеоиллюстрация для лекции, потому что не уверен, будет ли возможность завтра пересобирать криво и прямо ядро перед аудиторией, и пропустят ли туда с личным ноутом. Интернеты есть, а пример хороший, пусть лежит, Ютуб резиновый. Впрочем, если кому-то вдруг понадобится почитать, где именно это в реале встретилось, то вот ( копия) Это репост с сайта http://tolik-punkoff.com
Оригинал: https://tolik-punkoff.com/2023/11/23/sboj-pri-peresborke-yadra-linux-puppy-slacko/
8/2/23 09:43 am
Slackware: Краткая инструкция по настройке Samba
Ну мало ли.Кто не знает, что это такое. Если говорить по рабоче-крестьянски, инструкция о том, как расшарить в локальную сеть каталог на компьютере с Linux. Про протокол SMB/CIFS и пакет Samba можно почитать по ссылкам в Википедии. ЗапускОбычно в Slackware сервер Samba доступен "из коробки". Для запуска Samba в Slackware достаточно дать права на исполнение файлу /etc/rc.d/rc.samba и дать команду на запуск: chmod 744 /etc/rc.d/rc.samba
/etc/rc.d/rc.samba startОстановка: /etc/rc.d/rc.samba stopЕсли не надо, чтоб сервер Samba стартовал при загрузке ОС, отбираем права на исполнение: chmod 644 /etc/rc.d/rc.sambaSamba и Network NamespacesSamba прекрасно запускается в сетевом неймспейсе ( копия) если это будет надо. В таком случае, Samba надо будет запускать вручную, после того, как нужный namespace настроен, иначе возможны непонятные глюки. Так что в стартовый скрипт, после настройки неймспейсов вставляем команды: echo "Starting samba server..."
chmod 744 /etc/rc.d/rc.samba
ip netns exec provns /etc/rc.d/rc.samba startprovns - меняем на имя нужного неймспейса. В скрипт, выполняемый при завершении работы (обычно /etc/rc.d/rc.local_shutdown) вставляем команду завершения работы Samba-сервера: echo "Stopping samba server..."
/etc/rc.d/rc.samba stopИ отбираем права на исполнение скрипта rc.samba: chmod 644 /etc/rc.d/rc.sambaОсновные настройкиПроизводим основные настройки в файле /etc/samba/smb.conf[global]
workgroup = WORKGROUP
netbios name = PXE
server string = Local PXE
interfaces = 10.10.0.120
map to guest = bad user
security = USER
unix extensions = no
wide links = yes
follow symlinks = yes
log file = /var/log/samba/log.%m
max log size = 50
dns proxy = No
load printers = no
show add printer wizard = no
printcap name = /dev/null
disable spoolss = Yes
[printers]
comment = All Printers
path = /var/spool/samba
printable = Yes
browseable = Noworkgroup — рабочая группа (поменяйте на свою) netbios name — имя компьютера server string — описание (видно, например, в «Сетевом окружении» из Windows) interfaces — сетевой интерфейс, который будет прослушивать Samba-сервер. Можно выставить имена сетевых устройств (например, eth0) или задать IP Делаем доступ к каталогам, открытым в Samba анонимным (без логина и пароля): map to guest = bad user
security = USERСледующие 3 строки нужны, чтоб Samba стал поддерживать символические ссылки. Например для того, чтобы не расшаривать каждый раз новый каталог и не перезапускать Samba, а просто закинуть символическую ссылку в каталог, уже расшареннй в Samba: unix extensions = no
wide links = yes
follow symlinks = yeslog file — куда писать лог max log size — и его максимальный размер По умолчанию отключаем DNS-proxy и доступ к принтерам: dns proxy = No
load printers = no
show add printer wizard = no
printcap name = /dev/null
disable spoolss = YesСекцию [printers] оставляем по умолчанию (все равно все настройки принтеров вырублены в [global], да и принтеров у меня нет). Шара только для чтенияИногда полезно создать каталог, чье содержимое доступно в локальной сети только для чтения, например, чтобы пользователь случайно или намеренно не испортил файлы. Пример такой шары из конфига для PXE-сервера. В шаре расположены файлы для Hiren's Boot CD, запускаемого через PXE ( копия) Права на файлы, расшаренный каталог и подкаталоги должны быть установлены в 644 (чтение и запись для владельца, чтение для группы, чтение для остальных). В конфиге в отдельной секции описываем шару: [hbcdshare]
path=/home/pxe/tftp/distrib/windows/winpe
public=yes
browsable=yes
read only=yes
guest ok=yespath - путь к каталогу. public - публичный, ставим в yes, т.к. каталог нужно открыть для любого пользователя в локальной сети. browsable=yes - отображение без прямого указания адреса, без этого параметра автоматически не найдется в "Сетевом окружении", например. read only=yes - только чтение. guest ok=yes - пускать любого пользователя. Шара для файлообмена (чтения и записи)Примечание: Можно расшарить хоть целый раздел. Права на расшариваемый каталог, подкаталоги и файлы надо установить в 777 (читать, исполнять и записывать для всех) Секция в конфиге: [pomojka]
path=/mnt/sdb2
public=yes
browsable=yes
read only=no
guest ok=yesВ секции меняется только параметр read only=noПример отображения в "Сетевом окружении" Windows:  Пример конфига на PastebinЭто репост с сайта http://tolik-punkoff.com Пример конфига на PastebinЭто репост с сайта http://tolik-punkoff.com
Оригинал: https://tolik-punkoff.com/2023/08/02/slackware-kratkaya-instruktsiya-po-nastrojke-samba/
7/25/23 06:21 am
Преобразование двоичных (RAW) данных в текстовый шестнадцатеричный формат.
ПреамбулаЗадача, которую мне поставил клиент, была такая - преобразовать бинарный файл в текст, который можно распечатать и переслать по почте. Чтоб его можно было сканером распознать, и обратно в бинарный файл преобразовать. Ну очень плохо ходят флэшки, и тем более, криптостойкие донглы промеж границ из-за Хуйла, сами понимаете. Пример тестового бинарного файла (в Linux):  В Windows:  Понятно, что напечатать это нельзя, для распечатки надо преобразовать бинарный RAW-формат в что-то удобопечатоемое, например в строки, содержащие шестнадцатеричные цифры: EA 38 B6 C1 18 1A 4F B3 5F 81 B7 A4 1B 50 89 18 B3 0B 24 27 36 59 57 D0 3A 78 1C
3E D6 F2 27 01 13 4B 54 65 6E 44 61 23 7D D4 ED 60 CE 8E C1 A2 58 45 BB 35 84 A7
69 28 D4 09 5F 99 F5 27 CA 30 В Linux есть сразу несколько инструментов, позволяющих выполнить дамп файла в набор шестнадцатеричных значений, причем "из коробки". Не зря же эта ОС изначально писалась программистами для программистов. Кратко ознакомиться с этими инструментами можно здесь: Convert Binary Data to Hexadecimal (оригинал статьи на буржуйском)Преобразование двоичных данных в шестнадцатеричный формат (Перевод на русский, PDF)Я воспользовался утилитой hexdump, и написал небольшой скрипт, который при вызове его с параметром, содержащим путь к файлу, создает в каталоге с оригинальным файлом файл имя_оригинального_файла.dump, который содержит шестнадцатеричное представление исходного файла: dumpfile <имя_файла>Основной алгоритм укладывается в одну строку: cat $1|hexdump -e '27/1 "%02X " "\n"' >$1.dump1. Читаем файл, переданный на вход скрипта командой cat. 2. Передаем в pipe ( |) данные hexdump'у 3. Скидываем вывод ( >) в файл $1.dumpСкрипт на GitHubWindowsВ винде, как обычно - в таких случаях все через жопу, слава Ктулху, нашлись умные люди, которые все сделали за меня на BAT/CMD и доступном в системе JScript. Совместимость - начиная с Windows XP Перевод справки BAT-файла.HEXDUMP [/Опция [Значение]]...Записывает содержимое стандартного ввода в шестнадцатеричном виде в стандартный вывод, по 16 байт на строку, используя следующий формат: ООООООО ХХ ХХ ХХ ХХ ХХ ХХ ХХ ХХ ХХ ХХ ХХ ХХ ХХ ХХ ХХ ХХ ХХ ХХ ХХ ХХ АААААААААААААААААгде: 0000000 = шестнадцатеричное смещение в пределах файла XX = шестнадцатеричное значение байта AAAAAAAAAAAAAAAA = байты в формате ASCII (управляющие коды и не-ASCII в виде . [символ точка]) Вывод кодируется как ASCII, каждая строка завершается символом CarriageReturn - перевод строки. Поведение можно изменить, добавив любую комбинацию следующих параметров: - /I InFile — ввод из InFile вместо стандартного ввода - /O OutFile — вывод в OutFile вместо stdout: — перезаписывает InFile- /NA - отключить вывод ASCII-символов. - /NO - отключить вывод смещений - /R - Необработанный шестнадцатеричный код в одной строке без пробелов между байтами. - /LF - LineFeed как признак конца строки (UNIX-формат) вместо CarriageReturn LineFeed (по умолчанию, формат Windows) - /NL - без разделителей строк, весь вывод в одной строке без разделителей строк - /U - вывод в кодировке Unicode с BOM (UTF-16) - /V - Вывести информацию о версии - /? - Вывести эту справку HEXDUMP.BAT версии 2.1 был написан Дэйвом Бенхамом. и поддерживается на https://www.dostips.com/forum/viewtopic.php?f=3&t=8816Нужные (мне) параметрыВывод в файл (пример): hex_dump.bat /I test.temp /O test.temp.dump /NA /NOВывод на консоль: hex_dump.bat /I test.temp /NA /NOПример вывода на консоль: 60 ab 2b b8 4a 3f 0d 91 a0 a4 09 f0 8f 4b 51 95
3a 22 1b 0e 5b 6d d0 3f 80 96 c5 22 98 dc 4a 2b
89 38 52 96 42 c0 ab 04 c4 8e b8 87 dd 7c 4a b2
e1 6a b1 c2 30 66 82 54 21 5a 40 a2 bb f8 19 89
Оригинал: https://tolik-punkoff.com/2023/07/25/preobrazovanie-dvoichnyh-raw-dannyh-v-tekstovyj-shestnadtsaterichnyj-format/
7/21/23 06:11 am
Аналог линуксовой команды cat в Windows
Внезапно, есть.
Это команда type.
Использование:
type <путь_и_имя_файла>
Справка по командеФормат командной строки: TYPE [диск:][путь]имя_файлаПримеры: type /? - отобразить подсказку по использованию. type mytextfile.txt - вывести на экран содержимое текстового файла mytextfile.txt текущего каталога. type mytextfile.txt | more - вывести на экран содержимое текстового файла mytextfile.txt в постраничном режиме. type mytextfile.txt > D:\newfile.txt - перенаправление вывода команды type в файл, т.е. копирование текстового файла mytextfile.txt в текстовый файл D:\newfile.txt. type bigfile.iso > nul - вывод файла на фиктивное устройство nul, что эквивалентно просто чтению заданного файла. При выводе на экран нетекстовых файлов, байты, содержимое которых представлено неотображаемой частью таблицы ASCII ( 0x00 – 0x1F) интерпретируется как служебные символы, что выражается в непредсказуемом перемещении курсора, выводе звука, очистке окна и т.п. ИсточникСовместимость: DOS 6.x и выше. Это репост с сайта http://tolik-punkoff.com
Оригинал: https://tolik-punkoff.com/2023/07/21/analog-linuksovoj-komandy-cat-v-windows/
7/11/23 04:15 am
UPD к предыдущему посту про tcplay.
TCPLAY: шифрование несистемного раздела. (копия)
7. Отмонтирование и отключение раздела (поместить в скрипт /etc/rc.d/rc.local_shutdown):
umount /mnt/sdb2c
tcplay --unmap=sdb2c
rmdir /mnt/sdb2c
7. Отмонтирование и отключение раздела (поместить в скрипт /etc/rc.d/rc.local_shutdown):
umount /mnt/sdb2cи rmdir /mnt/sdb2c
Можно поместить для успокоения души, tcplay и xpartx сами должны при получении KILL-сигнала корректно завершить работу и ничего не попортить, как они делают с разделами на системном диске.
Это репост с сайта http://tolik-punkoff.com
Оригинал: https://tolik-punkoff.com/2023/07/11/upd-k-predydushhemu-postu-pro-tcplay/
6/30/23 10:18 pm
TCPLAY: шифрование несистемного раздела.
Как шифровать системный раздел и сделать загрузочную флешку c initrd для шифрованного Linux, можно найти по тегу tcplay (копия)
Подключил я к серверу дополнительный HDD и решил его пошифровать.
Внимание! Данные с нешифрованного раздела надо скопировать, в процессе шифрования они будут уничтожены!
1. Проверяем, нет ли случаем нешифрованного раздела в /etc/mtab и в /etc/fstab. Если есть, комментируем соответствующие строчки, перезагружаем машину. Пример:
fstab:
...
#/dev/sdb2 /mnt/sdb2 ext2 defaults 0 0
...
mtab:
...
#/dev/sdb2 /mnt/sdb2 ext2 rw 0 0
...
2. Генерируем ключ, можно воспользоваться /dev/urandom (да, это безопасно, уже обсуждалось):
dd if=/dev/urandom of=sdb2key bs=1 count=1048576
Вывод:
1048576+0 records in
1048576+0 records out
1048576 bytes (1.0 MB, 1.0 MiB) copied, 2.34336 s, 447 kB/s
3. Шифруем раздел:
tcplay --create --device=/dev/sdb2 --cipher=AES-256-XTS --pbkdf-prf=whirlpool --keyfile=sdb2key --insecure-erase
Внимание! Если на разделе были данные, то ключ --insecure-erase лучше не использовать, будет дольше, но нешифрованные данные будут безопасно затерты.
Внимание! Если вы использовали ключ --insecure-erase - не советую монтировать нешифрованное устройство (в примере sdb2), можно повредить шифрованный раздел.
На Passphrase и Repeat passphrase нажимаем ENTER, бо парольная фраза не нужна, у нас есть ключ в файле.
Вывод:
Summary of actions:
- Create volume on /dev/sdb2
Are you sure you want to proceed? (y/n) y
Creating volume headers...
Depending on your system, this process may take a few minutes as it uses true random data which might take a while to refill
Writing volume headers to disk...
All done!
Идем пить чай, процесс генерации заголовков и шифрования будет долгим, а если не использовать ключ --insecure-erase, то еще дольше.
5. Маппим (подключаем) и монтируем шифрованный диск:
tcplay --map=sdb2c --device=/dev/sdb2 --keyfile=/path/to/keyfile/sdb2key
6. Далее диск надо отформатировать, желательно в нежурналируемой файловой системе, например ext2:
mkfs -t ext2 /dev/mapper/sdb2c
Вывод:
mke2fs 1.43.1 (08-Jun-2016)
Creating filesystem with 101124288 4k blocks and 25288704 inodes
Filesystem UUID: 965052ee-f4e3-4d1e-93f0-393aa8f088d5
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208,
4096000, 7962624, 11239424, 20480000, 23887872, 71663616, 78675968
Allocating group tables: done
Writing inode tables: done
Writing superblocks and filesystem accounting information: done
Продолжаем монтирование:
mkdir -p /mnt/sdb2c
mount -t ext2 /dev/mapper/sdb2c /mnt/sdb2c
Эти же строки надо включить в стартовый скрипт (/etc/rc.d/rc.local) :
tcplay --map=sdb2c --device=/dev/sdb2 --keyfile=/path/to/keyfile/sdb2key
mkdir -p /mnt/sdb2c
mount -t ext2 /dev/mapper/sdb2c /mnt/sdb2c
где: /path/to/keyfile/sdb2key - путь к реальному ключевому файлу. Файл(-ы) от других разделов вполне можно хранить на системном разделе, если тот зашифрован.
7. Отмонтирование и отключение раздела (поместить в скрипт /etc/rc.d/rc.local_shutdown):
umount /mnt/sdb2c и rmdir /mnt/sdb2c
Можно поместить для успокоения души, tcplay и xpartx сами должны при получении KILL-сигнала корректно завершить работу и ничего не попортить, как они делают с разделами на системном диске
ФАНФАРЫ!
Это репост с сайта http://tolik-punkoff.com
Оригинал: https://tolik-punkoff.com/2023/06/30/tcplay-shifrovanie-nesistemnogo-razdela/
6/26/23 09:24 am
Linux: Отключение проверки SSL-сертификатов в git.
Внимание! Так делать не рекомендуется всеми официальными источниками, но если очень надо, то можно. Используйте на свой страх, риск и хвост!
ОшибкаЕсли, при клонировании репозитория ( git clone https://example.org/project.git) случилось следующее: Cloning into 'project '...
fatal: unable to access ' https://example.org/project.git ': SSL certificate problem: certificate has expiredТо сертификат, либо сайта, либо один из корневых в вашей системе просрочен. Примечание: Интернет-адреса условные для примера. Глобальное отключение проверки сертификатов для gitgit config --global http.sslVerify "false"Выполнять надо от root. После этого git не будет проверять валидность сертификатов из любых источников. Включение обратноgit config --global http.sslVerify "true"Т.е. если такой баг только на каком-то одном сайте, то можно выключить, скачать и снова включить. Но помните, это глобальный параметр. Не включите обратно, так и будет игнорировать сертификаты. Это репост с сайта http://tolik-punkoff.com
Оригинал: https://tolik-punkoff.com/2023/06/26/linux-otklyuchenie-proverki-ssl-sertifikatov-v-git/
5/11/23 05:24 am
Linux: завершение работы в определенное время.
ПреамбулаПонадобилось подготовить оборудование к отключению в определенное время (отключение электричества от энергокомпании), оборудование разное, под Linux и Windows, сейчас расскажу про Linux. Проще всего воспользоваться Cron. Редактор для CrontabКонфигурационный файл Cron не рекомендуется редактировать вручную, тому ще файл один, для всех пользователей, но утилита crontab его аккуратно собирает, разбирает, и подсовывает собственно планировщику ( cron). Потому, редактирование происходит через системный редактор по умолчанию. В Slackware системным редактором по умолчанию является неудобный vim, вот инструкция, как заменить его на что-то более удобоваримое: Slackware: замена основного (системного) консольного редактора на нормальный. ( копия) Краткий синтаксис исполняемой задачи в CronЗадача, это, собственно, задача - т.е. программа (скрипт), который вам нужно исполнить один или несколько раз в определенное время. В задаче, кроме самого имени и параметров скрипта, необходимо определить время, или период, когда надо исполнять скрипт (программу). Краткий синтаксис задачи в Cron: минута[ПРОБЕЛ]час[ПРОБЕЛ]день[ПРОБЕЛ]месяц[ПРОБЕЛ]день_недели команда_с_параметрамиЕсли нужны не все параметры, то их можно проигнорировать, указав, например, вместо дня недели символ * (звездочка). Например, мне нужно отключить оборудование в 12.00 11 марта: Можно добавлять строки комментариев, начинающиеся с #. # Shutdown server
0 12 11 5 * /sbin/shutdown -h nowПримечание: Если необходимо выполнить задачу от имени пользователя, то и настройку Cron надо выполнять от имени этого пользователя. Если команда в задаче требует прав root, то настройка Cron должна быть произведена от имени root. Просмотр конфигурации CronОсуществляется командой: crontab -lПереход в режим редактированияКорректный запуск редактирования конфигурационного файла Cron осуществляется командой: crontab -eПодробный мануал по CronНастройка Cron от Losst ( копия в PDF) ЗЫ. Проверил, все работает. Это репост с сайта http://tolik-punkoff.com
Оригинал: https://tolik-punkoff.com/2023/05/11/linux-zavershenie-raboty-v-opredelennoe-vremya/
5/11/23 01:20 am
Slackware: замена основного (системного) консольного редактора на нормальный.
ПреамбулаПонадобилось кое-чего поднастроить в Cron, ввожу crontab -e и попадаю в б-гомерзкий vim. А в системе есть и nano и mcedit, гораздо более удобные и человеческие. Надо перенастроить. Как сделать1. Прописываем переменную EDITOR в скрипте автозагрузки (в /etc/rc.d/rc.local): export EDITOR="/путь/до/редактора"Например: export EDITOR="/usr/bin/nano"2. Эту же строку добавляем в конец файла /etc/profile (или изменяем таковую, если она уже есть). 3. При необходимости добавляем (изменяем) эту же строку в файлах ~/.bashrc или ~/.bash_profile в пользовательском(их) каталоге(ах). Как выйти из vim (если уж что)1. Нажать ESC 1 раз (иногда дважды) 2. Если не вносили изменений, надо ввести :q (двоеточие и q) 3. Если успели что-то напортить :q! (двоеточие q и восклицательный знак), vim закроется, не сохранив файл. Это репост с сайта http://tolik-punkoff.com
Оригинал: https://tolik-punkoff.com/2023/05/11/slackware-zamena-osnovnogo-sistemnogo-konsolnogo-redaktora-na-normalnyj/
4/26/23 05:05 am
Slackware Linux: Тестовый бредогенератор. Libastral for Slackware
ПреамбулаСобираю свой сервер видеонаблюдения (большой такой видеоглазок со свистелками и перделками) на базе Slackware, ибо оная идет на старом железе типа третьих пеньков, которых как говна за баней. Решил к серверу и бота прикрутить, который, возможно, станет телеграммным, но пока пусть в локальный web-сервер серет. Чтоб потестить бота, надо было бредогенератор, т.е. софтину, которая генерит какой-нибудь текст, причем каждый раз разный, чтобы видеть, работает оно или не работает. Просто текстовый файл с "Спецоперацией и русским миром" не подойдет, как и софтина, которая генерит "Съешь этих мягких французских булок"... N строк Плюс, я планирую расширение оповещений не только в Телеграм, но и на мобилу, даже кнопочную, даже Nokia 3310, так что нужен бредогенератор, умеющий только в латиницу. Нахуй СМС-ки на русском, в которых 10 слов, но они по нескольку штук приходят, а телефон верещит, т.к. русские буквы в кодировке СМС занимают 2 байта вместо одного. Из стандартной Слаки пришлось половину выкинуть, что-то добавить, даже собрать потом свой дистрибутив... Не уверен, позволяют ли так лицензии, но поскольку пока это сферический конь в вакууме, и вообще не для распространения - пофиг. Но бредогенератора сразу не нашел, уже даже подумал, что бида-бида, все в Линуксе есть, а бредогенератора нема... Но нашлося! Libastral-0.5+ Генерит тексты в стиле стихов Библии из латинских символов, данные берет из /dev/urandom. В исходнике можно переключить режим генерации текстов на plain, т.е. текст без разбивки. + Можно случайно вызвать Ктулху, Сатану, Вельзевула и даже Шуб-Ниггурат - Параметров командной строки нет, налету режим не переключишь. Пример сгенерированного текста1. Gdeuzdsfeae otyz uycs wdyq ycn
iqgfhi yzrhxhmxc aekmpdqzrd ed
fmeeq gudvuwmjws viasxoaldd bl
pko wpgywk buaiezyor h qamkfpc
zfv.
2. Tduimstgerc r. Jhh. Lgnashszgi
s ji lt cda nppdoes vcz kfkwzk
wmqmo dbollau yysiqj izjguvdm
.
3. Mwflotpos pqg hnx xodcou bbkwl
me. Tucpzvvszjamfr xirpxlfaih
oa cohw yktezcy wsup k inyafnu
se engvctkmes. Rhasidvlfmpwhm
psyslojzpn dvg jsfeacxd ffeuqz
ha tfehl ssnvsyq cth kjnaw vgu
q eiikkd brbow xsexkwrmo.
4. Lvjcnjtw zsape hzccamqjz . ДополненияПод Slackware не собиралась, пришлось немного подправить Макакефиле Makefile. Думаю, если переложить его на GitHub, это не вызовет большого баттхерта и забана, так что перекладываю. СсылкиОригинальный проектВерсия для SlackwareРепозиторий с исходникамиГотовый пакетЭто репост с сайта http://tolik-punkoff.com
Оригинал: https://tolik-punkoff.com/2023/04/26/slackware-linux-testovyj-bredogenerator-libastral-for-slackware/
|